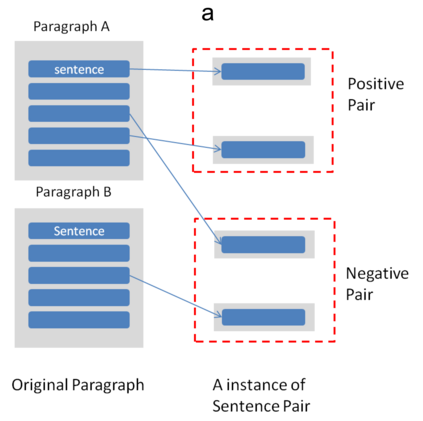
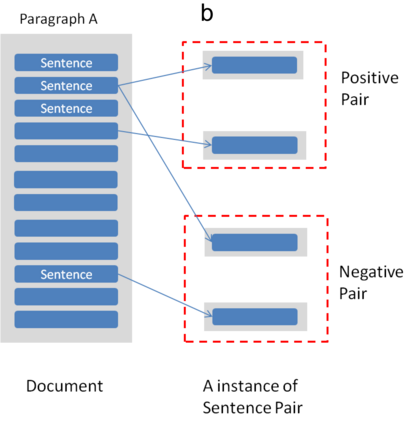
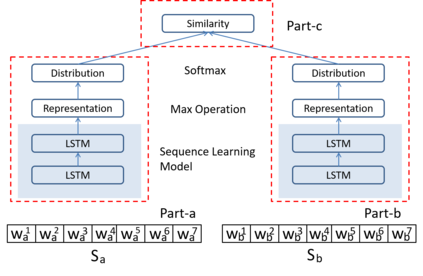
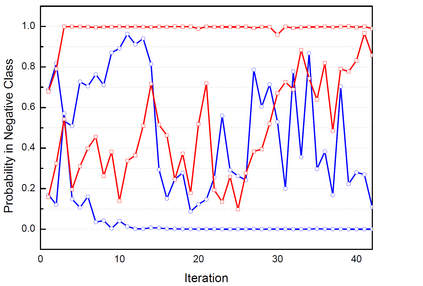
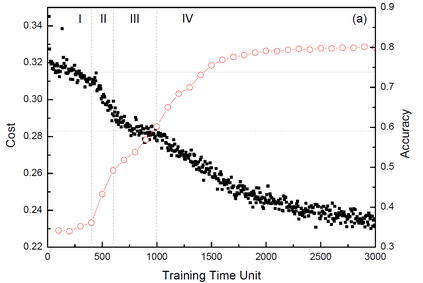
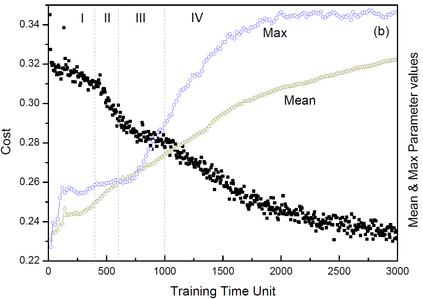
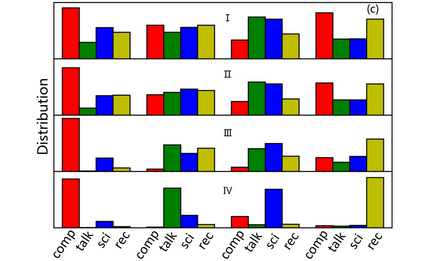
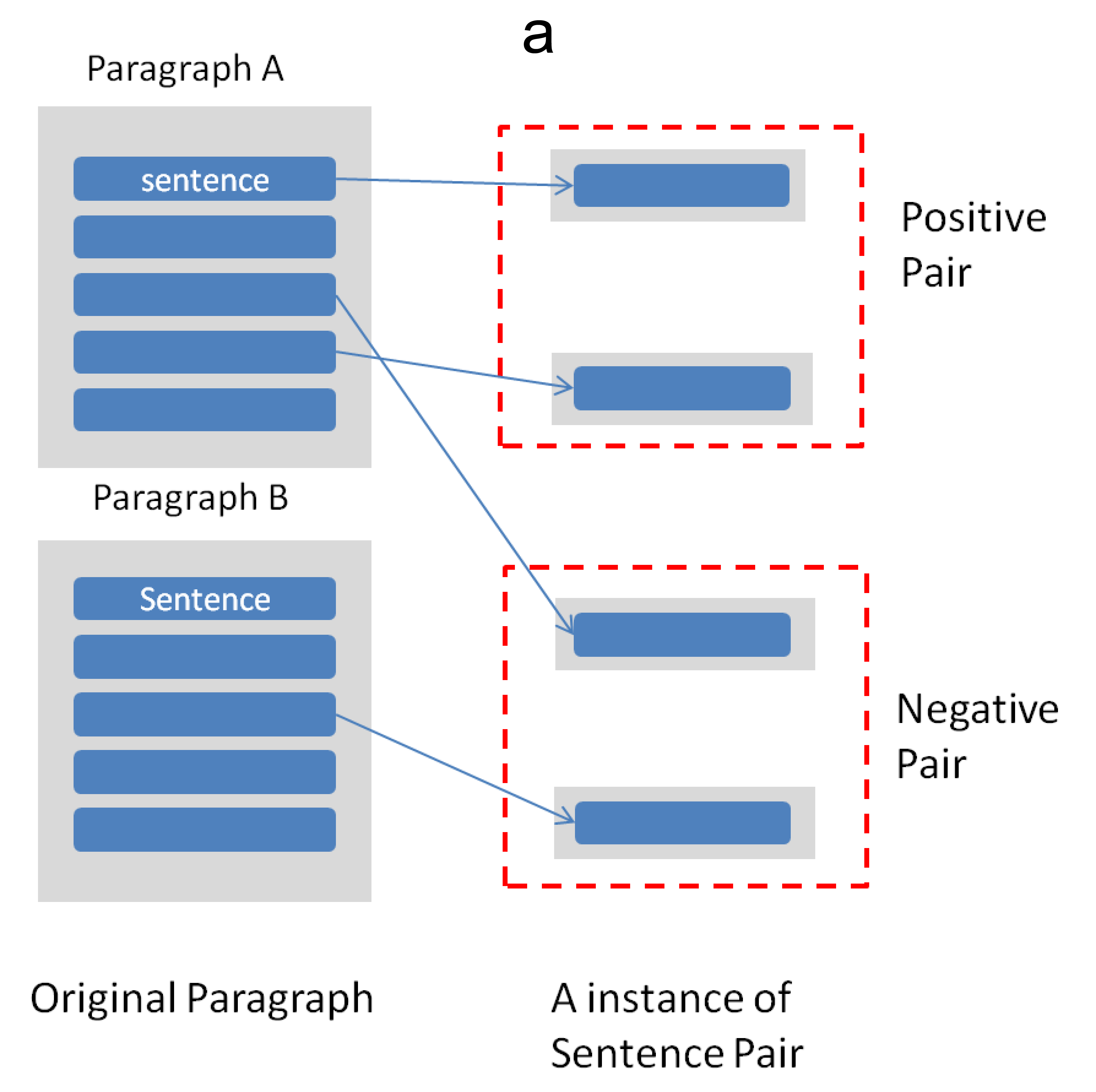
The unsupervised text clustering is one of the major tasks in natural language processing (NLP) and remains a difficult and complex problem. Conventional \mbox{methods} generally treat this task using separated steps, including text representation learning and clustering the representations. As an improvement, neural methods have also been introduced for continuous representation learning to address the sparsity problem. However, the multi-step process still deviates from the unified optimization target. Especially the second step of cluster is generally performed with conventional methods such as k-Means. We propose a pure neural framework for text clustering in an end-to-end manner. It jointly learns the text representation and the clustering model. Our model works well when the context can be obtained, which is nearly always the case in the field of NLP. We have our method \mbox{evaluated} on two widely used benchmarks: IMDB movie reviews for sentiment classification and $20$-Newsgroup for topic categorization. Despite its simplicity, experiments show the model outperforms previous clustering methods by a large margin. Furthermore, the model is also verified on English wiki dataset as a large corpus.
翻译:未监督的文本分组是自然语言处理(NLP)的主要任务之一,并且仍然是一个困难和复杂的问题。常规的\mbox{methods} 通常使用不同的步骤处理这项任务, 包括文本代表学习和演示组群。 作为改进, 还引入了神经学方法, 用于连续的演示学习, 以解决空间问题。 但是, 多步骤过程仍然偏离统一优化目标。 特别是组合的第二步通常使用传统方法, 如 k- Means 。 我们提议了纯神经框架, 用于以端到端的方式进行文本分组。 它共同学习文本表达和组群模式。 我们的模型在获得上下文时效果良好, 几乎都是 NLP 领域的情况。 我们在两种广泛使用的基准上采用了我们的方法\mbox{ 评价} : 情绪分类的IMDB 电影审查 和专题分类的20美元新组 。 尽管它很简单, 我们的实验显示模型比以往的组合方法大差。 此外, 该模型在 wiki 数据集中也得到验证。