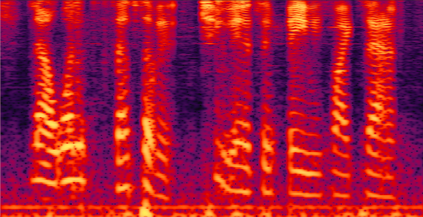
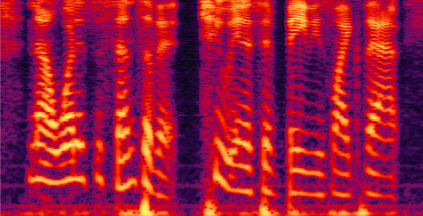
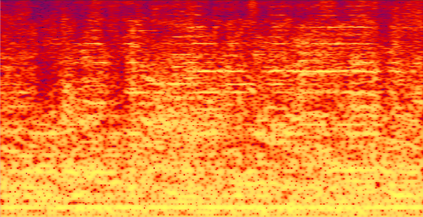
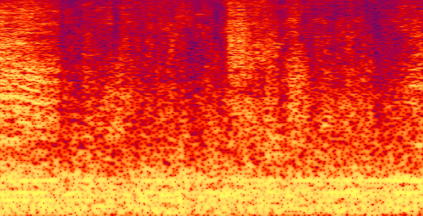
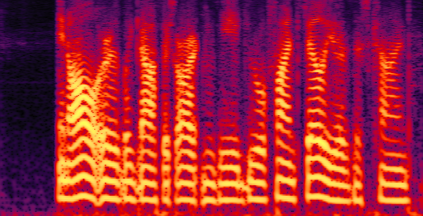
Recently, speech separation (SS) task has achieved remarkable progress driven by deep learning technique. However, it is still challenging to separate target speech from noisy mixture, as the neural model is vulnerable to assign background noise to each speaker. In this paper, we propose a noise-aware SS (NASS) method, which aims to improve the speech quality for separated signals under noisy conditions. Specifically, NASS views background noise as an independent output and predicts it with other speakers in a mask-based manner. Then we conduct patch-wise contrastive learning on feature level to minimize the mutual information between the predicted noise output and other speakers, which suppresses the noise information in separated signals, and vice versa. Experimental results show that NASS could achieve competitive results on different datasets, and significantly improve the noise-robustness for different mask-based SS backbones with less than 0.1M parameter increase.
翻译:暂无翻译