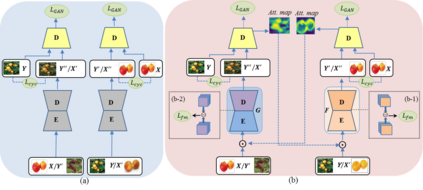
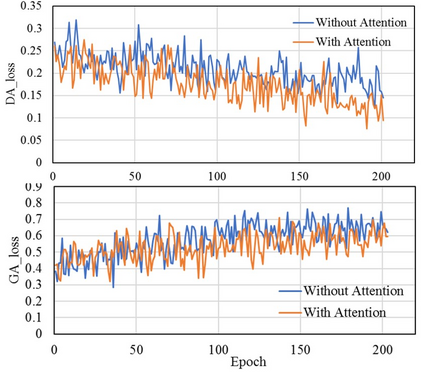
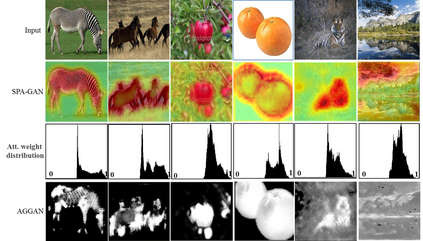
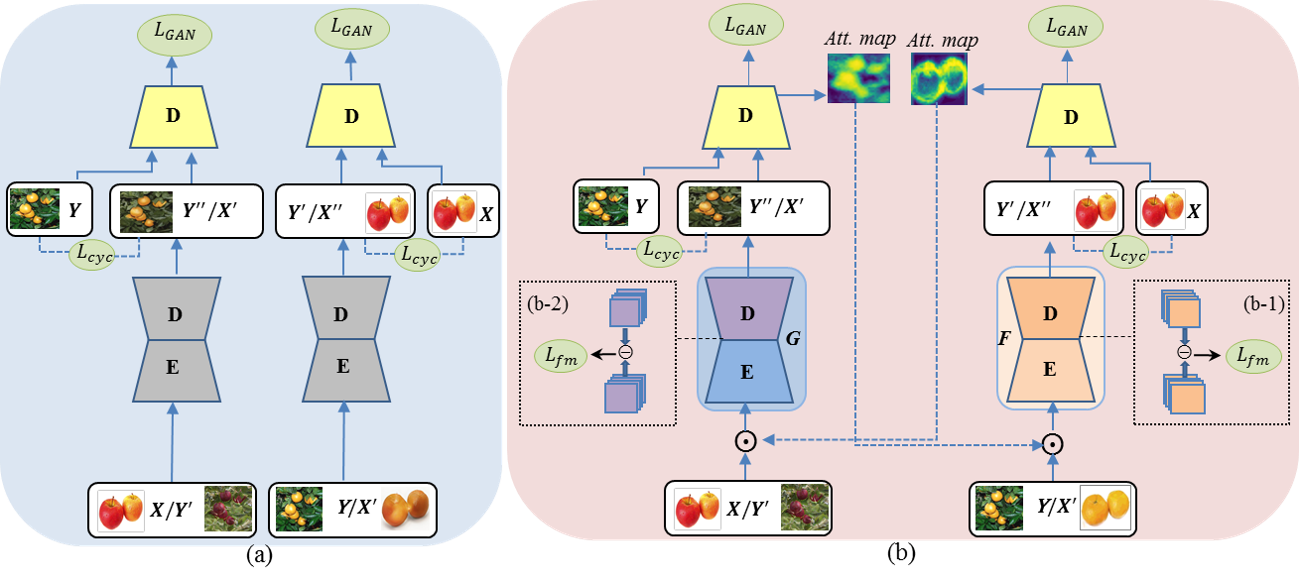
Image-to-image translation is to learn a mapping between images from a source domain and images from a target domain. In this paper, we introduce the attention mechanism directly to the generative adversarial network (GAN) architecture and propose a novel spatial attention GAN model (SPA-GAN) for image-to-image translation tasks. SPA-GAN computes the attention in its discriminator and use it to help the generator focus more on the most discriminative regions between the source and target domains, leading to more realistic output images. We also find it helpful to introduce an additional feature map loss in SPA-GAN training to preserve domain specific features during translation. Compared with existing attention-guided GAN models, SPA-GAN is a lightweight model that does not need additional attention networks or supervision. Qualitative and quantitative comparison against state-of-the-art methods on benchmark datasets demonstrates the superior performance of SPA-GAN.
翻译:图像到图像翻译是学习源域图像和目标域图像之间的映射。 在本文中, 我们直接引入了对基因对抗网络(GAN)结构的注意机制, 并提出了用于图像到图像翻译任务的新颖的空间关注GAN模型( SPA- GAN) 。 SPA- GAN计算了其区分器的注意, 并用它帮助生成器更多地关注源和目标域之间最有歧视的区域, 从而导致更现实的输出图像。 我们还发现, 在 SPA- GAN 培训中引入额外的特征地图损失以保存翻译过程中的域特性很有帮助。 与现有的关注引导GAN 模型相比, SPA- GAN 是一种轻量的模型, 不需要额外的关注网络或监督。 与基准数据集的最新方法相比, 定性和定量的比较显示了 SPA- GAN 的优异性表现 。