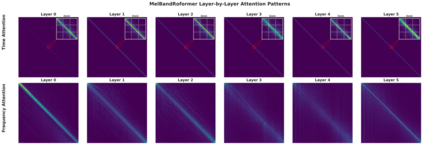
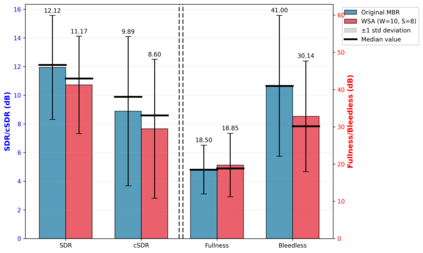
State-of-the-art vocal separation models like Mel-Band-Roformer rely on full temporal self-attention mechanisms, where each temporal frame interacts with every other frames. This incurs heavy computational costs that scales quadratically with input audio length, motivating chunking and windowing approaches. Through analysis of a pre-trained vocal separation model, we discovered that temporal attention patterns are highly localized. Building on this insight, we replaced full attention with windowed sink attention (WSA) with small temporal attention window and attention sinks. We show empirically that fine-tuning from the original checkpoint recovers 92% of the original SDR performance while reducing FLOPs by 44.5x. We release our code and checkpoints under MIT license at https://github.com/smulelabs/windowed-roformer.
翻译:暂无翻译