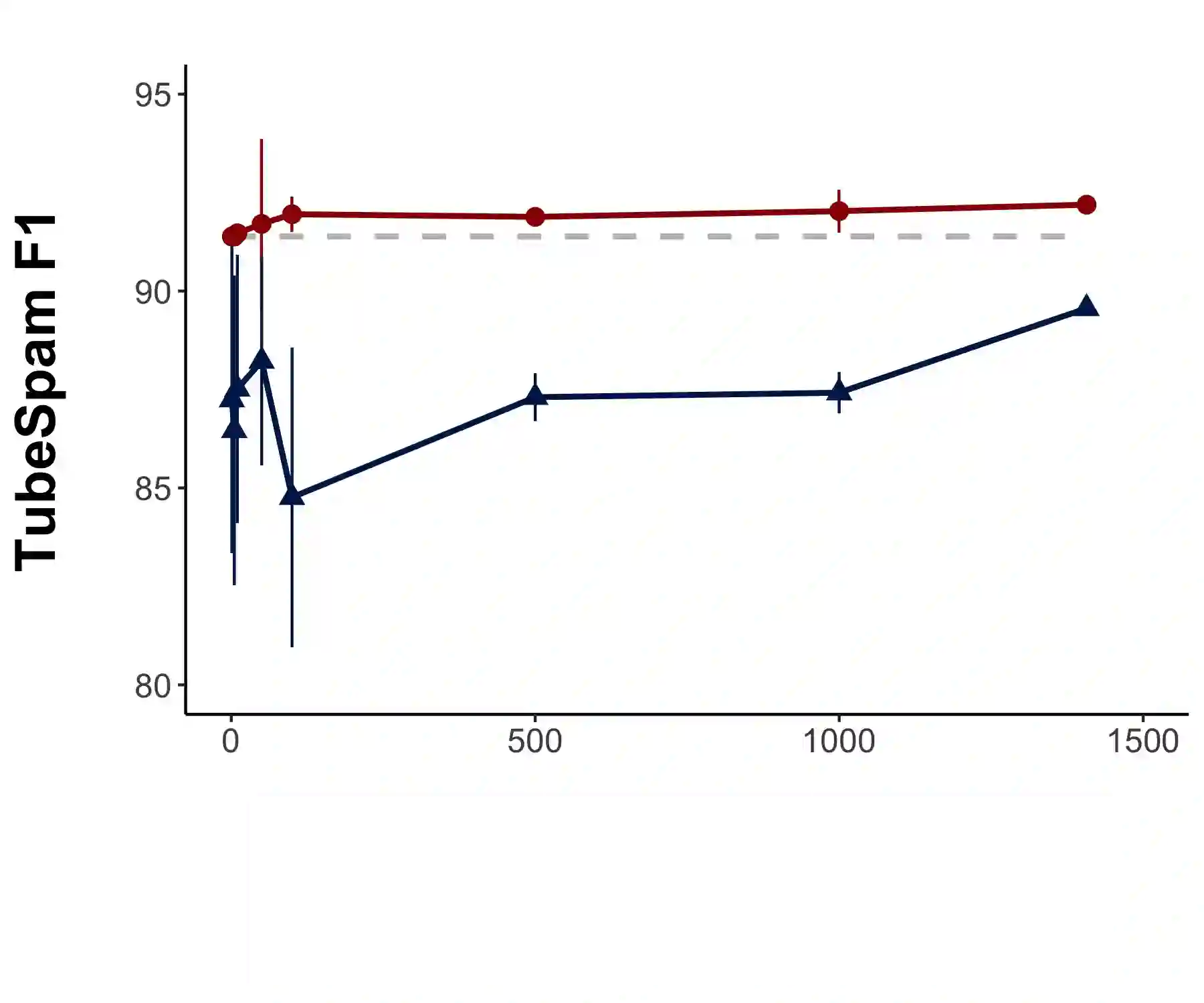
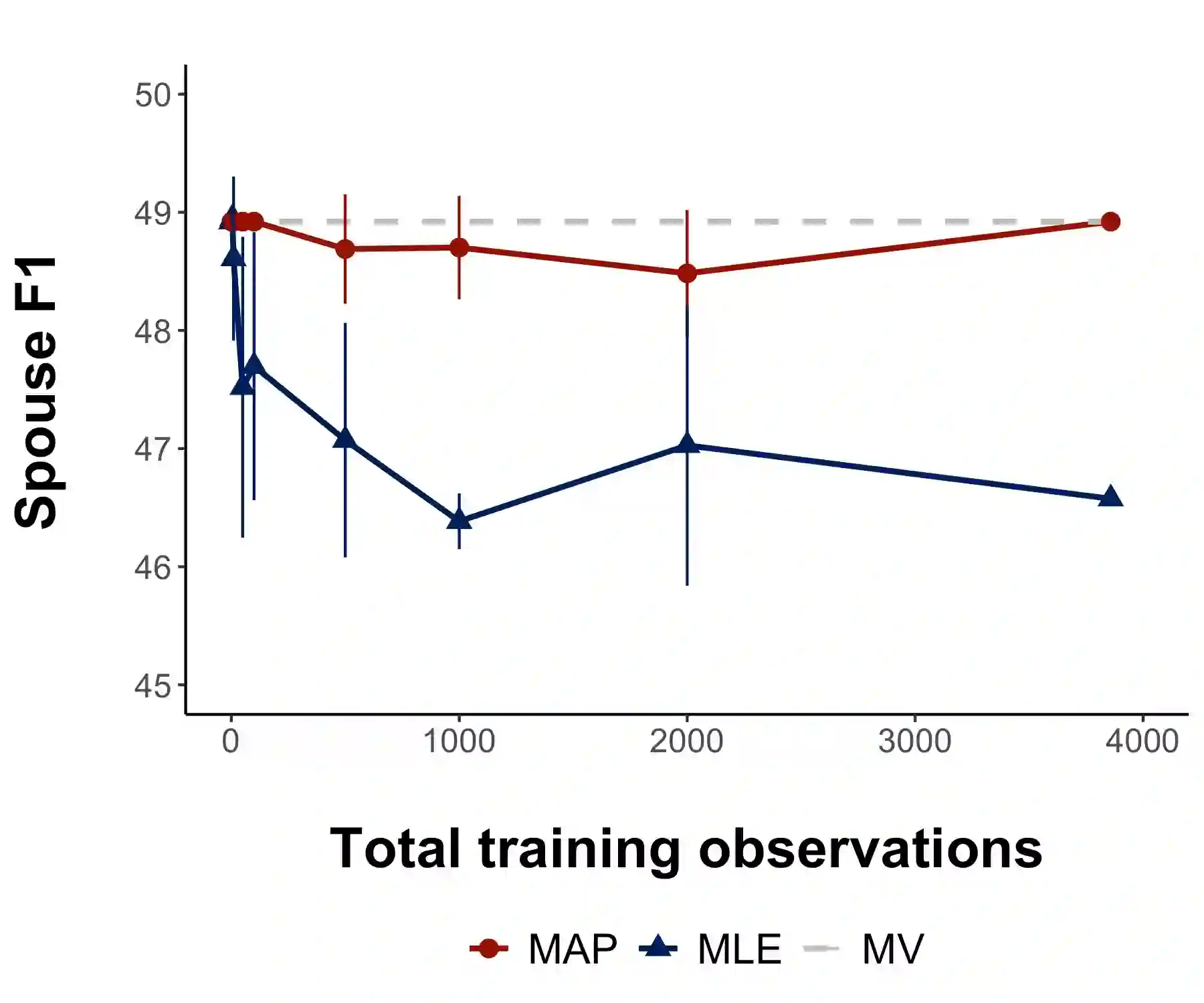
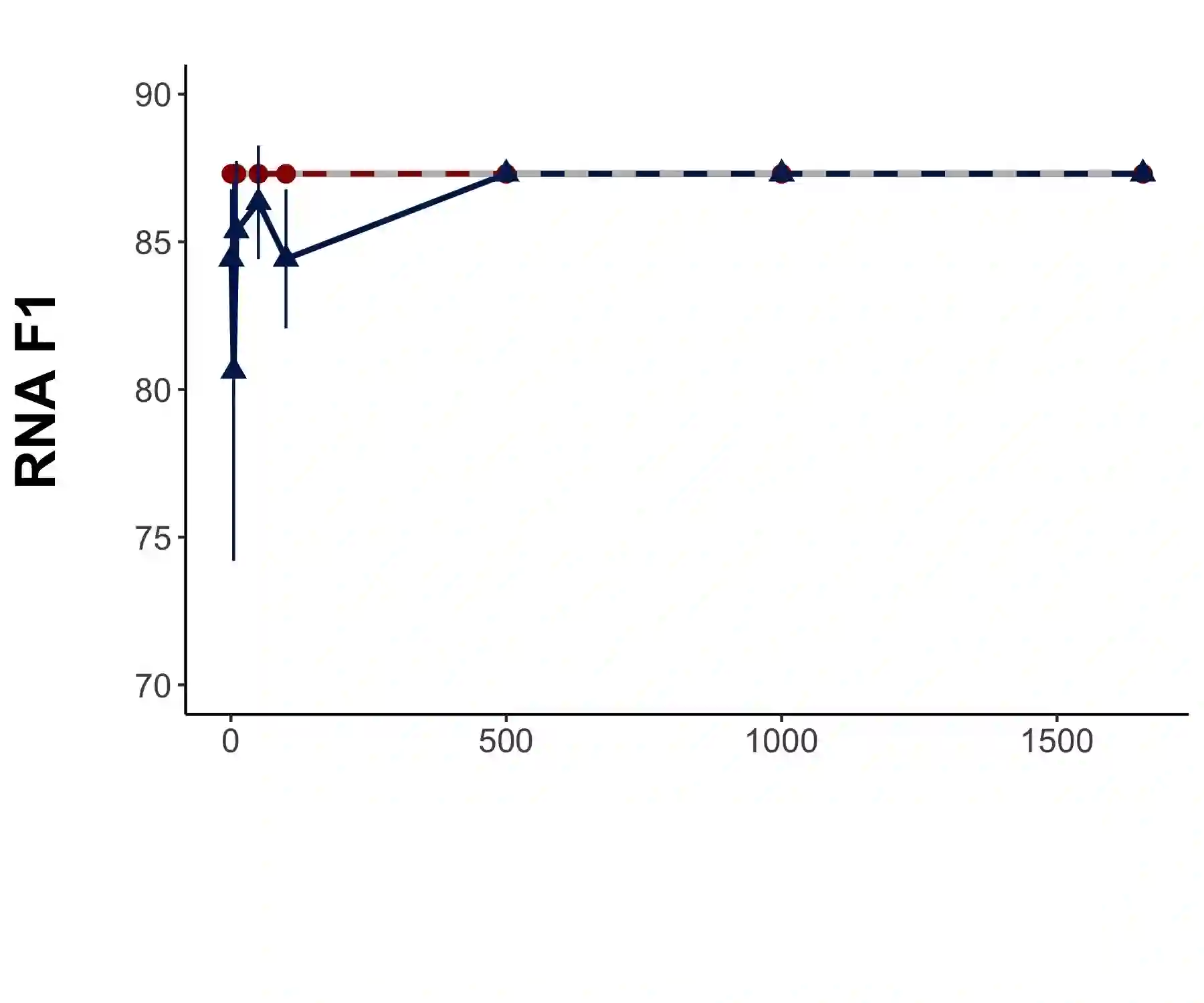
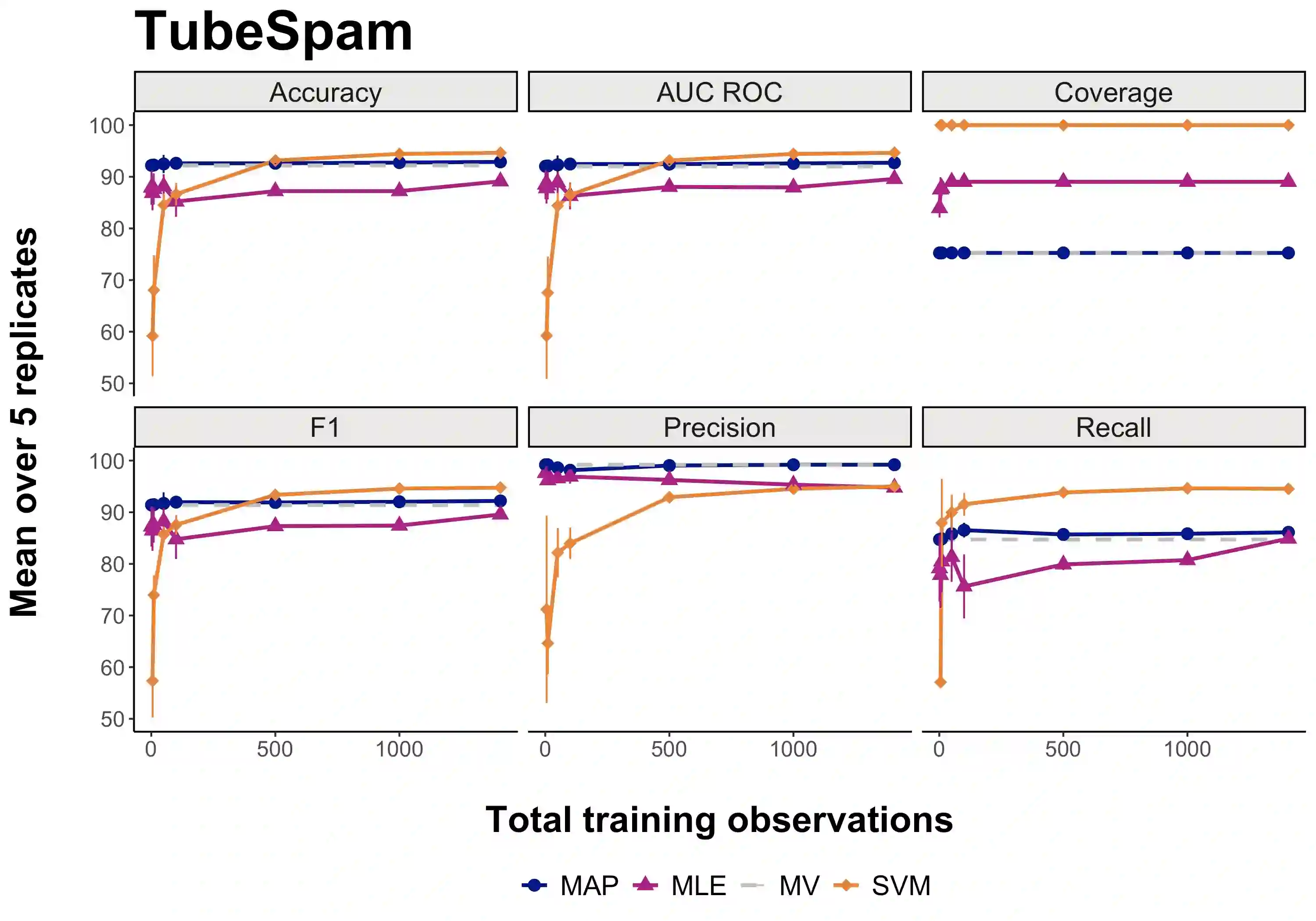
The cost of manual data labeling can be a significant obstacle in supervised learning. Data programming (DP) offers a weakly supervised solution for training dataset creation, wherein the outputs of user-defined programmatic labeling functions (LFs) are reconciled through unsupervised learning. However, DP can fail to outperform an unweighted majority vote in some scenarios, including low-data contexts. This work introduces a Bayesian extension of classical DP that mitigates failures of unsupervised learning by augmenting the DP objective with regularization terms. Regularized learning is achieved through maximum a posteriori estimation with informative priors. Majority vote is proposed as a proxy signal for automated prior parameter selection. Results suggest that regularized DP improves performance relative to maximum likelihood and majority voting, confers greater interpretability, and bolsters performance in low-data regimes.
翻译:暂无翻译