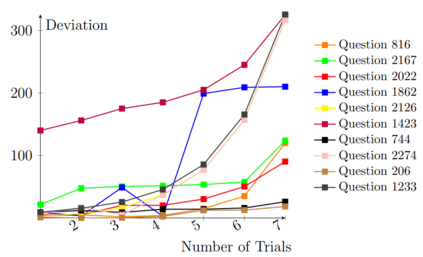
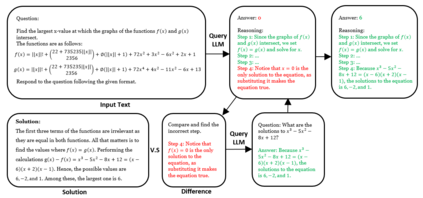
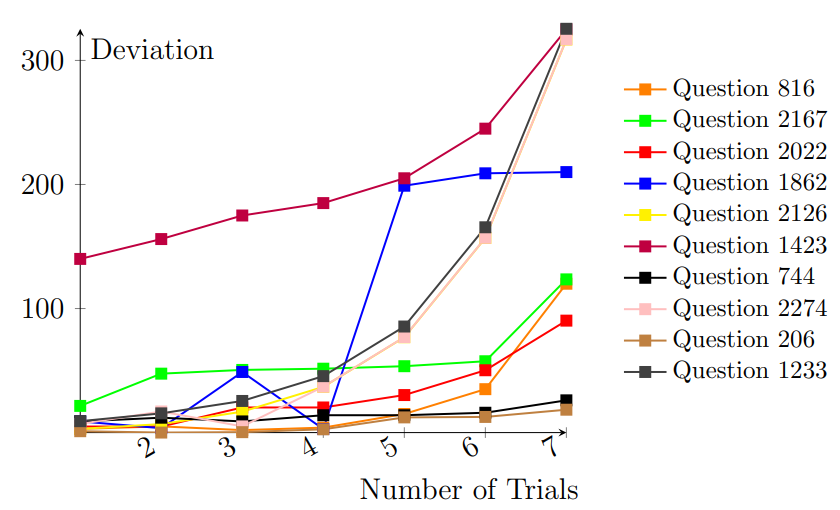
Large Language Models (LLMs) frequently struggle with complex reasoning tasks, failing to construct logically sound steps towards the solution. In response to this behavior, users often try prompting the LLMs repeatedly in hopes of reaching a better response. This paper studies such repetitive behavior and its effect by defining a novel setting, Chain-of-Feedback (CoF). The setting takes questions that require multi-step reasoning as an input. Upon response, we repetitively prompt meaningless feedback (e.g. 'make another attempt') requesting additional trials. Surprisingly, our preliminary results show that repeated meaningless feedback gradually decreases the quality of the responses, eventually leading to a larger deviation from the intended outcome. To alleviate these troubles, we propose a novel method, Recursive Chain-of-Feedback (R-CoF). Following the logic of recursion in computer science, R-CoF recursively revises the initially incorrect response by breaking down each incorrect reasoning step into smaller individual problems. Our preliminary results show that majority of questions that LLMs fail to respond correctly can be answered using R-CoF without any sample data outlining the logical process.
翻译:暂无翻译