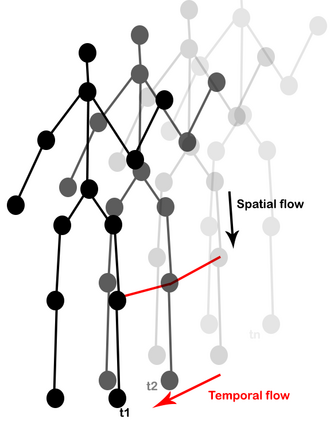
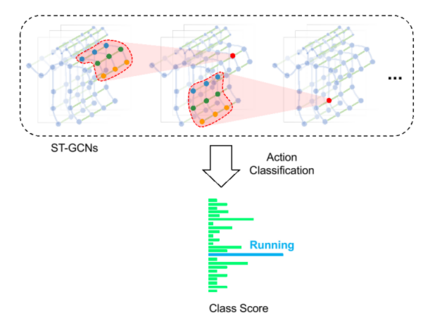
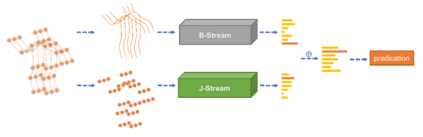
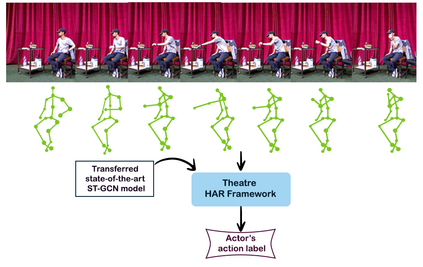
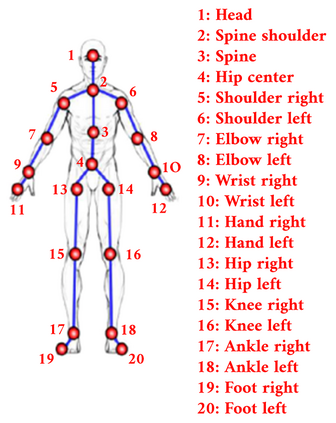
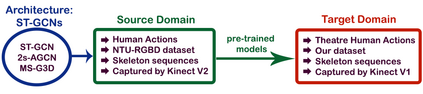
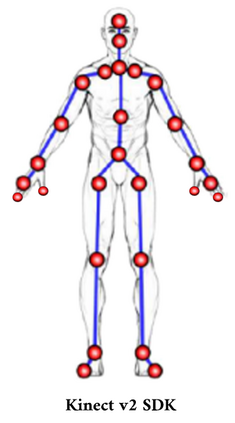
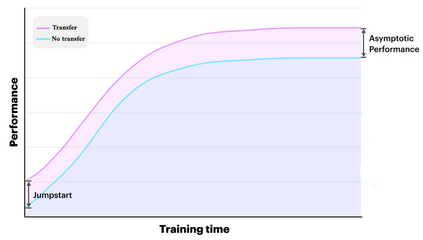
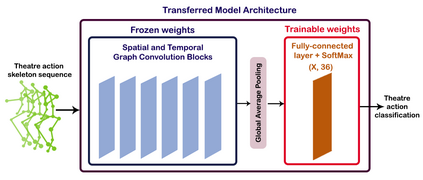
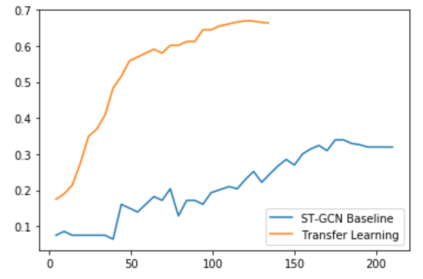
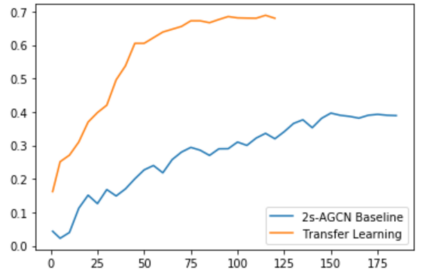
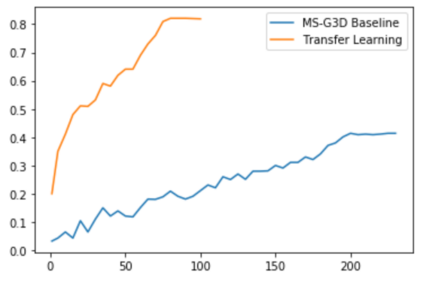
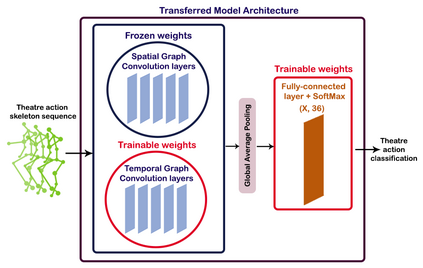
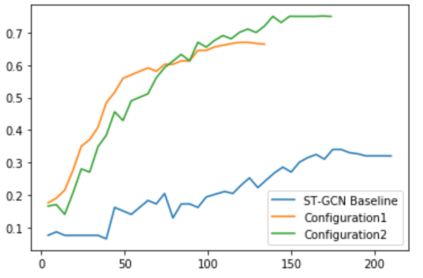
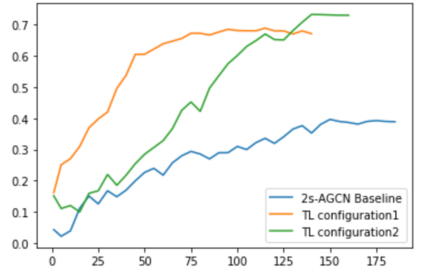
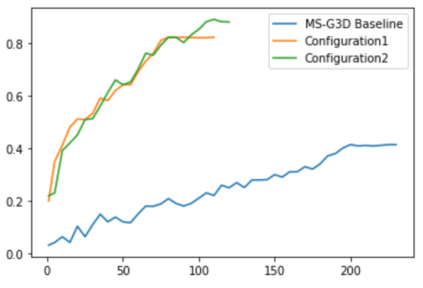
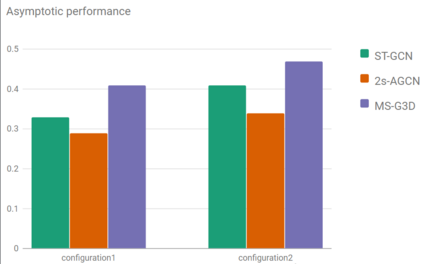
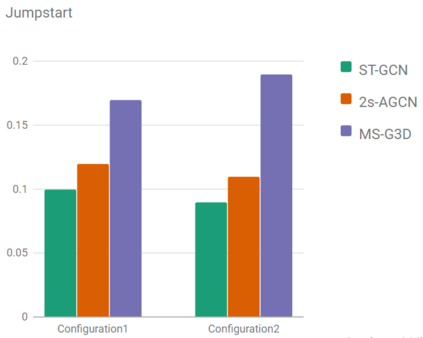
The aim of this research is to recognize human actions performed on stage to aid visually impaired and blind individuals. To achieve this, we have created a theatre human action recognition system that uses skeleton data captured by depth image as input. We collected new samples of human actions in a theatre environment, and then tested the transfer learning technique with three pre-trained Spatio-Temporal Graph Convolution Networks for skeleton-based human action recognition: the spatio-temporal graph convolution network, the two-stream adaptive graph convolution network, and the multi-scale disentangled unified graph convolution network. We selected the NTU-RGBD human action benchmark as the source domain and used our collected dataset as the target domain. We analyzed the transferability of the pre-trained models and proposed two configurations to apply and adapt the transfer learning technique to the diversity between the source and target domains. The use of transfer learning helped to improve the performance of the human action system within the context of theatre. The results indicate that Spatio-Temporal Graph Convolution Networks is positively transferred, and there was an improvement in performance compared to the baseline without transfer learning.
翻译:暂无翻译