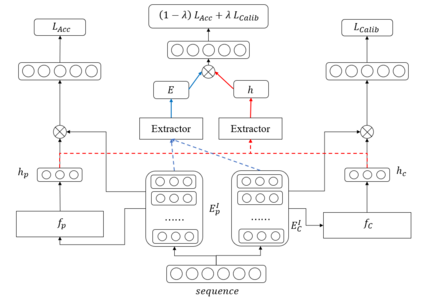
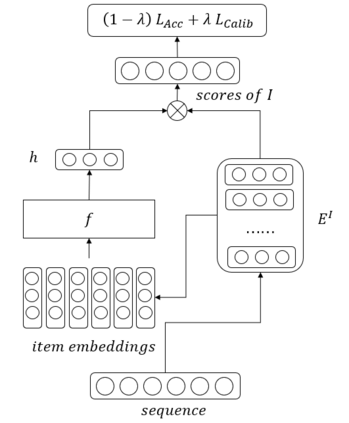
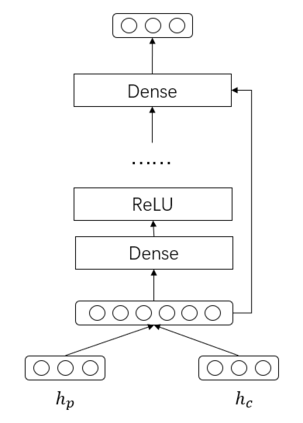
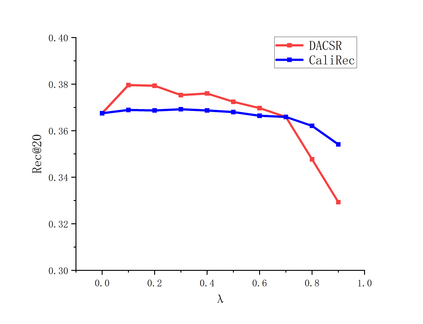
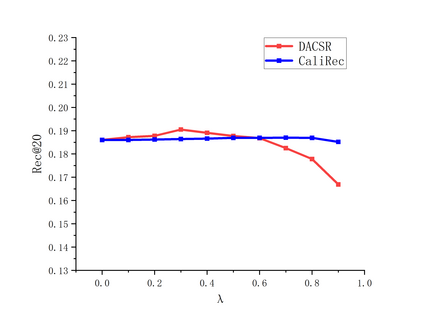
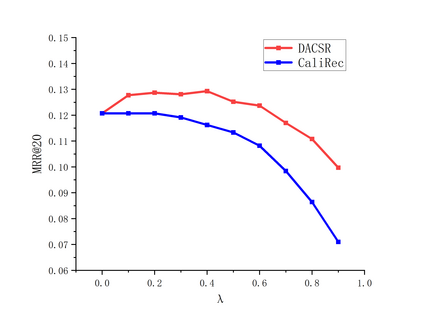
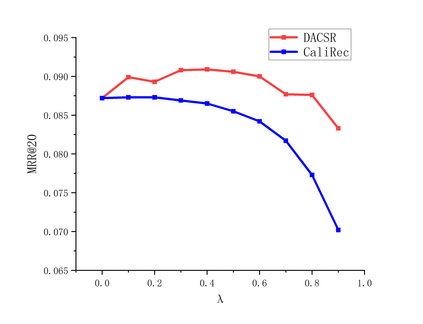
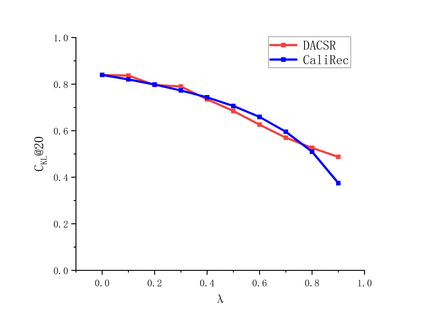
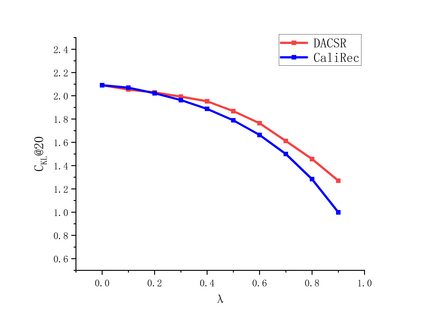
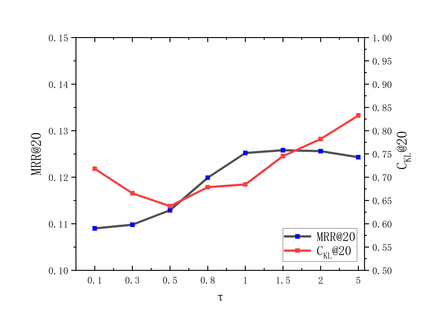
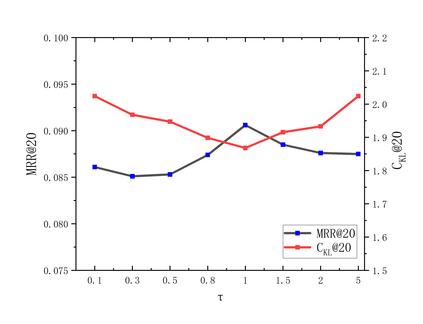
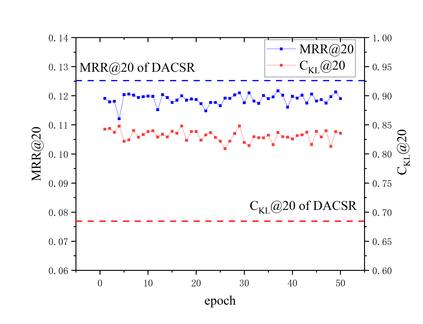
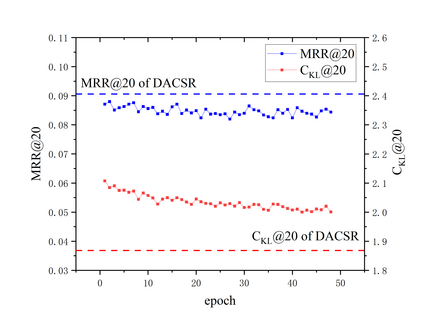
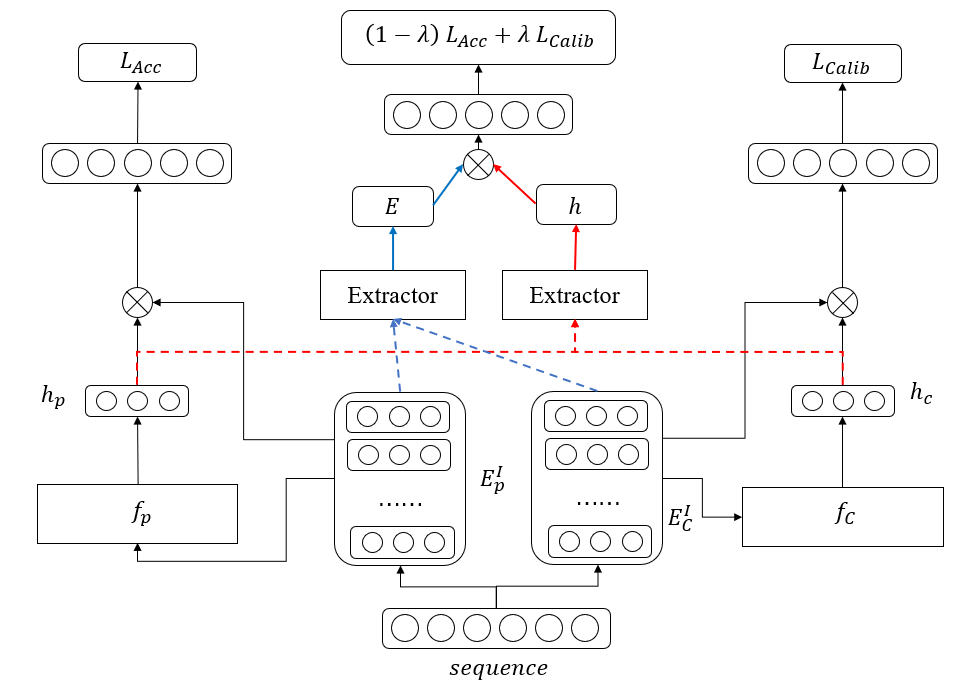
Recent years have witnessed the progress of sequential recommendation in accurately predicting users' future behaviors. However, only persuading accuracy leads to the risk of filter bubbles where recommenders only focus on users' main interest areas. Different from other studies which improve diversity or coverage, we investigate the calibration in sequential recommendation, which aims to calibrate the interest distributions of recommendation lists and behavior sequences. However, existing calibration methods followed a post-processing paradigm, which costs more computation time and sacrifices the recommendation accuracy. To this end, we propose an end-to-end framework to provide both accurate and calibrated recommendations in sequential recommendation. We propose an objective function to measure the divergence of distributions between recommendation lists and historical behaviors. In addition, we design a decoupled-aggregated model which extracts information from two individual sequence encoders with different objectives to further improve the recommendation. Experiments on two benchmark datasets demonstrate the effectiveness and efficiency of our model.
翻译:近些年来,在准确预测用户未来行为方面,连续建议取得了进展。然而,只有说服准确性才能导致过滤泡沫的风险,因为推荐者只关注用户的主要利益领域。不同于提高多样性或覆盖面的其他研究,我们调查顺序建议中的校准,目的是校准建议列表和行为序列的利息分配。然而,现有的校准方法遵循后处理模式,这需要更多的时间计算时间,牺牲建议准确性。为此,我们提议了一个端对端框架,在顺序建议中提供准确和校准的建议。我们提出了一个客观功能,以衡量建议清单和历史行为之间的分布差异。此外,我们设计了一个分解的、综合的模型,从两个单个序列中提取信息,其目标不同,以进一步改进建议。关于两个基准数据集的实验显示了我们模型的有效性和效率。