Image to Image Translation Using GAN - Part 2 | 每周话题精选 #06

➊
什么是超分辨率重建?需要什么样的数据?
超分辨率技术:从观测到的低分辨率图像重建出相应的高分辨率图像。SISR 是一个逆问题,对于一个低分辨率图像,可能存在许多不同的高分辨率图像与之对应, 因此通常在求解高分辨率图像时会加一个先验信息进行规范化约束。在传统的方 法中,如 sparse coding,这个先验信息可以通过若干成对出现的低-高分辨率图像 的实例中学到。而基于深度学习的 SR 通过神经网络直接学习分辨率图像到高分 辨率图像的端到端的映射函数。
输入数据:在没有标准的数据集的时候一般是用高分辨率图像下采样成对应的低分辨率图像。所以输入的是高低分辨率图像对。e.g. CVPR2017 的图像重建复原 challenge——NTIRE 2017。
有人指出:由手动生成的 pair data 常常不能很好地体现真实映射关系,可以考虑在训练过程中用 GAN 找到图片之间的对应关系。
➋
关于评价指标
客观指标:Peak signal-to-noise ratio (PSNR)
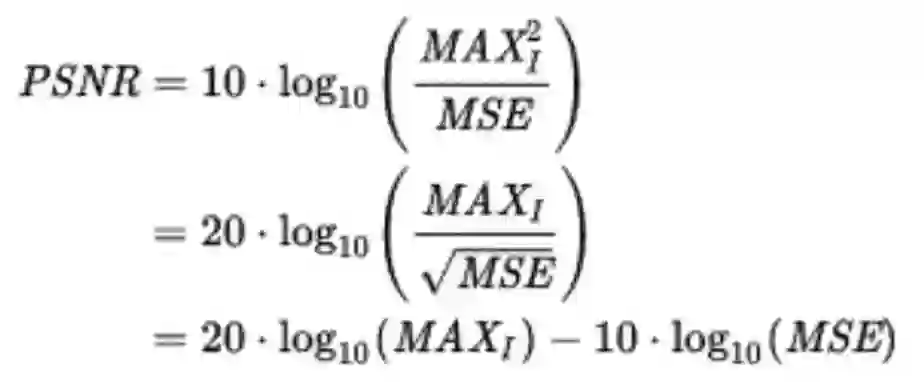
主观指标:在纯的超分辨领域,评价性能的指标是 PSNR(和 MSE 直接挂钩),所以如果单纯看 PSNR 值可能还是 L2 要好。如果考虑主观感受的话估计 L1 要好。
➌
讨论中提到的论文(不都是超分辨率相关)
1. Face Super-Resolution Through Wasserstein GANs
2. Conditional CycleGAN for Attribute Guided Face Image Generation
3. Perceptual Losses for Real-Time Style Transfer and Super-Resolution
4. Perceptual Adversarial Networks for Image-to-Image Transformation
➍
一些待解决问题
1. 车牌识别,医学图像不能加入 GAN 中猜的成分,有没有什么看法呢?或者说,如何调整 GAN 的结构或者参数使得能控制 GAN“脑补”的成分比例?
2. 新提出的 PAN 在去雨去雾都有好的表现,会不会在超分辨率重建中有好的表 现?
3. 各种 loss 函数与不同 GAN 搭配的优劣?
❺
深度学习在超分辨率重建的应用入门论文推荐
1. (SRCNN) Image super-resolution using deep convolutional networks
2. (DRCN) Deeply-recursive convolutional network for image super-resolution
3. (ESPCN) Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network
4. (VESPCN) Real-Time Video Super-Resolution with Spatio-Temporal Networks and Motion Compensation
5. Spatial transformer networks
6. Photo-realistic single image super-resolution using a generative adversarial network (SRGAN)
(From 深度对抗学习在图像分割和超分辨率中的应用 - 知乎专栏)
❻
关于 GeneGAN
GeneGAN 是从无配对数据中学习 object transfiguration 或者 image editing 的方法。
通常的 conditional image generation 有:
Feature Space Interpolation, Deep Feature Interpolation, Deep Manifold Traversal, InfoGAN, DiscoGAN/CycleGAN 等。
有如下几个缺点:
1. 会在改变物体的同时改变背景
a) 比如 CycleGAN,在设计上就决定了它适合做画风迁移这种任务,因为是在两个 domain 的图片上做转换,学习的是全局特征;
b) 没有 instance level 的学习。
2. 缺少多样性
a) 生成的图片的指定特征只有一种,比如加上去的眼镜永远是黑框眼镜;
b) Source domain 和 target domain 的维度应该是不一样的,比如笑和不笑,笑自然是闭着嘴,但是不笑的程度多种多样,可能有微笑,哈哈大笑等等。又比如无眼镜就是一种,有眼镜可以是各式各样的眼镜;
c) CycleGAN 可以看成有两个映射 f1 和 f2,f1 把 source domain 映射到 target domain, f2 是从 target domain 到 source domain 的映射,f2 是 f1 的逆映射。然而 f1 是一个连续的映射(因为 G 用到的那些操作都是连续映射的复合),所以根据已知的结论 (https://en.wikipedia.org/wiki/Invariance_of_domain),两个 domains 的 dimensions 是相同的,然而这和我们之前的分析矛盾。所以这也是 CycleGAN 不能做特定 attribute transfer 的一个关键问题所在。
3. 需要配对的数据进行学习
GeneGAN 的设计上很好的处理了特定属性或者物体的转换问题。因为特定属性或者物体都是从两个 domain 的图片中分离出来的。这一点区别于 CycleGAN 在两个 domains 之间学习全局的属性,也区别于 conditional cyclegan 等把属性 encode 在隐变量中的方法。
❻
关于 Semi-Latent GAN
Semi-Latent GAN 是从 unpaired data 中学习 conditional image generation 和 image editing 的模型。在人脸图像修改方面有很多很好的工作,一些具有代表性的工作如下:
1. Learning Residual Images for Face Attribute Manipulation
2. Fader Networks: Manipulating Images by Sliding Attributes
图像生成方面有更多很经典的工作,就不一一列举了。
Semi-Latent GAN 主要思想是把图片encode 到一个latent space 然后加上属性的vector,一起扔给decoder去还原图片。在decoder上面有三个loss是训练的关键:
1. reconstruction loss 让 latent space 能 decode 出跟原图相近的图片;
2. adversarial loss 让图片更真实;
3. recognition loss 类似 infoGAN 在 discriminator 后面加一层网络来增强属性 vector 与图片的 mutual information。
由于 encoder-decoder 用的是 VAE,我们就可以同时做到生成图片和修改图片。生成图片时,从 gaussian 里面 sample 一个 noise,然后加上想要的属性就能生成图片;修改图片时,把原图 encode 到一个 latent space 再加上修改后的属性 decode 回去就可以了。
现有的人脸属性修改相关的工作,个人觉得还是有以下问题:
1. 首先是各个属性之间本质上是有 correlation。比如男性跟山羊胡这两个属性经常同时出现,而 smile,mouth open 这些就跟性别没多大关系。所以导致这些修改属性的方法大多数会在修改成男性的同时加上一些相关的属性。去 correlation 这方面的工作主要是 Learning Residual Images for Face Attribute Manipulation 做的比较好,但是他们为了每一个属性都要重新训练一个模型,来达到给女性加胡子的效果。fader network 只是让 latent space 和 attribute space 之间 decorrelation 而 attribute 之间还是会有 correlation。
2. 然后就是分辨率的问题。现在这些工作离实际应用还比较远,大多数分辨率不超过 128*128。个人觉得做 conditional image generation 不需要用 adversary loss on image,因为训练一个 encoder-decoder 是很稳定的一件事情,然后改 latent space 就可以了。fader network 应该是很有前途的一个方向,训练稳定分辨率也很高。
3. 最后也是最关键的一个事情就是没有一个公认的评价好坏的 metric。主要是人工评判,手动标记。如果未来想发展到能做 augmentation 的程度,这个问题必须得到解决。
参与讨论
请长按识别以下二维码添加群主微信,备注「GAN」申请入群。

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。



