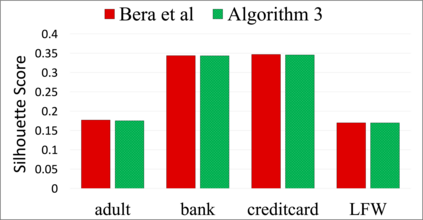
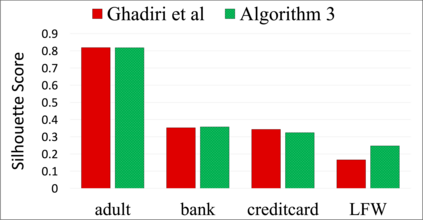
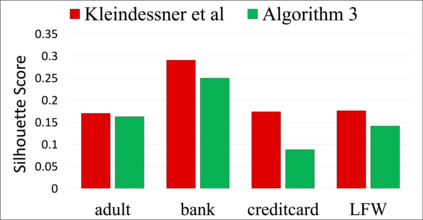
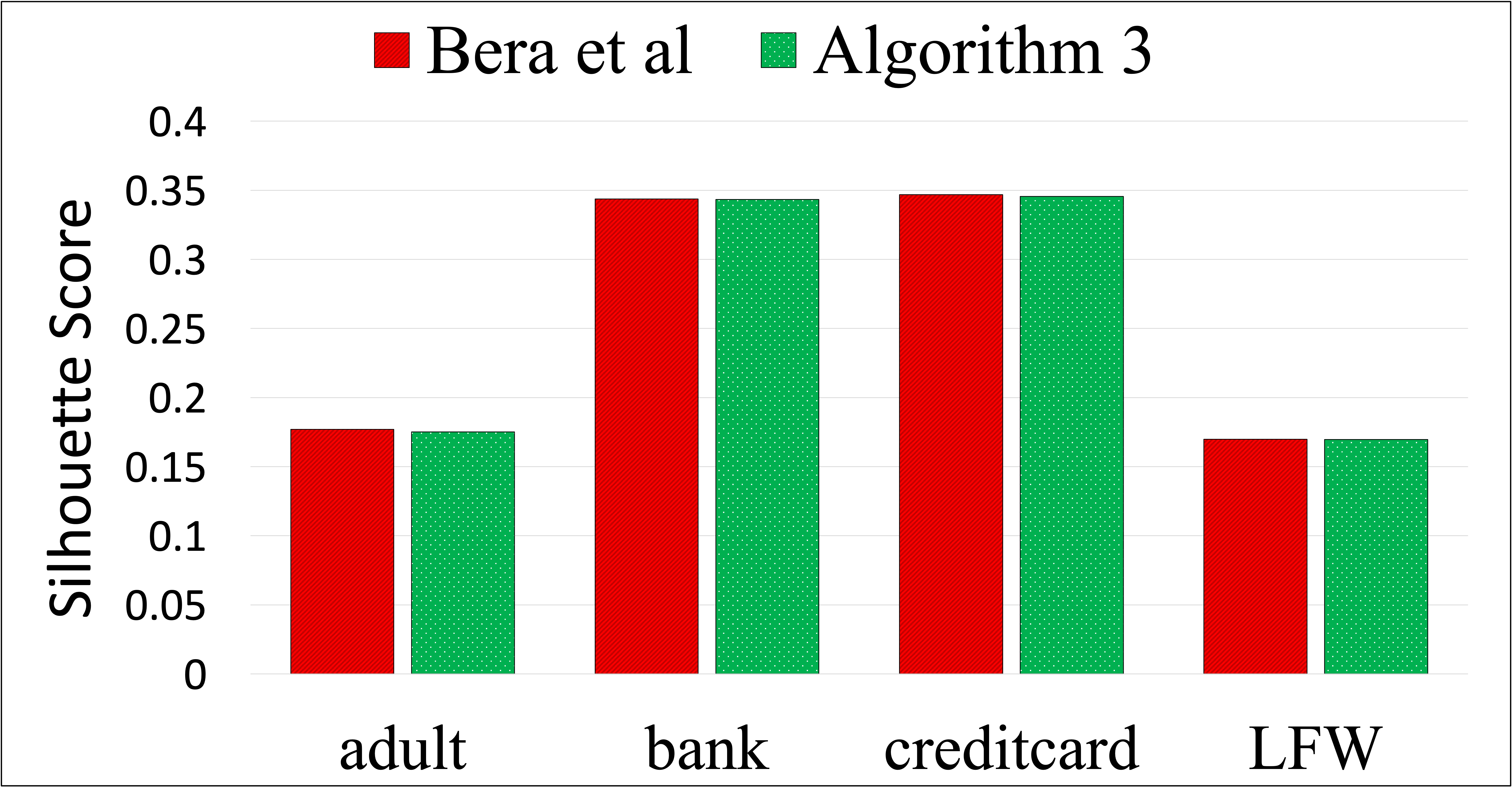
Clustering algorithms are widely utilized for many modern data science applications. This motivates the need to make outputs of clustering algorithms fair. Traditionally, new fair algorithmic variants to clustering algorithms are developed for specific notions of fairness. However, depending on the application context, different definitions of fairness might need to be employed. As a result, new algorithms and analysis need to be proposed for each combination of clustering algorithm and fairness definition. Additionally, each new algorithm would need to be reimplemented for deployment in a real-world system. Hence, we propose an alternate approach to fairness in clustering where we augment the original dataset with a small number of data points, called antidote data. When clustering is undertaken on this new dataset, the output is fair, for the chosen clustering algorithm and fairness definition. We formulate this as a general bi-level optimization problem which can accommodate any center-based clustering algorithms and fairness notions. We then categorize approaches for solving this bi-level optimization for different problem settings. Extensive experiments on different clustering algorithms and fairness notions show that our algorithms can achieve desired levels of fairness on many real-world datasets with a very small percentage of antidote data added. We also find that our algorithms achieve lower fairness costs and competitive clustering performance compared to other state-of-the-art fair clustering algorithms.
翻译:许多现代数据科学应用广泛使用集群算法。 这促使人们需要使集群算法的输出公平。 传统上, 以新的公平算法变数来组群算法的新的公平算法变数, 是为特定公平概念而开发的。 但是, 取决于应用背景, 可能需要采用不同的公平定义。 因此, 需要为组合算法和公平定义的每一种组合提出新的算法和分析。 此外, 每种新的算法都需要重新实施, 以便在现实世界系统中进行部署。 因此, 我们提出一种公平分组的替代方法, 即我们用少量的数据点来增加原始数据集的原始数据集, 称为解毒数据。 当对这个新的数据集进行分组时, 产出是公平的, 对于所选择的集群算法和公平定义, 我们把它当作一个一般的双级优化问题, 可以容纳任何以中心为基础的组合算法和公平概念的组合法和公平概念。 我们随后对解决不同问题环境下的双级优化的方法进行了分类。 不同组合算法和公平概念的广泛实验表明, 我们的算法可以实现许多真实世界数据集的预期的公平水平,, 并且比较具有非常有竞争力的解算法的公平性的数据组合法, 也能够实现我们比较公平性能的更低的计算方法。