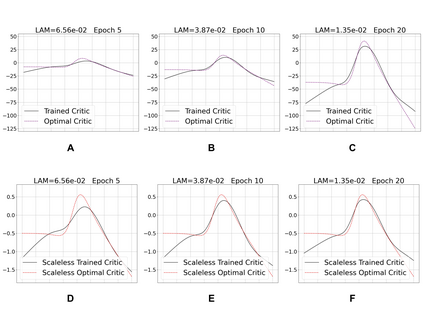
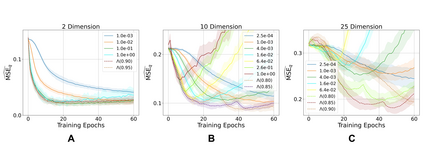
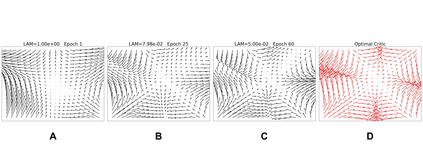
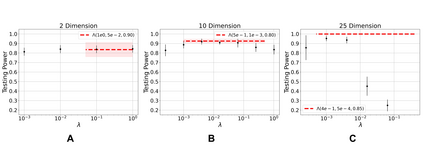
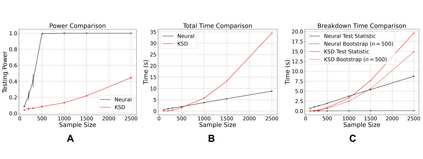
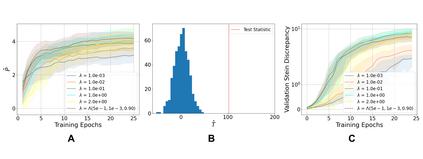
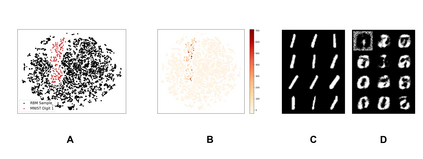
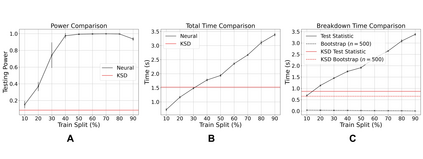
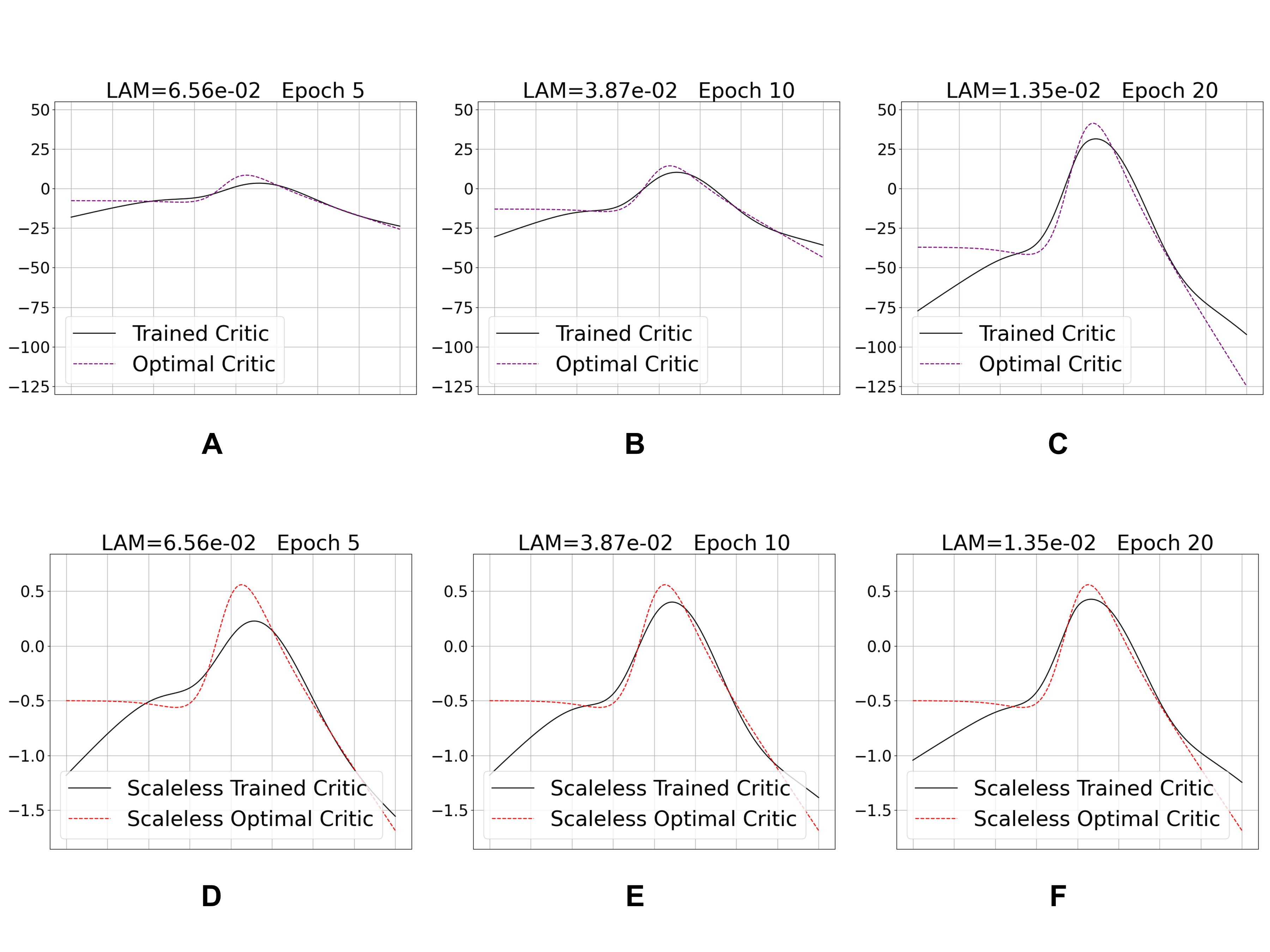
Learning to differentiate model distributions from observed data is a fundamental problem in statistics and machine learning, and high-dimensional data remains a challenging setting for such problems. Metrics that quantify the disparity in probability distributions, such as the Stein discrepancy, play an important role in statistical testing in high dimensions. In this paper, we consider the setting where one wishes to distinguish between data sampled from an unknown probability distribution and a nominal model distribution. While recent studies revealed that the optimal $L^2$-regularized Stein critic equals the difference of the score functions of two probability distributions up to a multiplicative constant, we investigate the role of $L^2$ regularization when training a neural network Stein discrepancy critic function. Motivated by the Neural Tangent Kernel theory of training neural networks, we develop a novel staging procedure for the weight of regularization over training time. This leverages the advantages of highly-regularized training at early times while also empirically delaying overfitting. Theoretically, we relate the training dynamic with large regularization weight to the kernel regression optimization of "lazy training" regime in early training times. The benefit of the staged $L^2$ regularization is demonstrated on simulated high dimensional distribution drift data and an application to evaluating generative models of image data.
翻译:在统计和机器学习方面,从观察到的数据中区分模型分布是一个根本问题,而高维数据仍然是这些问题的一个挑战性环境。量化概率分布差异(如Stein差异)方面的差异的尺度在统计测试中起着重要作用。在本文中,我们考虑了人们希望将抽样数据与未知概率分布和名义模型分布区分开来的背景。虽然最近的研究表明,最优的以L$2美元为常规的斯坦因斯坦差异评论员相当于两个概率分布的分数的差别,而两个概率分布到一个倍增常数,但我们在培训一个神经网络 Stein差异评论员功能时,我们调查了美元2美元的正规化的作用。在培训网络的Neural Tangent Kernel理论的激励下,我们为培训时间的正规化权重制定了一个新的新的演进程序。这利用了早期高度常规化培训的优势,同时也在经验上拖延了过度调整。理论上,我们把培训动态与“懒惰训练”制度的核心重量的回归优化联系起来。在早期培训期间,对高层次模型的模型的模型和模型的模型的模拟应用,展示了对高水平数据的模拟应用。