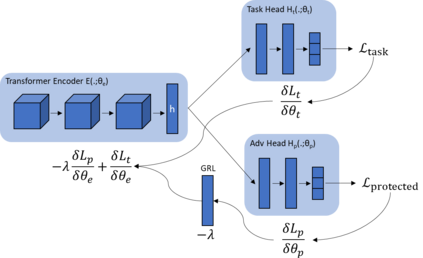
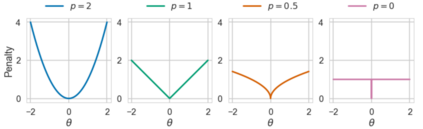
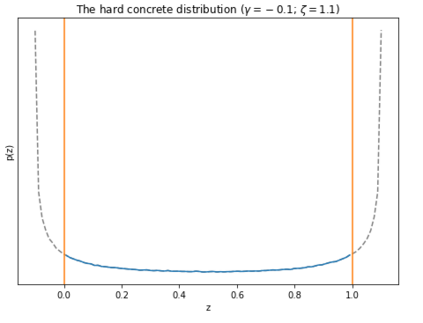
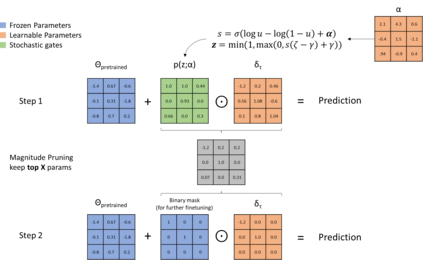
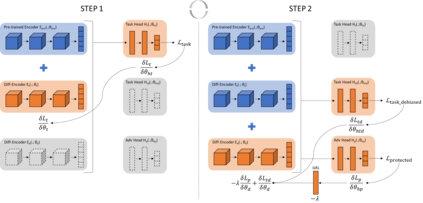
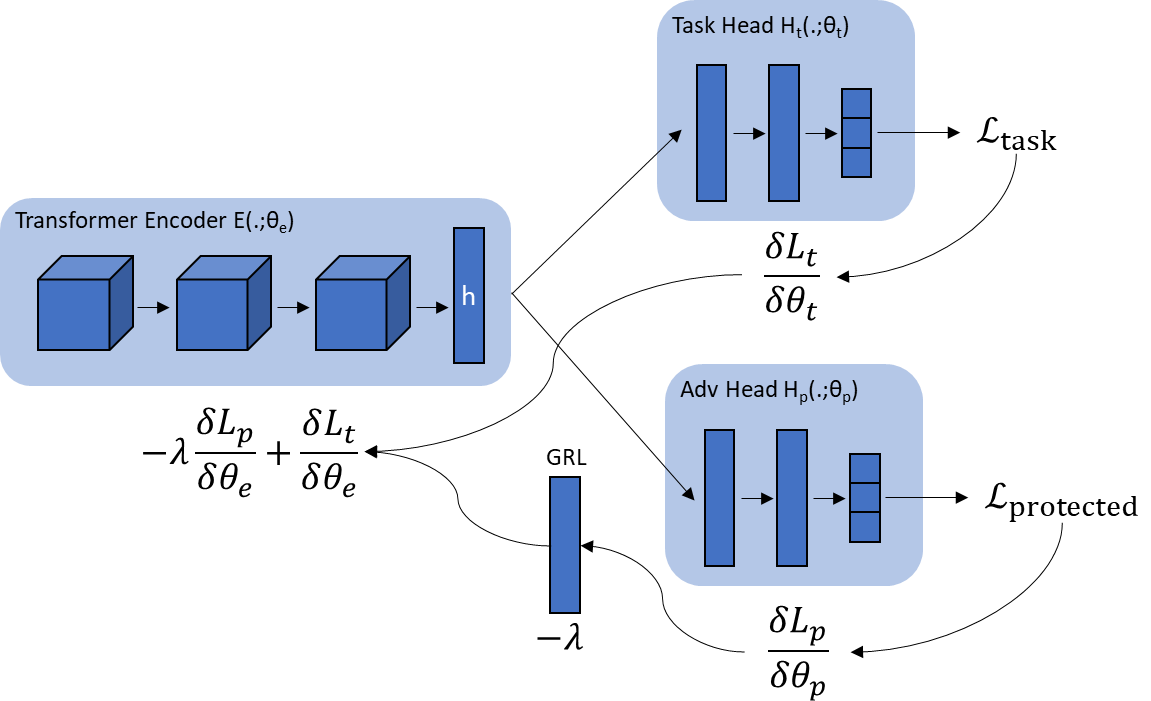
In recent years language models have achieved state of the art performance on a wide variety of natural language processing tasks. As these models are continuously growing in size it becomes increasingly important to explore methods to make them more storage efficient. At the same time their increase cognitive abilities increase the danger that societal bias existing in datasets are implicitly encoded in the model weights. We propose an architecture which deals with these two challenges at the same time using two techniques: DiffPruning and Adverserial Training. The result is a modular architecture which extends the original DiffPurning setup with and additional sparse subnetwork applied as a mask to diminish the effects of a predefined protected attribute at inference time.
翻译:近年来,语言模型在各种自然语言处理任务方面达到了最新水平,随着这些模型的规模不断扩大,探索提高存储效率的方法变得越来越重要。与此同时,它们的认知能力的提高增加了将数据集中存在的社会偏见隐含在模型加权数中的危险。我们建议采用两种技术,即DiffPruning和Aversical Training,同时处理这两个挑战的架构。其结果是模块化结构,扩展了原有的DiffPurning设置,并增加了稀有的子网络,以掩盖在推断时预先界定的保护属性的影响。