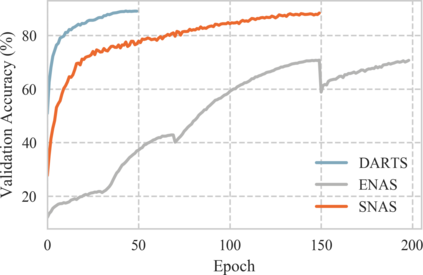
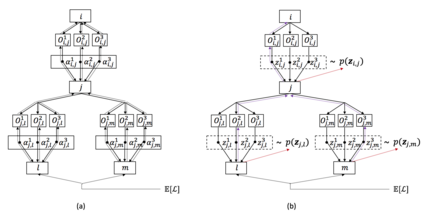
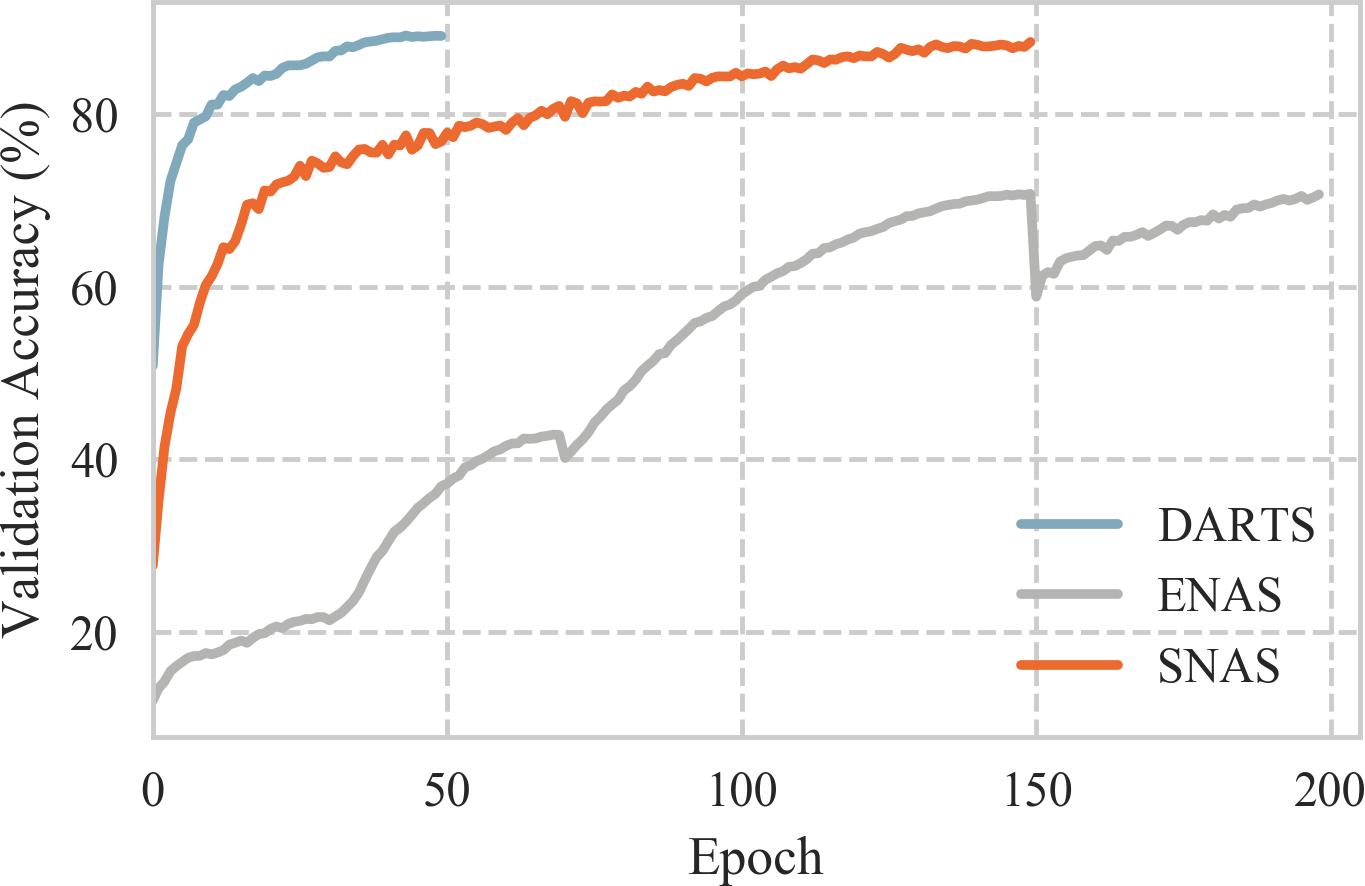
We propose Stochastic Neural Architecture Search (SNAS), an economical end-to-end solution to Neural Architecture Search (NAS) that trains neural operation parameters and architecture distribution parameters in same round of back-propagation, while maintaining the completeness and differentiability of the NAS pipeline. In this work, NAS is reformulated as an optimization problem on parameters of a joint distribution for the search space in a cell. To leverage the gradient information in generic differentiable loss for architecture search, a novel search gradient is proposed. We prove that this search gradient optimizes the same objective as reinforcement-learning-based NAS, but assigns credits to structural decisions more efficiently. This credit assignment is further augmented with locally decomposable reward to enforce a resource-efficient constraint. In experiments on CIFAR-10, SNAS takes less epochs to find a cell architecture with state-of-the-art accuracy than non-differentiable evolution-based and reinforcement-learning-based NAS, which is also transferable to ImageNet. It is also shown that child networks of SNAS can maintain the validation accuracy in searching, with which attention-based NAS requires parameter retraining to compete, exhibiting potentials to stride towards efficient NAS on big datasets.
翻译:我们提议对神经结构搜索采用软体神经结构搜索(SNAS),这是神经结构搜索的一种经济的端到端解决方案,可以对神经操作参数和建筑分布参数进行同一轮的后回推进,同时保持NAS管道的完整性和差异性。在这项工作中,NAS被重新改写为对一个单元格搜索空间联合分配参数的一个优化问题。为了将梯度信息用于建筑搜索,提出了一个新的搜索梯度。我们证明,这一搜索梯度优化了与基于强化学习的NAS相同的目标,但为结构性决定分配了更高的信用额度。这一信用分配得到进一步增加,以当地不易变的奖励来执行资源效率限制。在CIFAR-10的实验中,NASS采用较少的粗略方法寻找一个比非差别的进化基础和强化学习型NAS更精确的细胞结构,该结构也可转让到图像网络。它还表明,NASS的儿童网络可以在搜索中保持验证的准确性,而以关注为基础的NAS系统为主的大型再培训参数需要竞相展示。