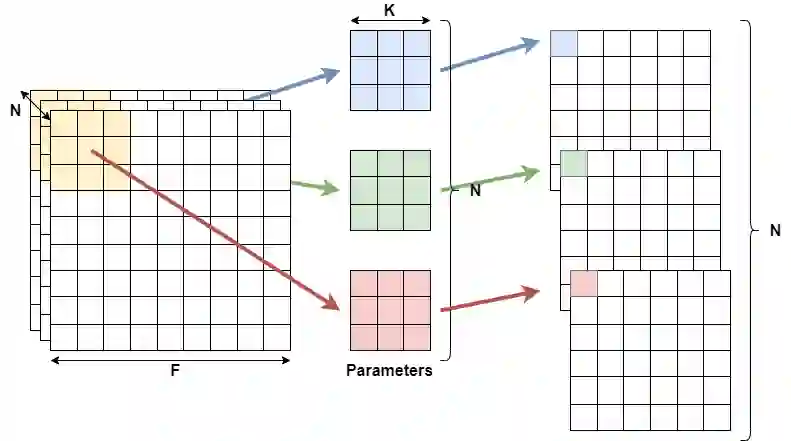
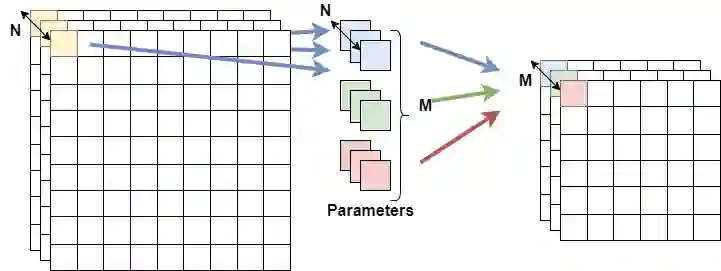
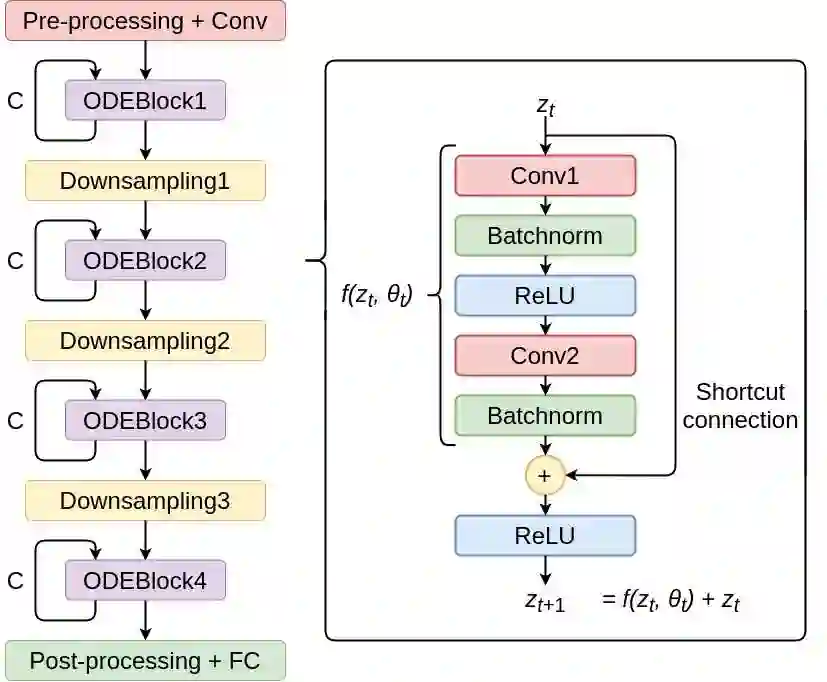
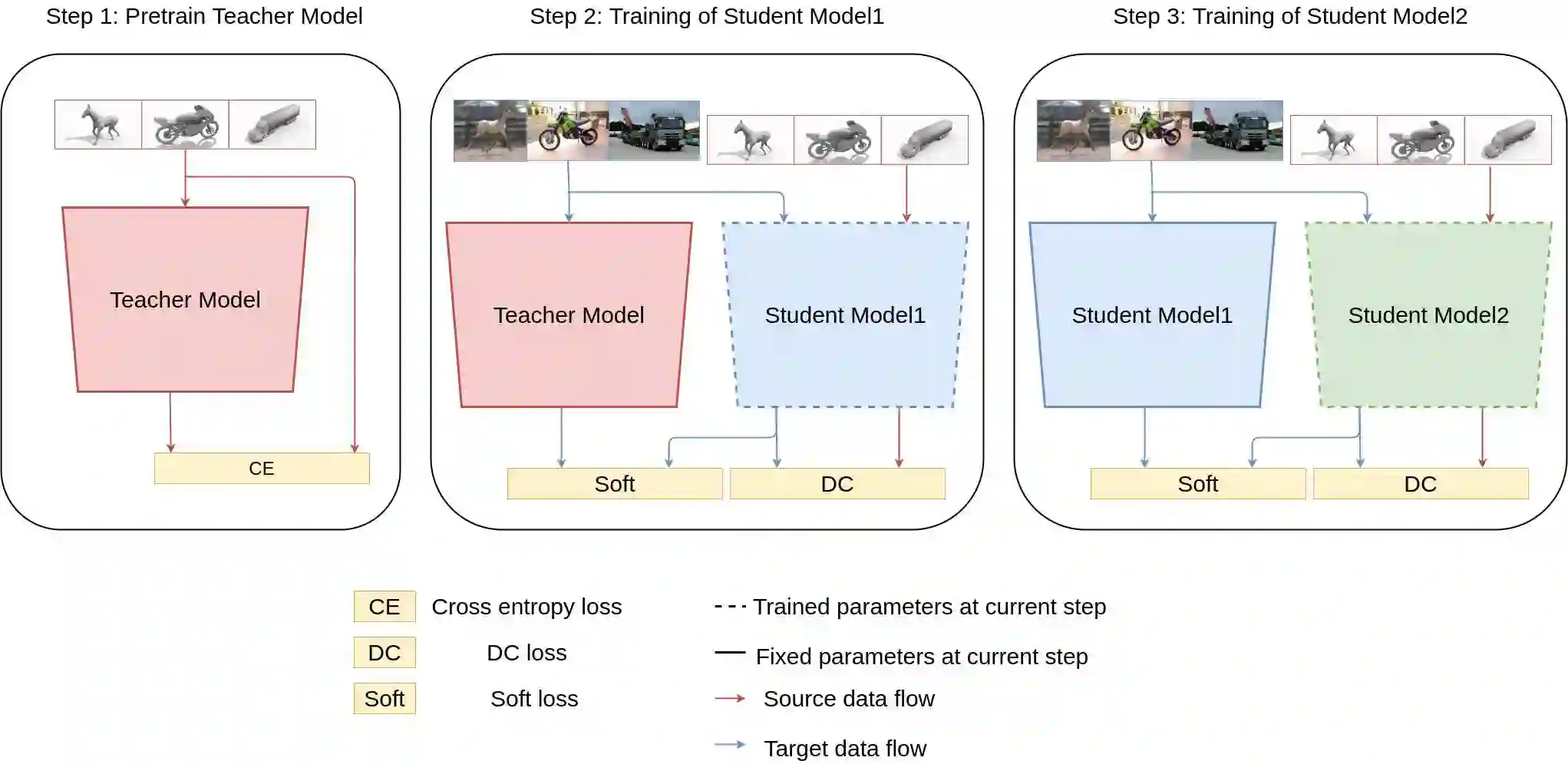
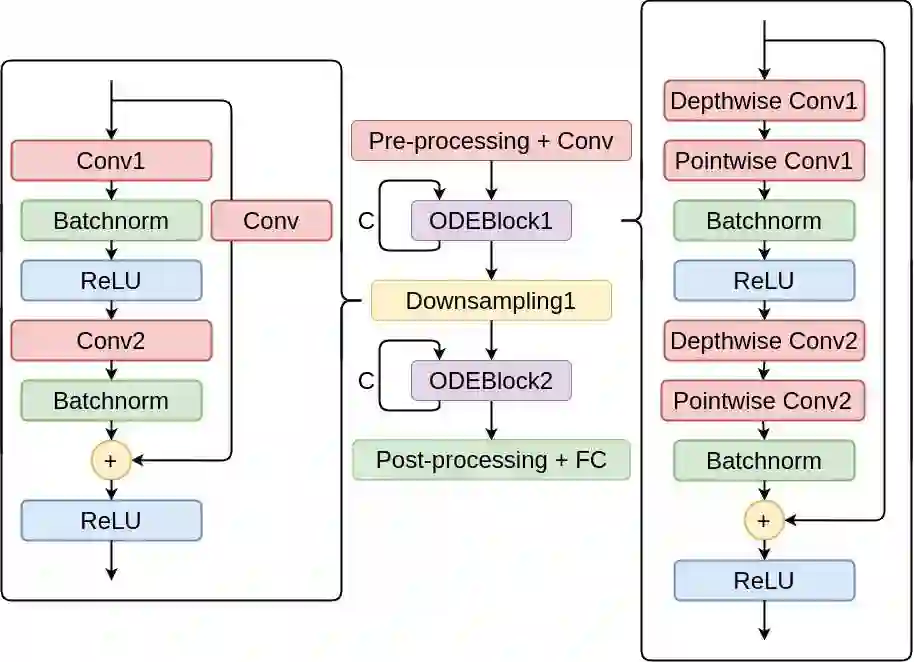
High-performance deep neural network (DNN)-based systems are in high demand in edge environments. Due to its high computational complexity, it is challenging to deploy DNNs on edge devices with strict limitations on computational resources. In this paper, we derive a compact while highly-accurate DNN model, termed dsODENet, by combining recently-proposed parameter reduction techniques: Neural ODE (Ordinary Differential Equation) and DSC (Depthwise Separable Convolution). Neural ODE exploits a similarity between ResNet and ODE, and shares most of weight parameters among multiple layers, which greatly reduces the memory consumption. We apply dsODENet to a domain adaptation as a practical use case with image classification datasets. We also propose a resource-efficient FPGA-based design for dsODENet, where all the parameters and feature maps except for pre- and post-processing layers can be mapped onto on-chip memories. It is implemented on Xilinx ZCU104 board and evaluated in terms of domain adaptation accuracy, training speed, FPGA resource utilization, and speedup rate compared to a software counterpart. The results demonstrate that dsODENet achieves comparable or slightly better domain adaptation accuracy compared to our baseline Neural ODE implementation, while the total parameter size without pre- and post-processing layers is reduced by 54.2% to 79.8%. Our FPGA implementation accelerates the inference speed by 27.9 times.
翻译:以高性能深度神经网络为基础的系统在边缘环境中需求很高。 由于其计算复杂程度很高, 很难在边端设备上部署DNN, 对计算资源有严格的限制。 在本文中, 我们通过结合最近提出的降低参数技术, 产生一个精密的DNN模型, 称为DsODENet, 并同时获得一个精密的DSON模型。 神经交换技术包括: Neal ODE (常规差异等同) 和 DSC (Dephwith Separable Convolution) 。 神经交换工具利用ResNet和ODOD之间的相似性, 并在多个层之间分享大部分重量参数,大大降低了内存消耗量。 我们将DSODNet应用DODENet作为实际使用的案例。 我们还提议一个基于资源效率的FPGA模型设计, 除了预处理层和后处理层之外的所有参数和地貌图都可以在芯记忆上绘制。 它在Xillinx ZCU104 董事会上实施, 并在域调整精确度、 培训速度、 FPGA资源利用率和速度比NODODER 的系统稍小的精确度, 和速度比比对软件基准级的精确度, 。