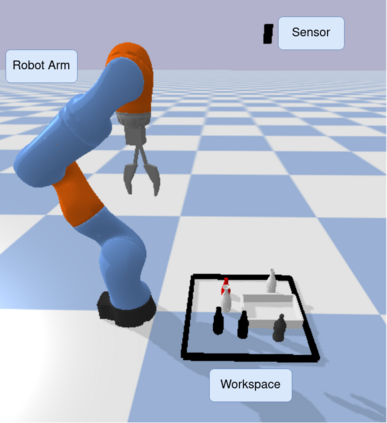
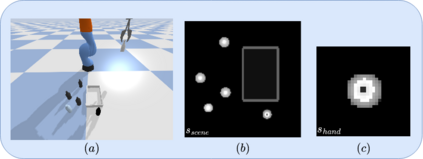
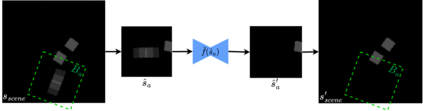
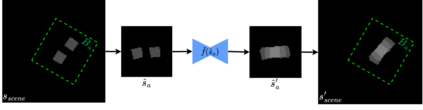
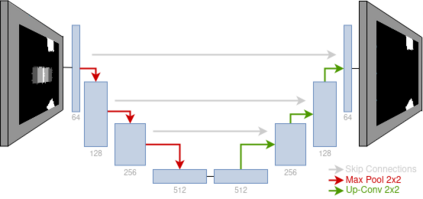
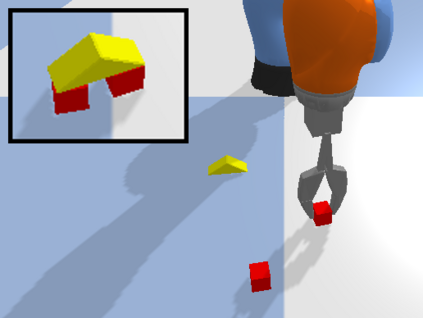
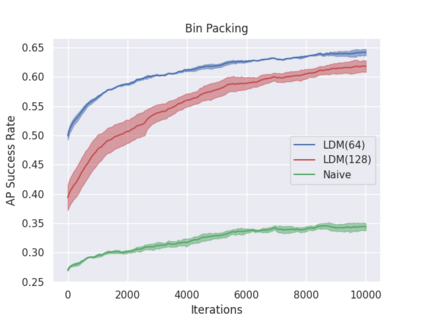
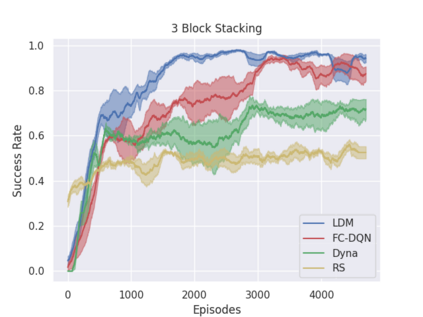
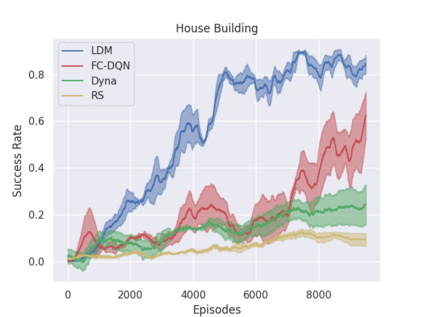
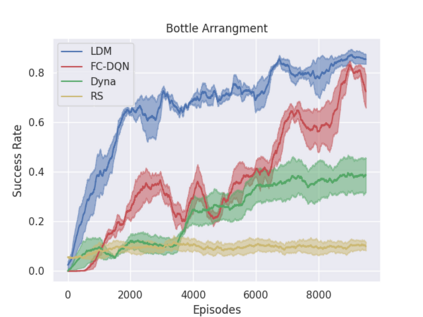
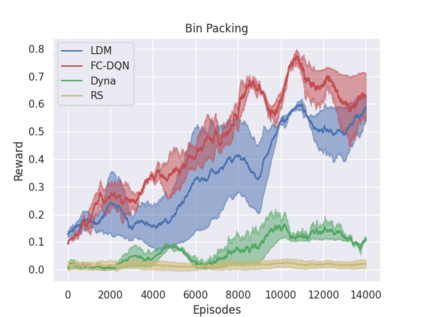
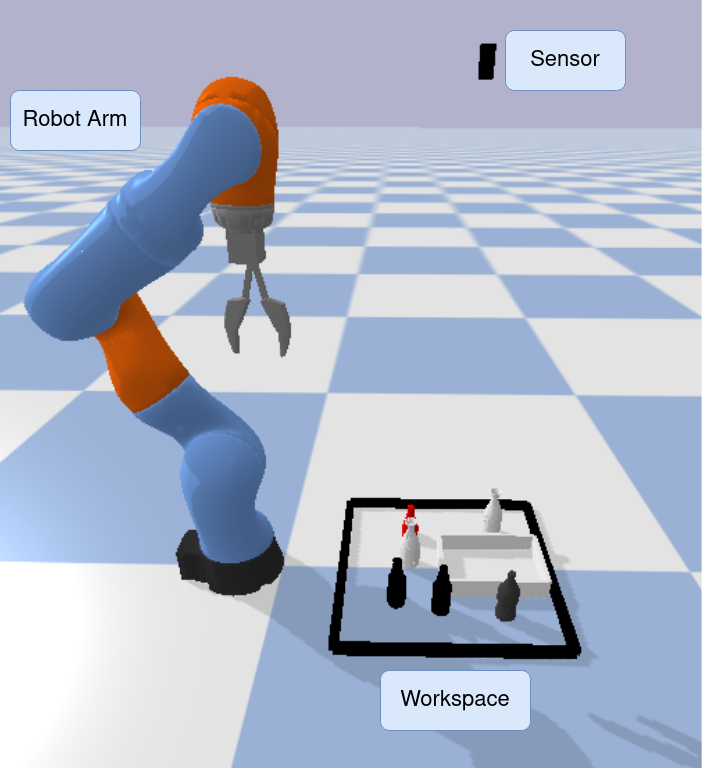
Model-free policy learning has been shown to be capable of learning manipulation policies which can solve long-time horizon tasks using single-step manipulation primitives. However, training these policies is a time-consuming process requiring large amounts of data. We propose the Local Dynamics Model (LDM) which efficiently learns the state-transition function for these manipulation primitives. By combining the LDM with model-free policy learning, we can learn policies which can solve complex manipulation tasks using one-step lookahead planning. We show that the LDM is both more sample-efficient and outperforms other model architectures. When combined with planning, we can outperform other model-based and model-free policies on several challenging manipulation tasks in simulation.
翻译:实践证明,不采用模式的政策学习能够学习操纵政策,这种政策能够用单步操纵原始技术解决长期的全局任务。然而,培训这些政策是一个耗时的过程,需要大量数据。我们提出了本地动态模型(LDM ), 高效学习这些操纵原始技术的国家过渡功能。通过将LDM与不采用模式的政策学习相结合,我们可以学习政策,用一步骤的外观规划解决复杂的操纵任务。我们证明LDM既具有更高的抽样效率,也优于其他模型结构。与规划相结合,我们可以在模拟中执行其他基于模式和无模式的政策。