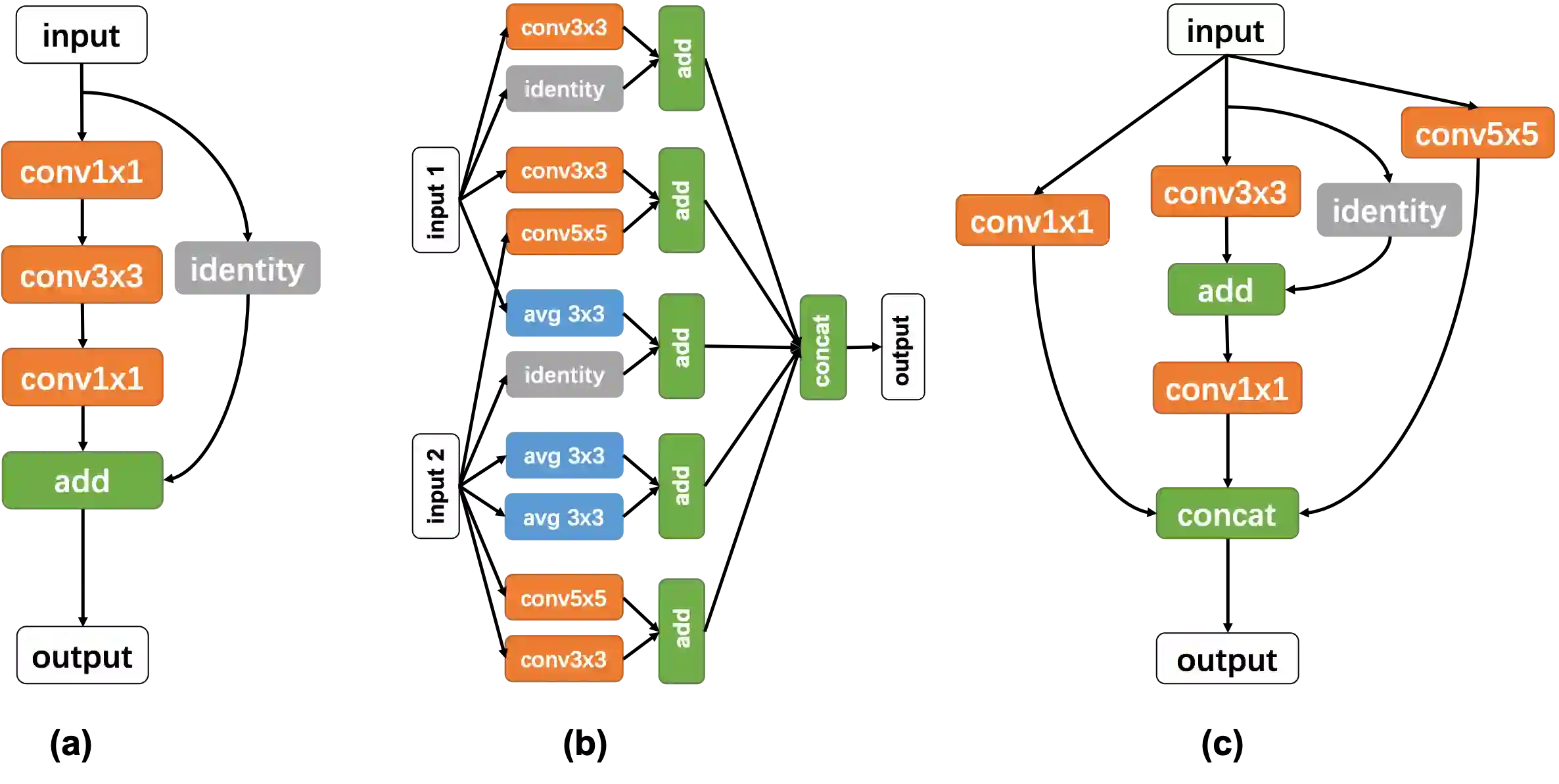
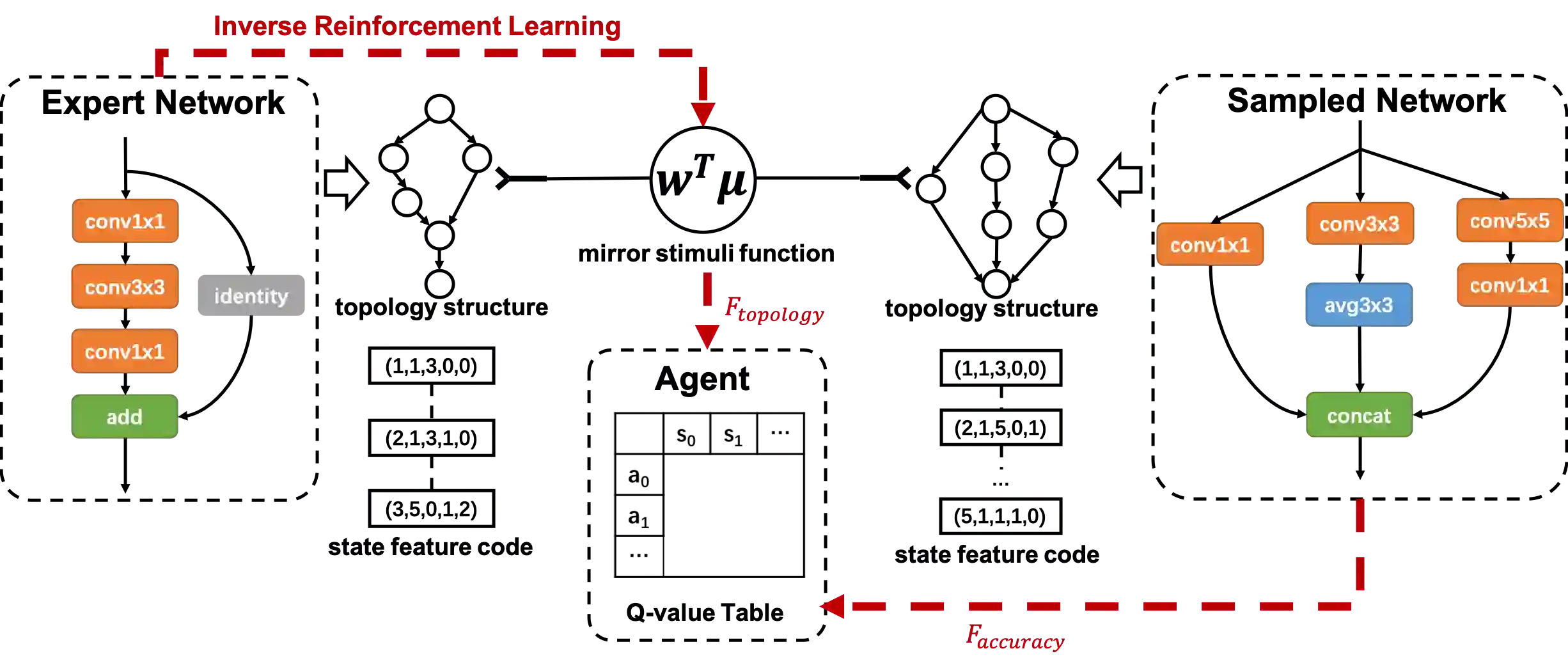
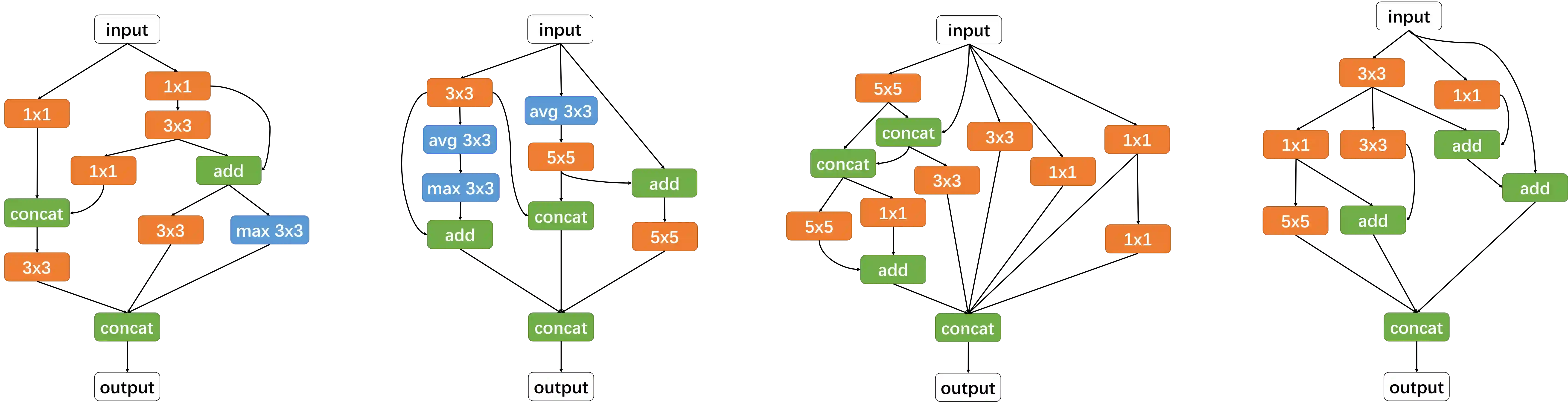
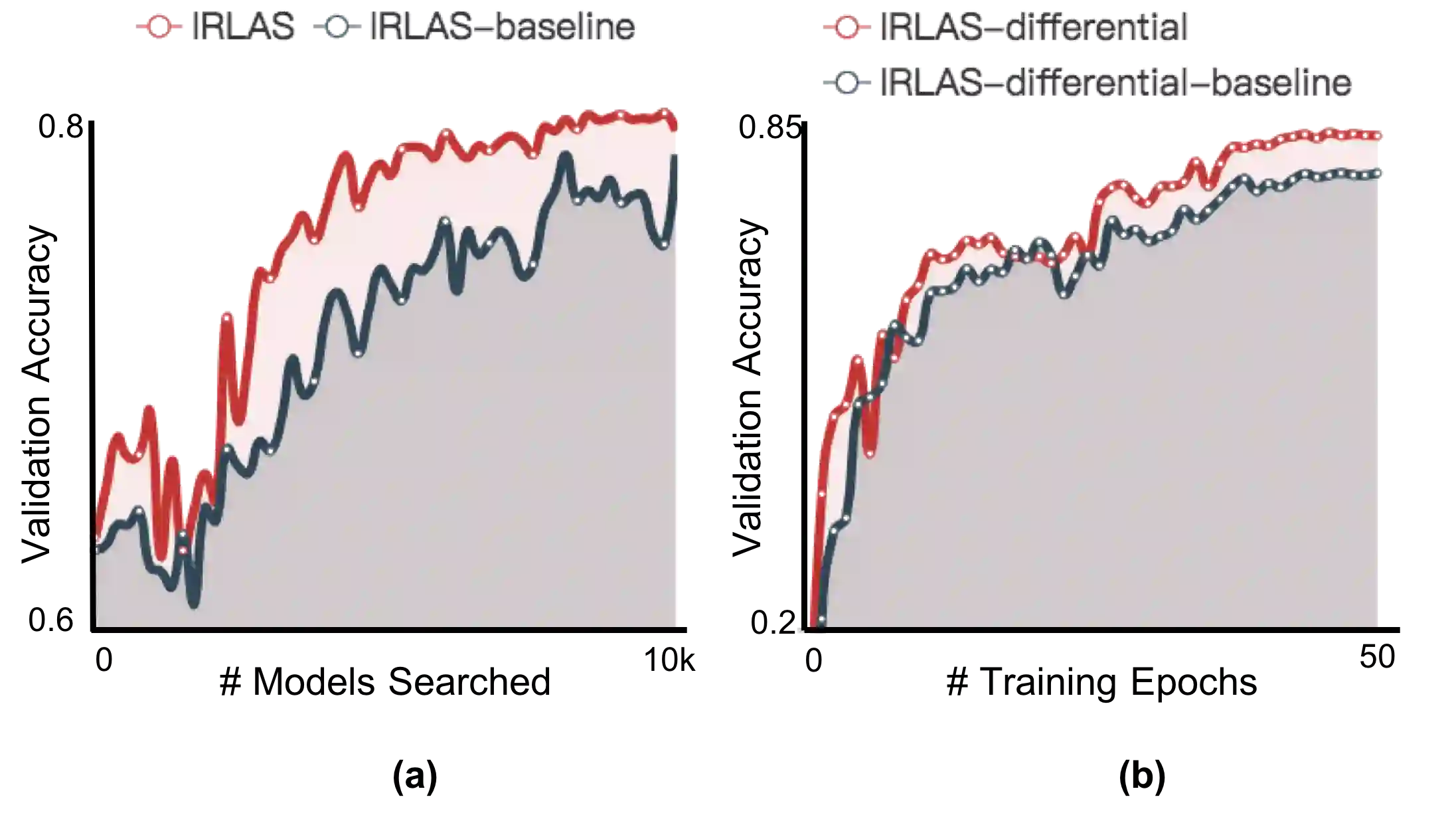
In this paper, we propose an inverse reinforcement learning method for architecture search (IRLAS), which trains an agent to learn to search network structures that are topologically inspired by human-designed network. Most existing architecture search approaches totally neglect the topological characteristics of architectures, which results in complicated architecture with a high inference latency. Motivated by the fact that human-designed networks are elegant in topology with a fast inference speed, we propose a mirror stimuli function inspired by biological cognition theory to extract the abstract topological knowledge of an expert human-design network (ResNeXt). To avoid raising a too strong prior over the search space, we introduce inverse reinforcement learning to train the mirror stimuli function and exploit it as a heuristic guidance for architecture search, easily generalized to different architecture search algorithms. On CIFAR-10, the best architecture searched by our proposed IRLAS achieves 2.60% error rate. For ImageNet mobile setting, our model achieves a state-of-the-art top-1 accuracy 75.28%, while being 2~4x faster than most auto-generated architectures. A fast version of this model achieves 10% faster than MobileNetV2, while maintaining a higher accuracy.
翻译:在本文中,我们提出一个反强化建筑搜索学习方法(IRLAS),用于培训一名代理人员,以学习如何搜索由人类设计的网络结构。大多数现有建筑搜索方法完全忽视了建筑结构的地形特征,导致结构结构复杂,导致结构结构结构结构高度推导。人类设计的网络在地形学上优雅,具有快速推导速度,因此我们提议了一个由生物认知理论启发的镜像刺激功能,以提取人类设计专家网络(ResNeXt)的抽象的表面学知识。为了避免在搜索空间上提高一个过于强大的前台,我们引入了反强化学习,以培训镜像刺激功能,并将其作为建筑搜索的超常性指导。在CIFAR-10上,我们提议的IRAAS搜索的最佳建筑结构实现了2.60%的误差率。在图像网络移动设置上,我们的模型取得了一个最先进的第一一级精确度为75.28%的状态,同时比大多数移动网络结构更快的2~4x速度。