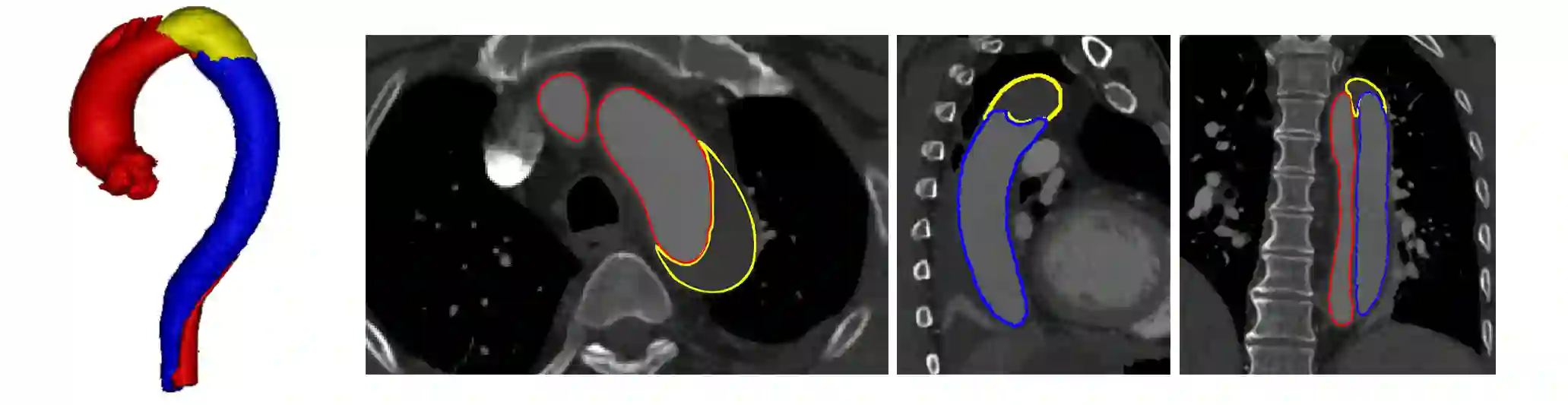
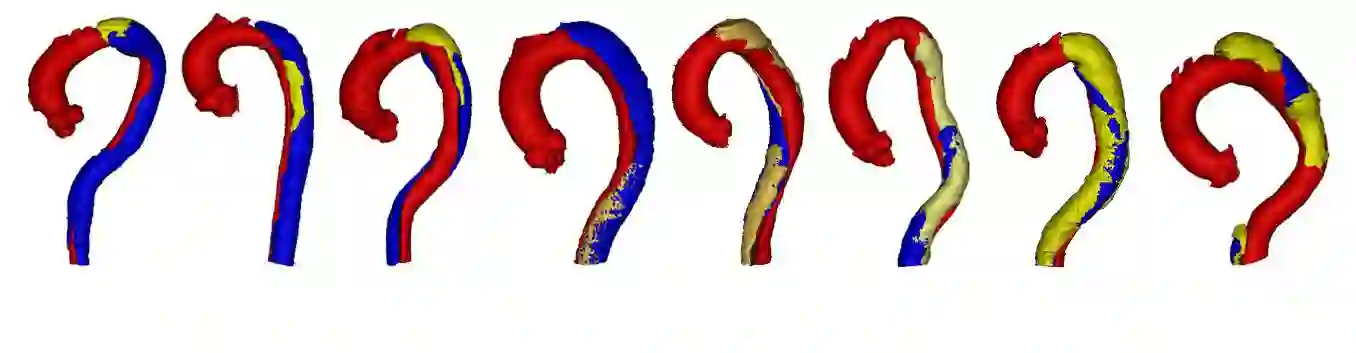Type-B Aortic Dissection (TBAD) is one of the most serious cardiovascular events characterized by a growing yearly incidence,and the severity of disease prognosis. Currently, computed tomography angiography (CTA) has been widely adopted for the diagnosis and prognosis of TBAD. Accurate segmentation of true lumen (TL), false lumen (FL), and false lumen thrombus (FLT) in CTA are crucial for the precise quantification of anatomical features. However, existing works only focus on only TL and FL without considering FLT. In this paper, we propose ImageTBAD, the first 3D computed tomography angiography (CTA) image dataset of TBAD with annotation of TL, FL, and FLT. The proposed dataset contains 100 TBAD CTA images, which is of decent size compared with existing medical imaging datasets. As FLT can appear almost anywhere along the aorta with irregular shapes, segmentation of FLT presents a wide class of segmentation problems where targets exist in a variety of positions with irregular shapes. We further propose a baseline method for automatic segmentation of TBAD. Results show that the baseline method can achieve comparable results with existing works on aorta and TL segmentation. However, the segmentation accuracy of FLT is only 52%, which leaves large room for improvement and also shows the challenge of our dataset. To facilitate further research on this challenging problem, our dataset and codes are released to the public.
翻译:B型Aortic Disect(TABD)是最重要的心血管事件之一,其特点是每年发病率和疾病预测的严重程度不断增加。目前,计算成的XMAD(CTA)图像成像(CTA)已广泛用于TBAD的诊断和预测。对于精确量化解剖特征而言,CTA中真实的润滑剂(TL)、假润滑剂(FLT)和假润滑质(FLT)的精确分解(FLT)至关重要。然而,现有的工作仅侧重于TL和FLT,而没有考虑FLT。在本文件中,我们提出了“图像TBAD(CTA)”(CTA),第一个计算成像像像(CTAD)的成像(CTTA) 3D(C) 成像(CTTA) 的成像数据集(CTLD) 准确度(CTAD) 准确度(CLTA值与现有成像数据集相比是相当的。FLTTA的大小。FLT(F) 分解解剖面图(FL) 的精度(C) 解解解解解解解解) 和数据(TFLD) 解解解解解) 显示现有数据(TFLD) 的模型(TFAD) 数据(O) 解算法(OD) 的大规模) 的精确度(V) 的大小。我们(TFAFL) 解算法(V) 解算法(TFL) 解算法(O) 解算法(L) 解算法(O) 的精确) 解算法(V) ) 的比。我们的数据(L) 的精确性分析(L) ) 解法(L) 解法(L) 解算法(L) 解解算法(VDFADFDFADFL) 的大小(L) ) 解算法(TFAFA) 解(L) 解) 解算法(L) 和(L) 和(OD) 解算法(L) 解算法(L