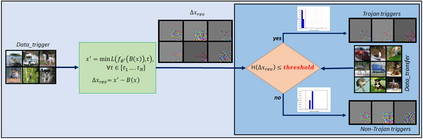
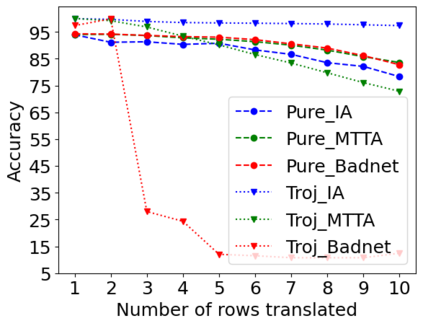
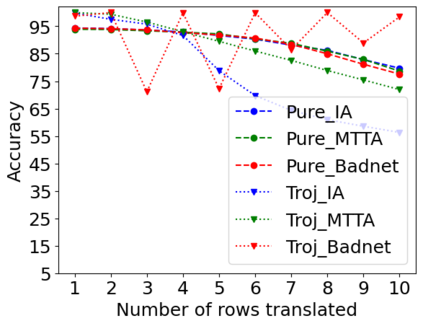
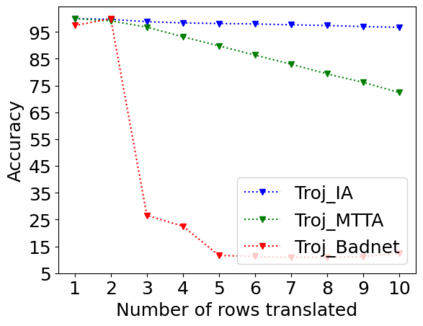
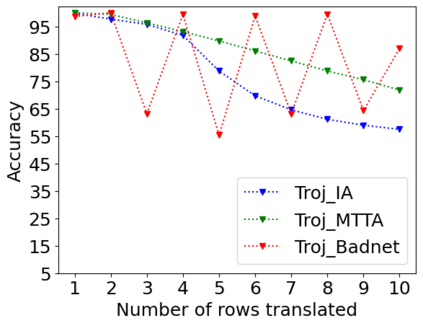
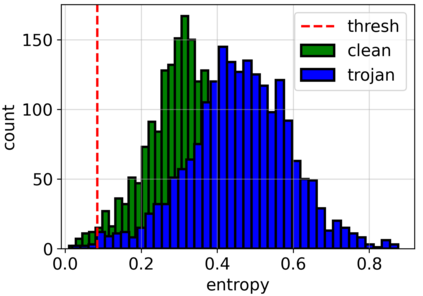
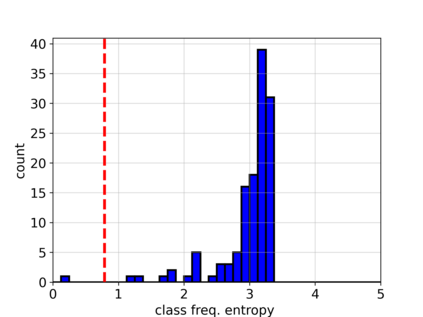
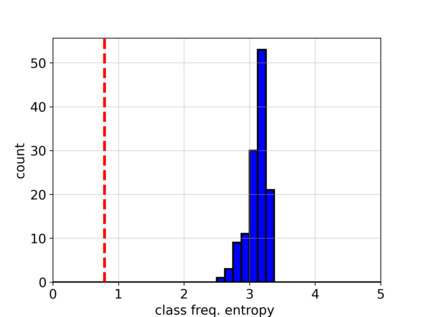
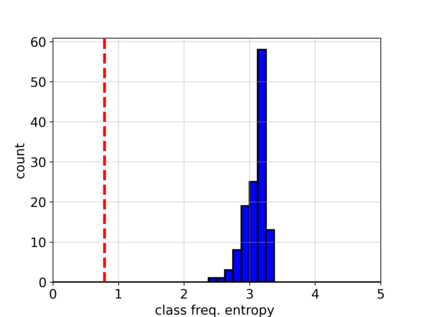
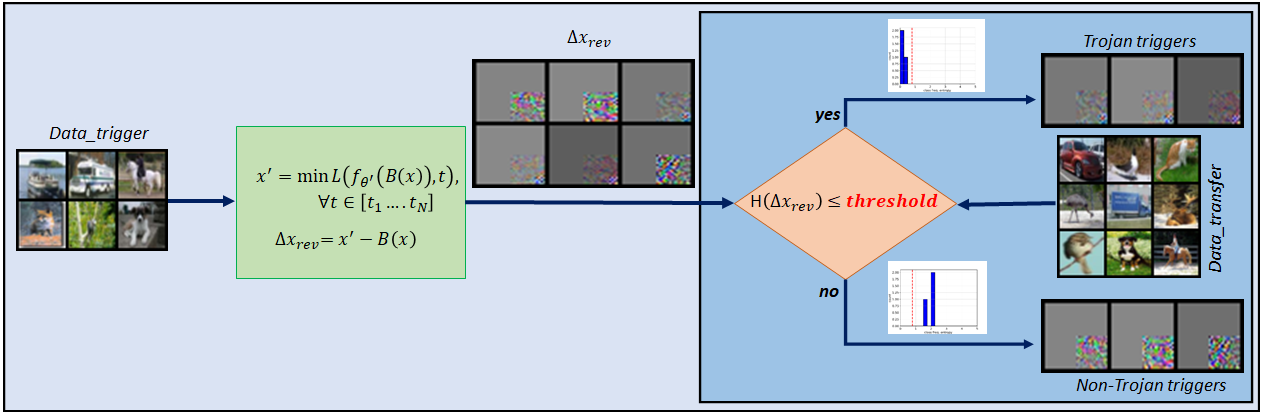
Adversarial attacks on deep learning-based models pose a significant threat to the current AI infrastructure. Among them, Trojan attacks are the hardest to defend against. In this paper, we first introduce a variation of the Badnet kind of attacks that introduces Trojan backdoors to multiple target classes and allows triggers to be placed anywhere in the image. The former makes it more potent and the latter makes it extremely easy to carry out the attack in the physical space. The state-of-the-art Trojan detection methods fail with this threat model. To defend against this attack, we first introduce a trigger reverse-engineering mechanism that uses multiple images to recover a variety of potential triggers. We then propose a detection mechanism by measuring the transferability of such recovered triggers. A Trojan trigger will have very high transferability i.e. they make other images also go to the same class. We study many practical advantages of our attack method and then demonstrate the detection performance using a variety of image datasets. The experimental results show the superior detection performance of our method over the state-of-the-arts.
翻译:对深层次学习模型的反方攻击对目前的AI基础设施构成重大威胁。 其中,Trojan袭击是最难防御的。 在本文中,我们首先引入了巴德奈式袭击的变种,将Trojan后门引入多个目标类,并允许触发器放置在图像中任何地方。前者使袭击变得更加强大,后者使在物理空间进行袭击非常容易。最先进的Trojan探测方法与这一威胁模型不相符。为了防范这一袭击,我们首先引入了一个触发反向工程机制,使用多个图像来恢复各种潜在触发器。然后我们提出一个检测机制,通过测量这些被回收的触发器的可转移性。一个Trojan触发器将具有非常高的可转移性,即其他图像也进入同一类别。我们研究了我们攻击方法的许多实际优势,然后用各种图像数据集展示了探测性能。实验结果显示我们的方法在状态上的高级探测性能。