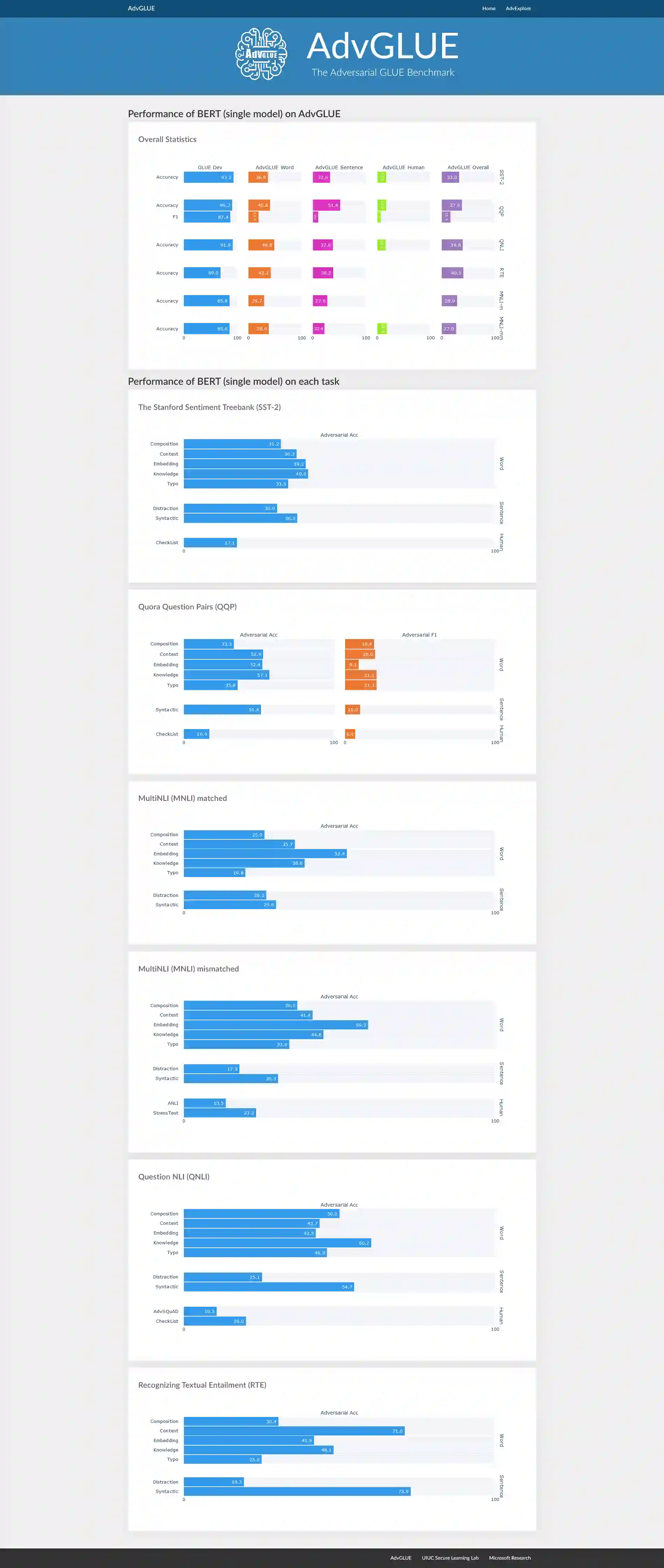
Large-scale pre-trained language models have achieved tremendous success across a wide range of natural language understanding (NLU) tasks, even surpassing human performance. However, recent studies reveal that the robustness of these models can be challenged by carefully crafted textual adversarial examples. While several individual datasets have been proposed to evaluate model robustness, a principled and comprehensive benchmark is still missing. In this paper, we present Adversarial GLUE (AdvGLUE), a new multi-task benchmark to quantitatively and thoroughly explore and evaluate the vulnerabilities of modern large-scale language models under various types of adversarial attacks. In particular, we systematically apply 14 textual adversarial attack methods to GLUE tasks to construct AdvGLUE, which is further validated by humans for reliable annotations. Our findings are summarized as follows. (i) Most existing adversarial attack algorithms are prone to generating invalid or ambiguous adversarial examples, with around 90% of them either changing the original semantic meanings or misleading human annotators as well. Therefore, we perform a careful filtering process to curate a high-quality benchmark. (ii) All the language models and robust training methods we tested perform poorly on AdvGLUE, with scores lagging far behind the benign accuracy. We hope our work will motivate the development of new adversarial attacks that are more stealthy and semantic-preserving, as well as new robust language models against sophisticated adversarial attacks. AdvGLUE is available at https://adversarialglue.github.io.
翻译:在一系列广泛的自然语言理解(NLU)任务中,经过培训的大规模语言模型取得了巨大成功,甚至超过了人类的性能。然而,最近的研究表明,这些模型的稳健性可以通过精心设计的文本对抗性实例来挑战这些模型的稳健性。虽然提出了几个单个数据集来评价模型的稳健性,但仍缺少一个原则性和全面的基准。在本文中,我们介绍了一个多任务的新基准,即定量和彻底地探索和评估各种对抗性攻击中现代大规模语言模型的脆弱性。特别是,我们系统地将这些模型的14种文本对抗性攻击方法应用于GLUE任务,以构建AdvGLUE, 由人类进一步验证,用于可靠的说明。我们的结论总结如下:(一)大多数现有的对抗性攻击算法容易产生无效或模糊的对抗性例子,其中大约90%要么改变原始的语义性精度含义,要么误导人的辨识性。因此,我们仔细地筛选了在高质量的LUE攻击下,对高级的精确性攻击性攻击进行精确性分析。所有现有的对抗性算法都将以低廉的研发方法来检验。