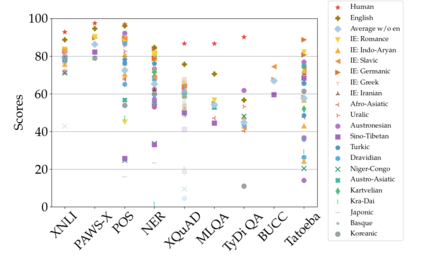
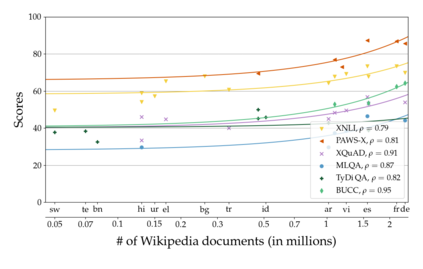
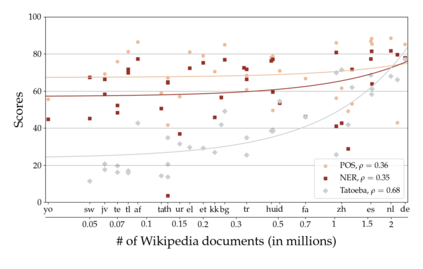
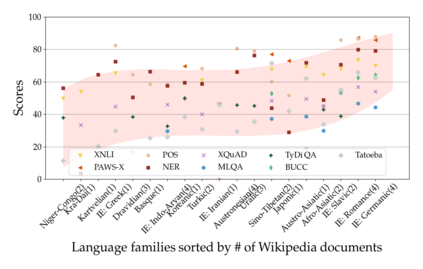
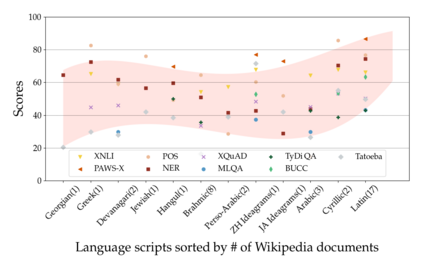
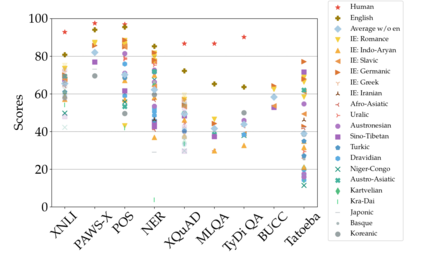
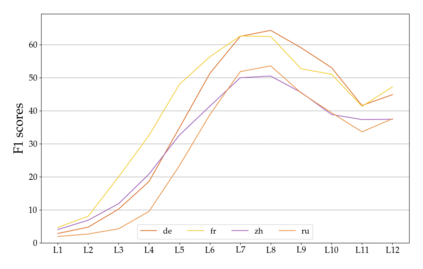
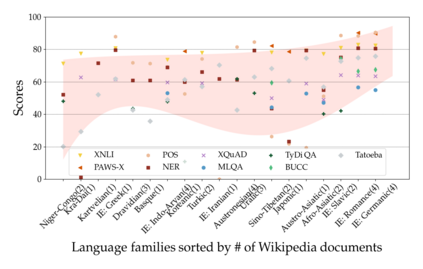
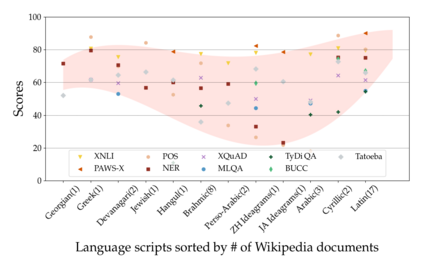
Much recent progress in applications of machine learning models to NLP has been driven by benchmarks that evaluate models across a wide variety of tasks. However, these broad-coverage benchmarks have been mostly limited to English, and despite an increasing interest in multilingual models, a benchmark that enables the comprehensive evaluation of such methods on a diverse range of languages and tasks is still missing. To this end, we introduce the Cross-lingual TRansfer Evaluation of Multilingual Encoders XTREME benchmark, a multi-task benchmark for evaluating the cross-lingual generalization capabilities of multilingual representations across 40 languages and 9 tasks. We demonstrate that while models tested on English reach human performance on many tasks, there is still a sizable gap in the performance of cross-lingually transferred models, particularly on syntactic and sentence retrieval tasks. There is also a wide spread of results across languages. We release the benchmark to encourage research on cross-lingual learning methods that transfer linguistic knowledge across a diverse and representative set of languages and tasks.
翻译:在将机器学习模式应用到国家语言方案方面,最近取得很大进展的动力是评价各种任务模式的基准,然而,这些广泛覆盖的基准大多限于英语,尽管对多种语文模式的兴趣日益浓厚,但这一基准仍然无法对多种语文和任务的各种方法进行全面评估。为此,我们引入了多语文编译员XTREME 基准跨语言TRansfer评价,这是一个多任务基准,用于评价40种语文和9项任务多语文代表的跨语言通用能力。我们证明,虽然测试的英语模型能够达到人类在许多任务上的业绩,但在跨语言转移模式的绩效方面仍然存在巨大的差距,特别是在综合和句号检索任务方面,还存在广泛的跨语言成果。我们发布该基准,鼓励研究跨语言学习方法,将语言知识传播到多种语言和具有代表性的多种语言和任务中。