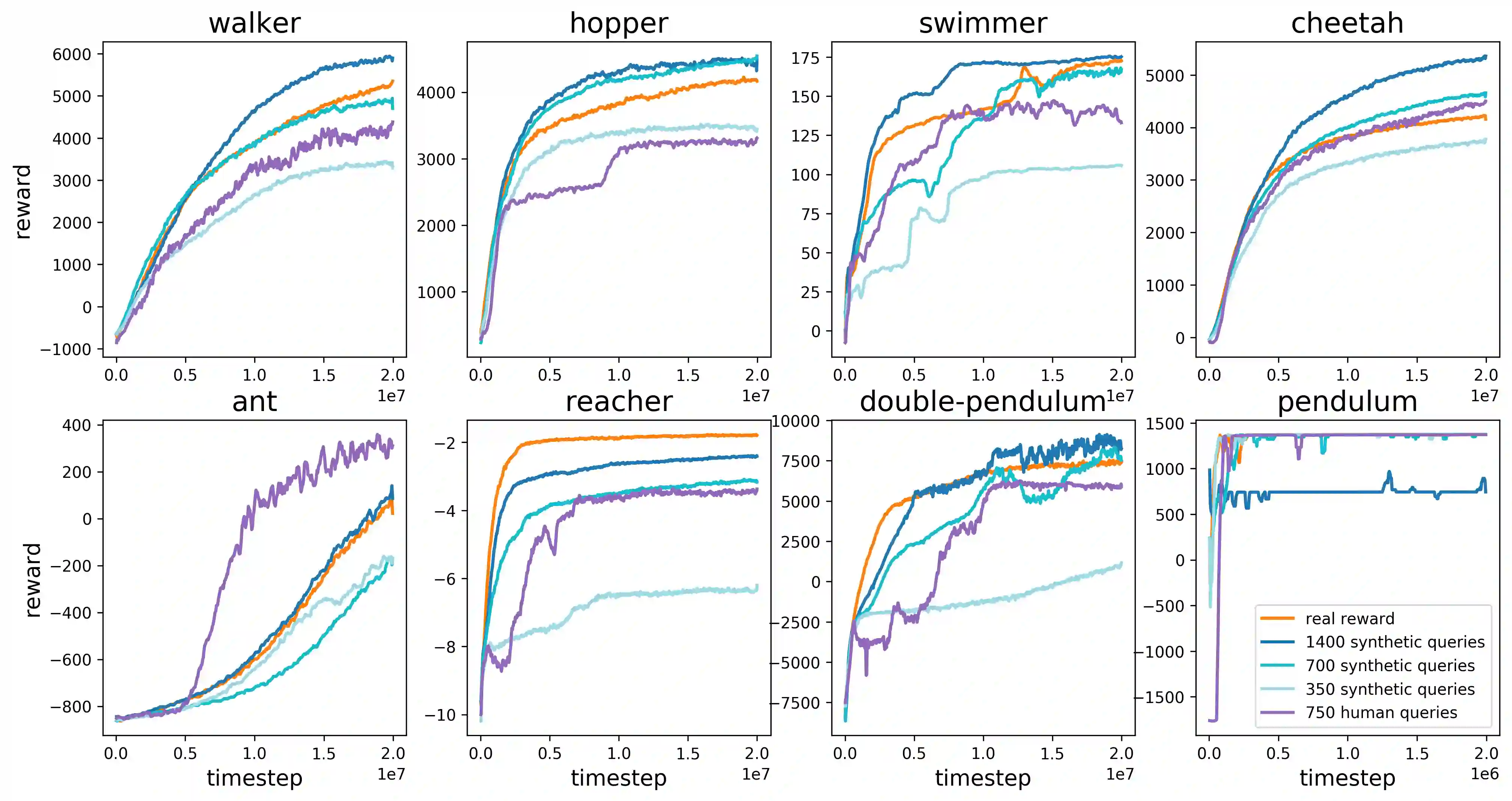
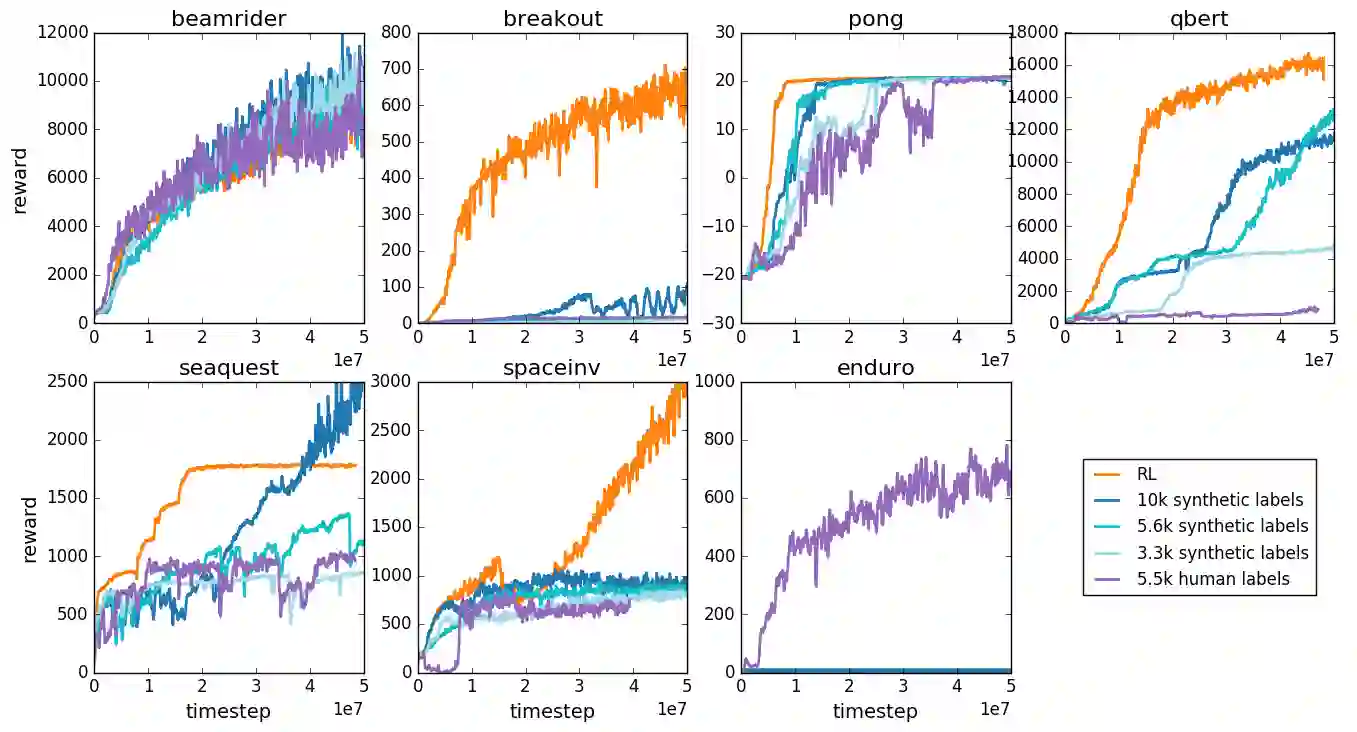
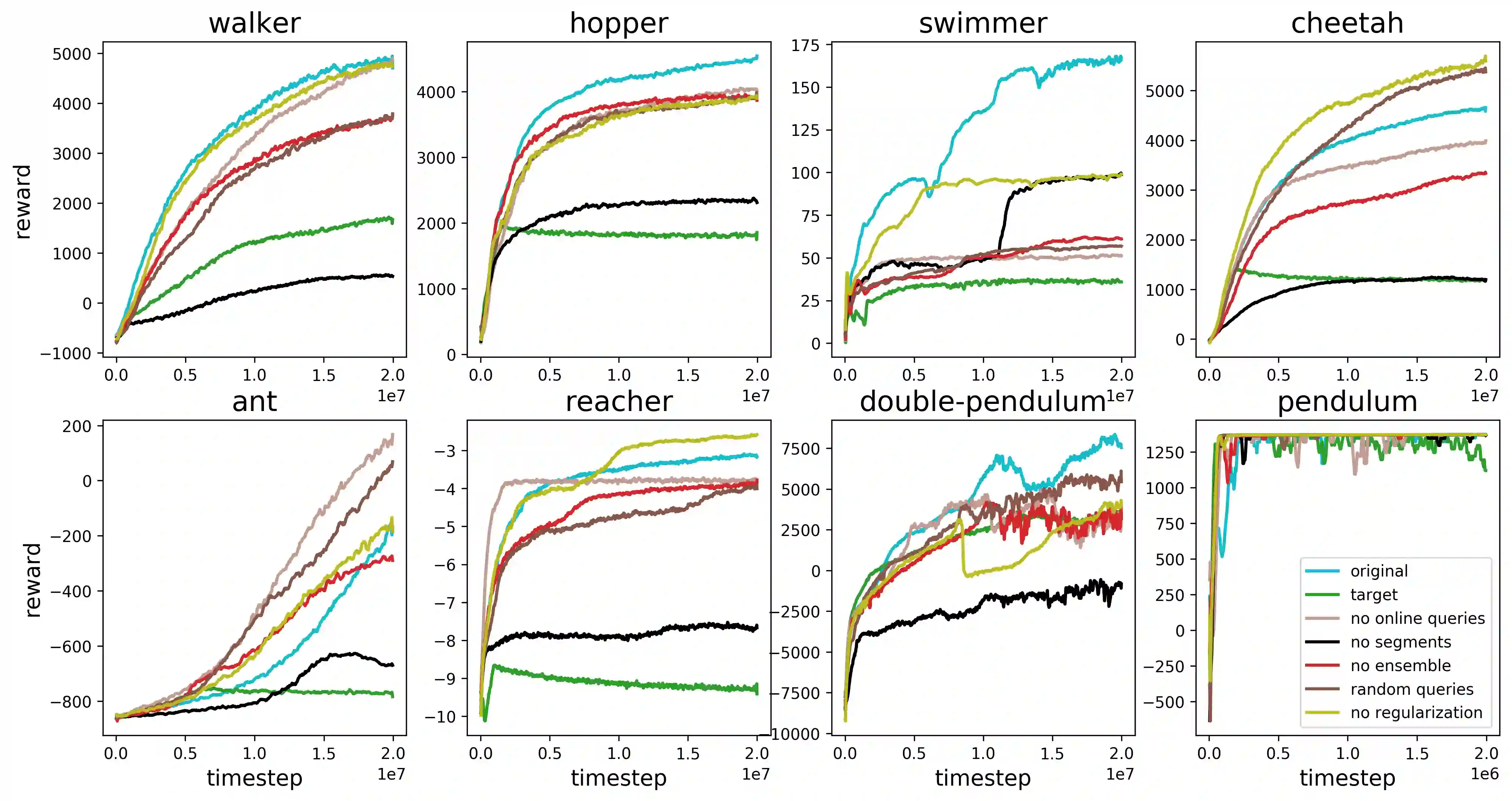
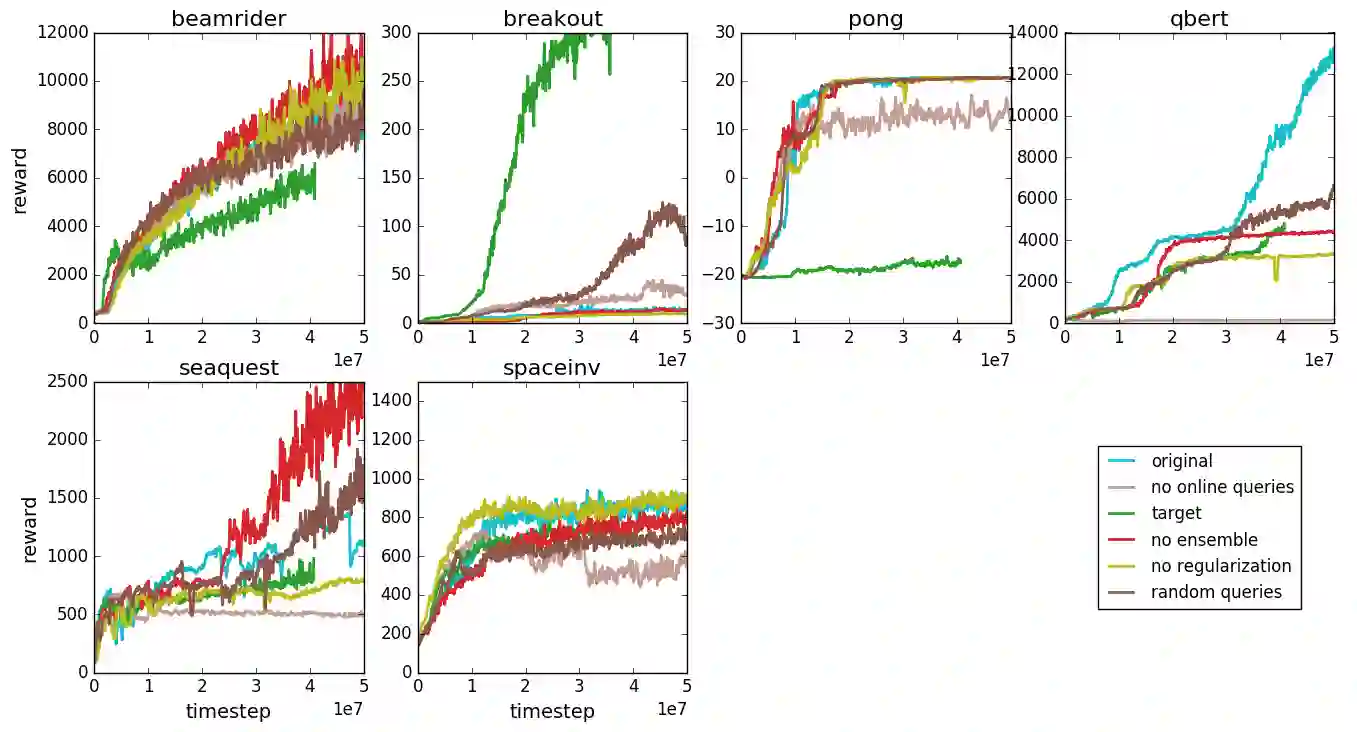
For sophisticated reinforcement learning (RL) systems to interact usefully with real-world environments, we need to communicate complex goals to these systems. In this work, we explore goals defined in terms of (non-expert) human preferences between pairs of trajectory segments. We show that this approach can effectively solve complex RL tasks without access to the reward function, including Atari games and simulated robot locomotion, while providing feedback on less than one percent of our agent's interactions with the environment. This reduces the cost of human oversight far enough that it can be practically applied to state-of-the-art RL systems. To demonstrate the flexibility of our approach, we show that we can successfully train complex novel behaviors with about an hour of human time. These behaviors and environments are considerably more complex than any that have been previously learned from human feedback.
翻译:为了让精密的强化学习(RL)系统与现实世界环境进行有益的互动,我们需要将这些复杂的目标传达给这些系统。 在这项工作中,我们探索了由(非专家的)人类偏好在两对轨道段之间界定的目标。我们表明,这种方法可以有效地解决复杂的RL任务,而无需获得奖励功能,包括Atari游戏和模拟机器人移动功能,同时提供不到我们代理人与环境互动的1%的反馈。这可以降低人类监督的成本,使其在最先进的RL系统中可以实际应用。为了展示我们的方法的灵活性,我们证明我们能够成功地用大约一个小时的时间来培训复杂的新的行为。这些行为和环境比以前从人类反馈中学到的要复杂得多。