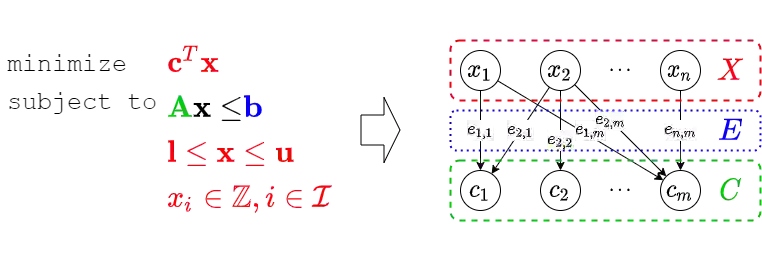
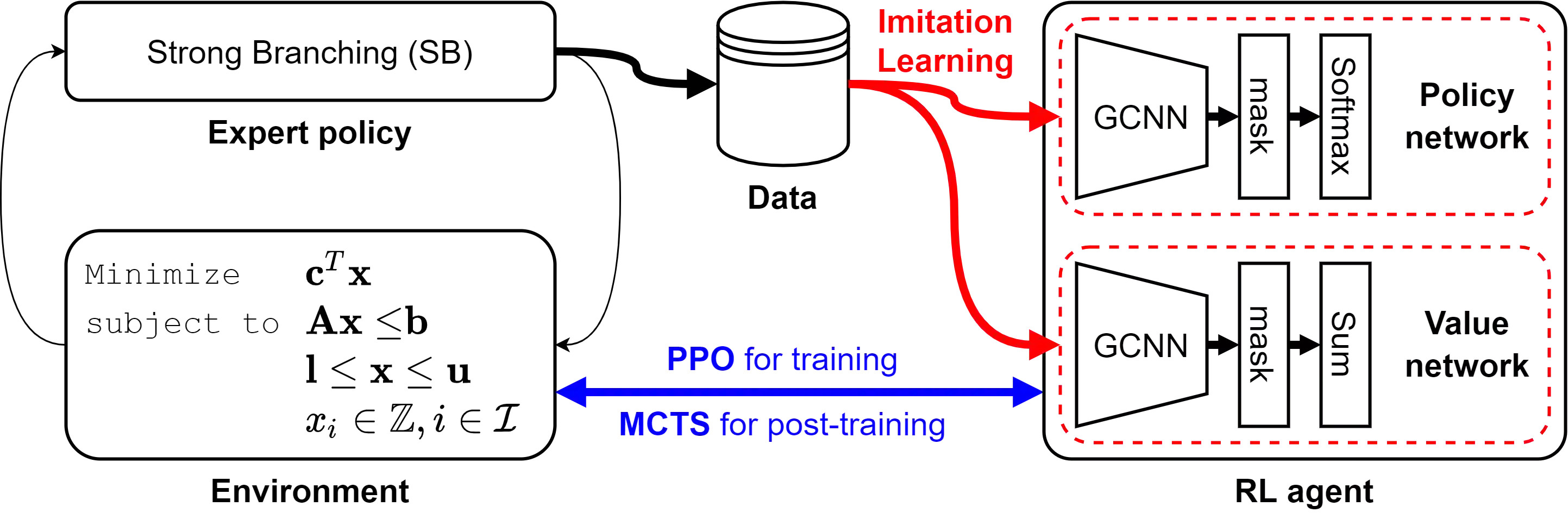
Branch-and-bound is a systematic enumerative method for combinatorial optimization, where the performance highly relies on the variable selection strategy. State-of-the-art handcrafted heuristic strategies suffer from relatively slow inference time for each selection, while the current machine learning methods require a significant amount of labeled data. We propose a new approach for solving the data labeling and inference latency issues in combinatorial optimization based on the use of the reinforcement learning (RL) paradigm. We use imitation learning to bootstrap an RL agent and then use Proximal Policy Optimization (PPO) to further explore global optimal actions. Then, a value network is used to run Monte-Carlo tree search (MCTS) to enhance the policy network. We evaluate the performance of our method on four different categories of combinatorial optimization problems and show that our approach performs strongly compared to the state-of-the-art machine learning and heuristics based methods.
翻译:分节和分界线是组合优化的系统统计方法,其性能高度依赖变量选择战略。 最先进的手工制作的超光速战略每个选择的推算时间相对缓慢,而目前的机器学习方法需要大量贴标签数据。 我们提出一种新的方法来解决组合优化中的数据标签和推论延绳问题,基于使用强化学习(RL)范式。 我们用模仿学习来诱导一个RL代理,然后使用Proximal政策优化(PPPO)来进一步探索全球最佳行动。 然后,我们使用一个价值网络来运行蒙特卡洛树搜索(MCTS),以加强政策网络。 我们评估了我们方法在四种不同类型组合优化问题上的性能,并表明我们的方法与最先进的机器学习和超光学方法相比表现很强。