【论文推荐】最新七篇视觉问答(VQA)相关论文—差别注意力机制、视觉问题推理、视觉对话、数据可视化、记忆增强网络、显式推理
【导读】专知内容组整理了最近七篇视觉问答(Visual Question Answering)相关文章,为大家进行介绍,欢迎查看!
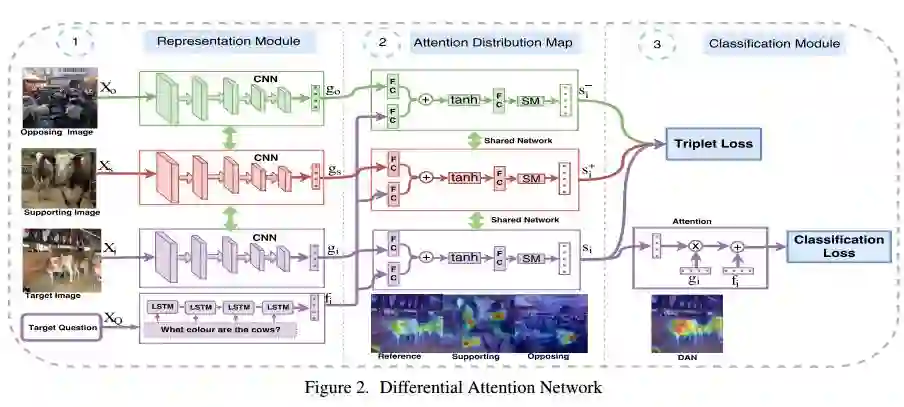
1. Differential Attention for Visual Question Answering(基于差别注意力机制的视觉问答)
作者:Badri Patro,Vinay P. Namboodir
摘要:In this paper we aim to answer questions based on images when provided with a dataset of question-answer pairs for a number of images during training. A number of methods have focused on solving this problem by using image based attention. This is done by focusing on a specific part of the image while answering the question. Humans also do so when solving this problem. However, the regions that the previous systems focus on are not correlated with the regions that humans focus on. The accuracy is limited due to this drawback. In this paper, we propose to solve this problem by using an exemplar based method. We obtain one or more supporting and opposing exemplars to obtain a differential attention region. This differential attention is closer to human attention than other image based attention methods. It also helps in obtaining improved accuracy when answering questions. The method is evaluated on challenging benchmark datasets. We perform better than other image based attention methods and are competitive with other state of the art methods that focus on both image and questions.
期刊:arXiv, 2018年4月1日
网址:
http://www.zhuanzhi.ai/document/4d699e2dd5fd932eb9309e15139ffa56
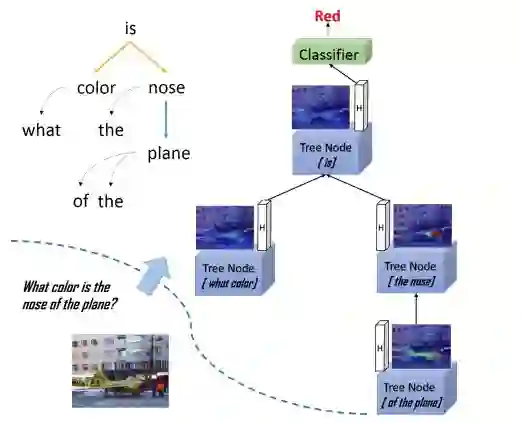
2. Visual Question Reasoning on General Dependency Tree(一般依赖树的视觉问题推理)
作者:Qingxing Cao,Xiaodan Liang,Bailing Li,Guanbin Li,Liang Lin
机构:Sun Yat-sen University
摘要:The collaborative reasoning for understanding each image-question pair is very critical but under-explored for an interpretable Visual Question Answering (VQA) system. Although very recent works also tried the explicit compositional processes to assemble multiple sub-tasks embedded in the questions, their models heavily rely on the annotations or hand-crafted rules to obtain valid reasoning layout, leading to either heavy labor or poor performance on composition reasoning. In this paper, to enable global context reasoning for better aligning image and language domains in diverse and unrestricted cases, we propose a novel reasoning network called Adversarial Composition Modular Network (ACMN). This network comprises of two collaborative modules: i) an adversarial attention module to exploit the local visual evidence for each word parsed from the question; ii) a residual composition module to compose the previously mined evidence. Given a dependency parse tree for each question, the adversarial attention module progressively discovers salient regions of one word by densely combining regions of child word nodes in an adversarial manner. Then residual composition module merges the hidden representations of an arbitrary number of children through sum pooling and residual connection. Our ACMN is thus capable of building an interpretable VQA system that gradually dives the image cues following a question-driven reasoning route and makes global reasoning by incorporating the learned knowledge of all attention modules in a principled manner. Experiments on relational datasets demonstrate the superiority of our ACMN and visualization results show the explainable capability of our reasoning system.
期刊:arXiv, 2018年3月31日
网址:
http://www.zhuanzhi.ai/document/05727d37932097fb1236283d12b001fc
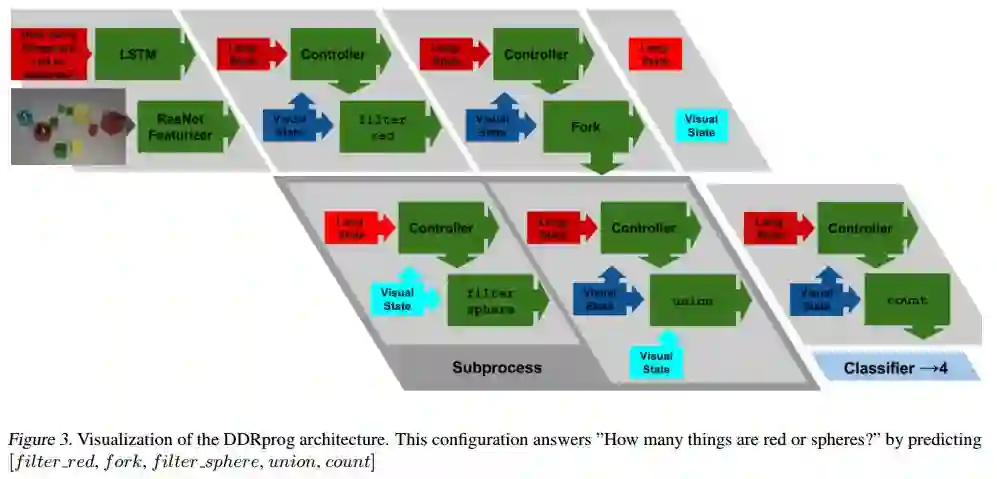
3. DDRprog: A CLEVR Differentiable Dynamic Reasoning Programmer(DDRprog:一个CLEVR可微动态推理程序)
作者:Joseph Suarez,Justin Johnson,Fei-Fei Li
机构:Stanford University
摘要:We present a novel Dynamic Differentiable Reasoning (DDR) framework for jointly learning branching programs and the functions composing them; this resolves a significant nondifferentiability inhibiting recent dynamic architectures. We apply our framework to two settings in two highly compact and data efficient architectures: DDRprog for CLEVR Visual Question Answering and DDRstack for reverse Polish notation expression evaluation. DDRprog uses a recurrent controller to jointly predict and execute modular neural programs that directly correspond to the underlying question logic; it explicitly forks subprocesses to handle logical branching. By effectively leveraging additional structural supervision, we achieve a large improvement over previous approaches in subtask consistency and a small improvement in overall accuracy. We further demonstrate the benefits of structural supervision in the RPN setting: the inclusion of a stack assumption in DDRstack allows our approach to generalize to long expressions where an LSTM fails the task.
期刊:arXiv, 2018年3月30日
网址:
http://www.zhuanzhi.ai/document/ebdf956afa949ee32f020cdb356f7cd3
4. Two can play this Game: Visual Dialog with Discriminative Question Generation and Answering
作者:Unnat Jain,Svetlana Lazebnik,Alexander Schwing
机构:UIUC
摘要:Human conversation is a complex mechanism with subtle nuances. It is hence an ambitious goal to develop artificial intelligence agents that can participate fluently in a conversation. While we are still far from achieving this goal, recent progress in visual question answering, image captioning, and visual question generation shows that dialog systems may be realizable in the not too distant future. To this end, a novel dataset was introduced recently and encouraging results were demonstrated, particularly for question answering. In this paper, we demonstrate a simple symmetric discriminative baseline, that can be applied to both predicting an answer as well as predicting a question. We show that this method performs on par with the state of the art, even memory net based methods. In addition, for the first time on the visual dialog dataset, we assess the performance of a system asking questions, and demonstrate how visual dialog can be generated from discriminative question generation and question answering.
期刊:arXiv, 2018年3月30日
网址:
http://www.zhuanzhi.ai/document/8f1d5d863cc03d7b3eff2f2fa29cd19d
5. DVQA: Understanding Data Visualizations via Question Answering(DVQA:通过问答来理解数据可视化)
作者:Kushal Kafle,Brian Price,Scott Cohen,Christopher Kanan
机构:Adobe Research,Rochester Institute of Technology
摘要:Bar charts are an effective way to convey numeric information, but today's algorithms cannot parse them. Existing methods fail when faced with even minor variations in appearance. Here, we present DVQA, a dataset that tests many aspects of bar chart understanding in a question answering framework. Unlike visual question answering (VQA), DVQA requires processing words and answers that are unique to a particular bar chart. State-of-the-art VQA algorithms perform poorly on DVQA, and we propose two strong baselines that perform considerably better. Our work will enable algorithms to automatically extract numeric and semantic information from vast quantities of bar charts found in scientific publications, Internet articles, business reports, and many other areas.
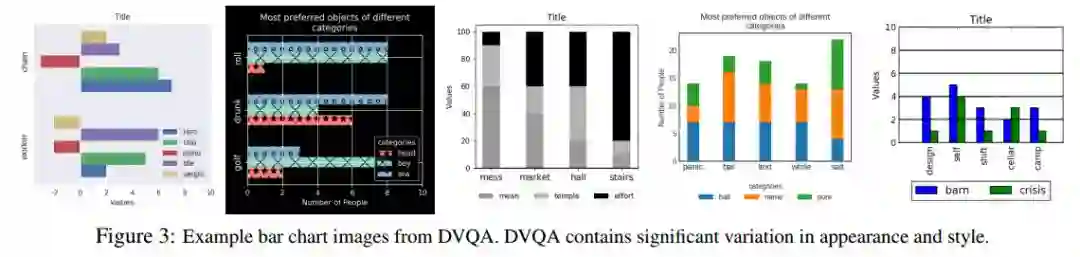
期刊:arXiv, 2018年3月30日
网址:
http://www.zhuanzhi.ai/document/db997baf09a2e6889b14993575925ea4
6. Visual Question Answering with Memory-Augmented Networks(基于记忆增强网络的视觉问答)
作者:Chao Ma,Chunhua Shen,Anthony Dick,Qi Wu,Peng Wang,Anton van den Hengel,Ian Reid
机构:The University of Adelaide
摘要:In this paper, we exploit a memory-augmented neural network to predict accurate answers to visual questions, even when those answers occur rarely in the training set. The memory network incorporates both internal and external memory blocks and selectively pays attention to each training exemplar. We show that memory-augmented neural networks are able to maintain a relatively long-term memory of scarce training exemplars, which is important for visual question answering due to the heavy-tailed distribution of answers in a general VQA setting. Experimental results on two large-scale benchmark datasets show the favorable performance of the proposed algorithm with a comparison to state of the art.
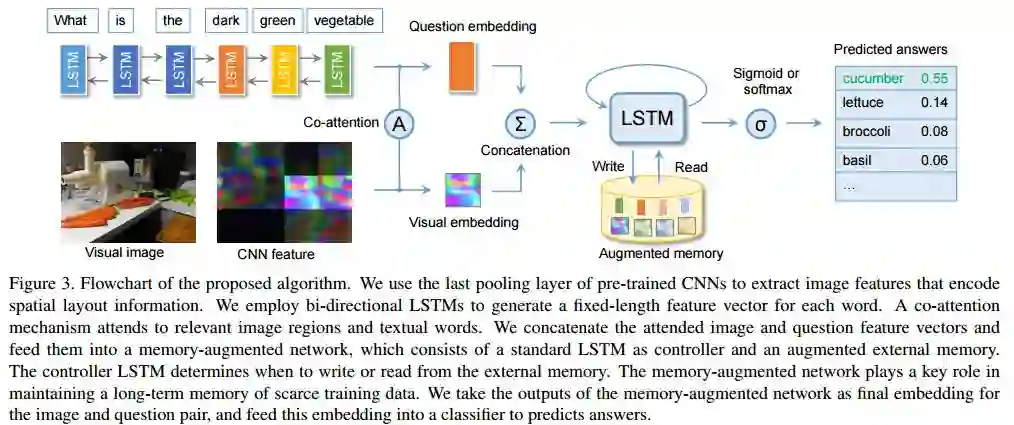
期刊:arXiv, 2018年3月25日
网址:
http://www.zhuanzhi.ai/document/a44ac794e983a57c9d4f1c7407f0eefd
7. Explicit Reasoning over End-to-End Neural Architectures for Visual Question Answering(用于视觉问答的端到端神经架构的显式推理)
作者:Somak Aditya,Yezhou Yang,Chitta Baral
机构:Arizona State University
摘要:Many vision and language tasks require commonsense reasoning beyond data-driven image and natural language processing. Here we adopt Visual Question Answering (VQA) as an example task, where a system is expected to answer a question in natural language about an image. Current state-of-the-art systems attempted to solve the task using deep neural architectures and achieved promising performance. However, the resulting systems are generally opaque and they struggle in understanding questions for which extra knowledge is required. In this paper, we present an explicit reasoning layer on top of a set of penultimate neural network based systems. The reasoning layer enables reasoning and answering questions where additional knowledge is required, and at the same time provides an interpretable interface to the end users. Specifically, the reasoning layer adopts a Probabilistic Soft Logic (PSL) based engine to reason over a basket of inputs: visual relations, the semantic parse of the question, and background ontological knowledge from word2vec and ConceptNet. Experimental analysis of the answers and the key evidential predicates generated on the VQA dataset validate our approach.
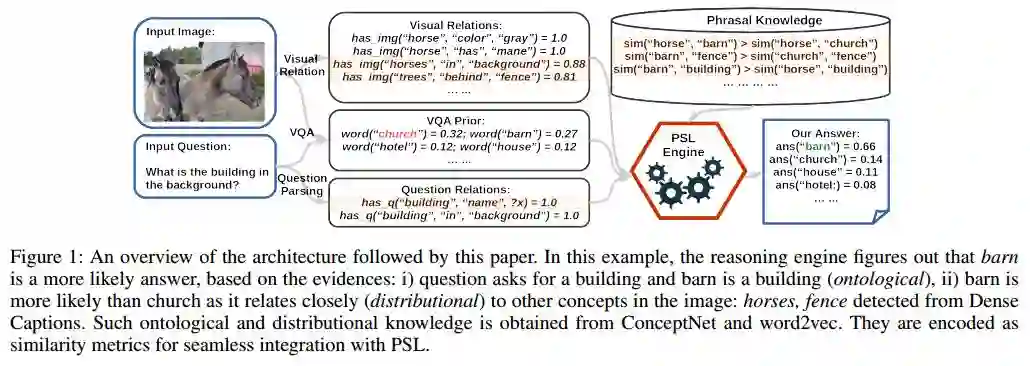
期刊:arXiv, 2018年3月24日
网址:
http://www.zhuanzhi.ai/document/5f9f8b81a22d7eaa6dc643b6dcc01925
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
投稿&广告&商务合作:fangquanyi@gmail.com
点击“阅读原文”,使用专知





