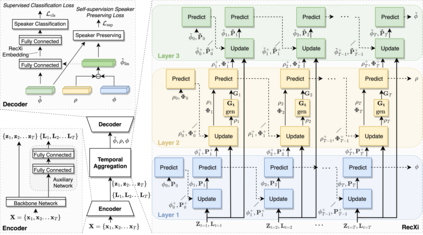
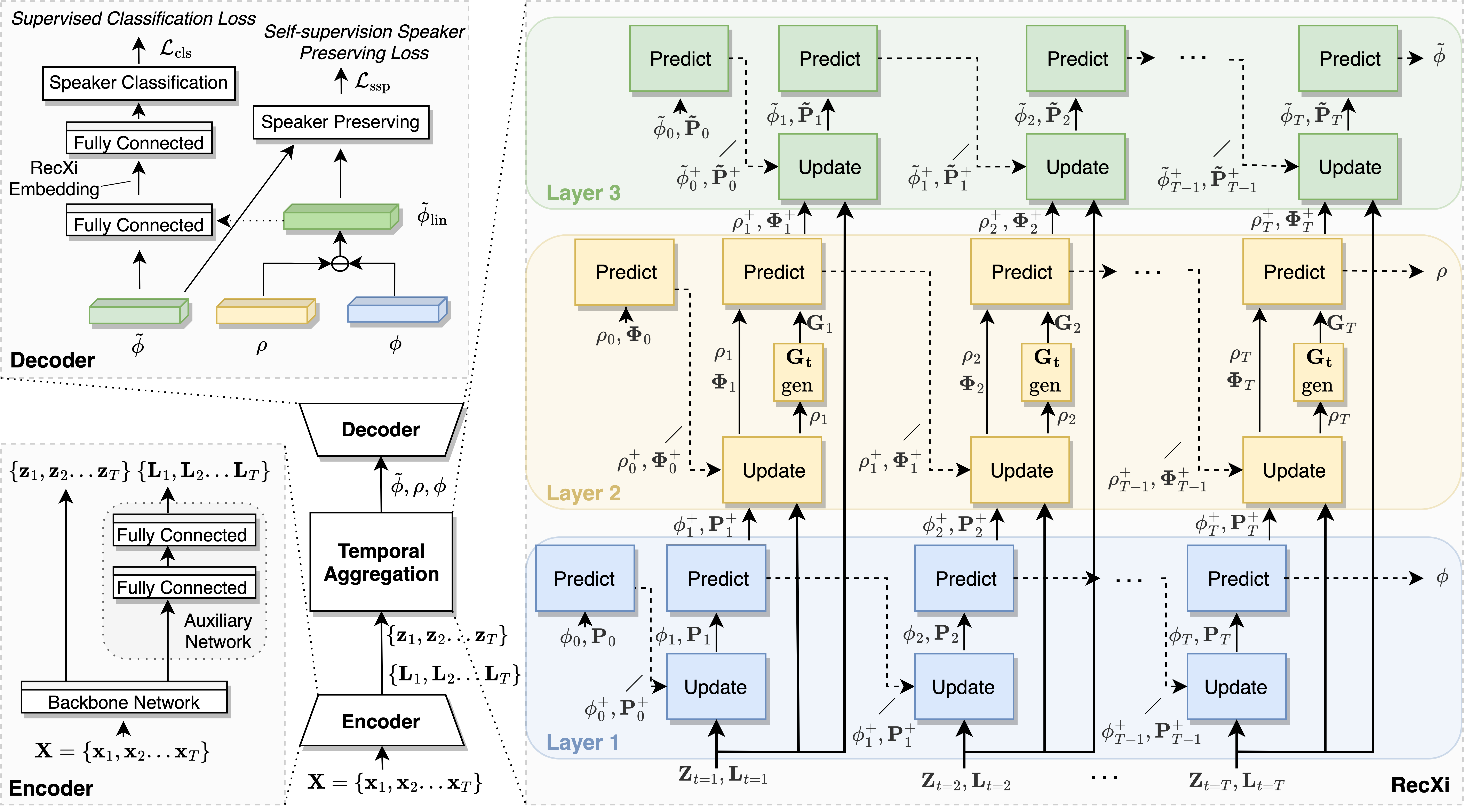
For speaker recognition, it is difficult to extract an accurate speaker representation from speech because of its mixture of speaker traits and content. This paper proposes a disentanglement framework that simultaneously models speaker traits and content variability in speech. It is realized with the use of three Gaussian inference layers, each consisting of a learnable transition model that extracts distinct speech components. Notably, a strengthened transition model is specifically designed to model complex speech dynamics. We also propose a self-supervision method to dynamically disentangle content without the use of labels other than speaker identities. The efficacy of the proposed framework is validated via experiments conducted on the VoxCeleb and SITW datasets with 9.56% and 8.24% average reductions in EER and minDCF, respectively. Since neither additional model training nor data is specifically needed, it is easily applicable in practical use.
翻译:暂无翻译