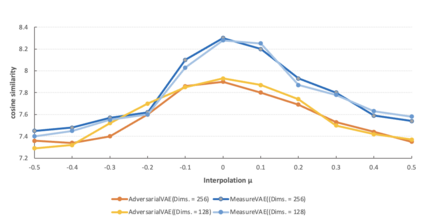
Generative AI models for music and the arts in general are increasingly complex and hard to understand. The field of eXplainable AI (XAI) seeks to make complex and opaque AI models such as neural networks more understandable to people. One approach to making generative AI models more understandable is to impose a small number of semantically meaningful attributes on generative AI models. This paper contributes a systematic examination of the impact that different combinations of Variational Auto-Encoder models (MeasureVAE and AdversarialVAE), configurations of latent space in the AI model (from 4 to 256 latent dimensions), and training datasets (Irish folk, Turkish folk, Classical, and pop) have on music generation performance when 2 or 4 meaningful musical attributes are imposed on the generative model. To date there have been no systematic comparisons of such models at this level of combinatorial detail. Our findings show that MeasureVAE has better reconstruction performance than AdversarialVAE which has better musical attribute independence. Results demonstrate that MeasureVAE was able to generate music across music genres with interpretable musical dimensions of control, and performs best with low complexity music such a pop and rock. We recommend that a 32 or 64 latent dimensional space is optimal for 4 regularised dimensions when using MeasureVAE to generate music across genres. Our results are the first detailed comparisons of configurations of state-of-the-art generative AI models for music and can be used to help select and configure AI models, musical features, and datasets for more understandable generation of music.
翻译:暂无翻译