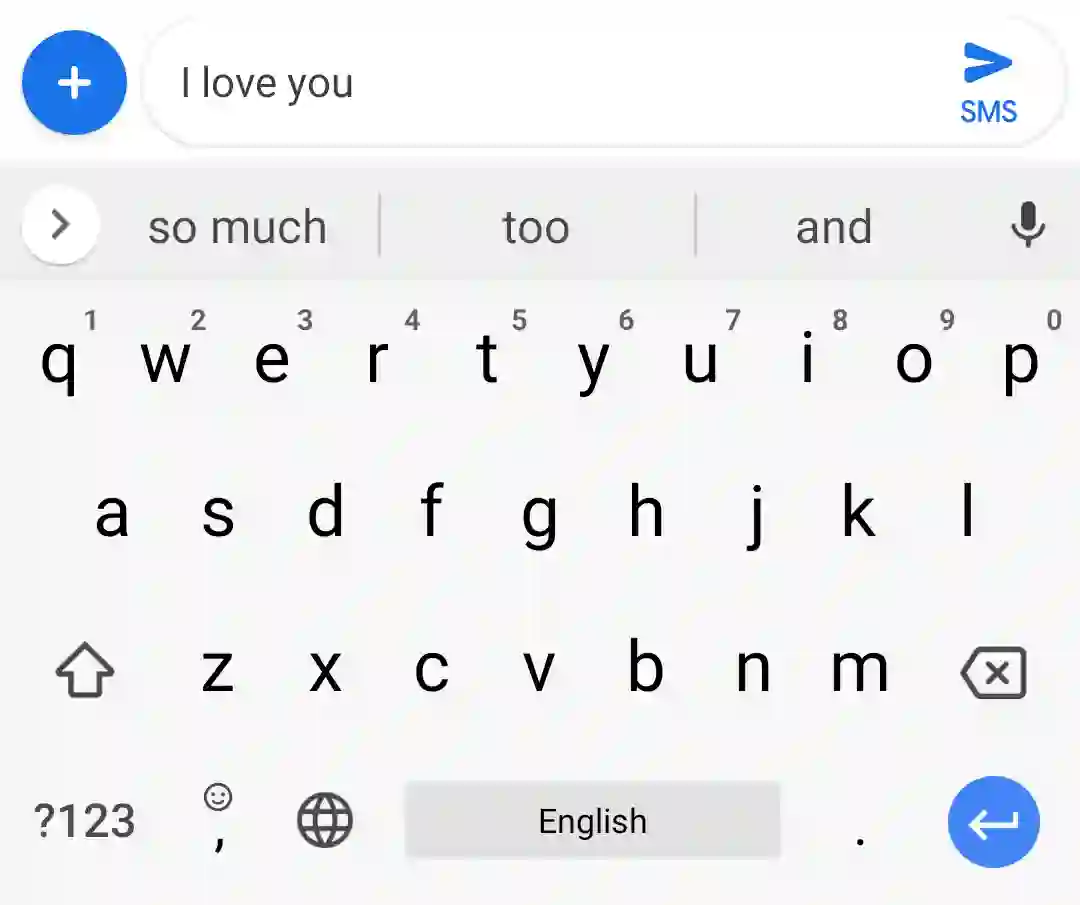
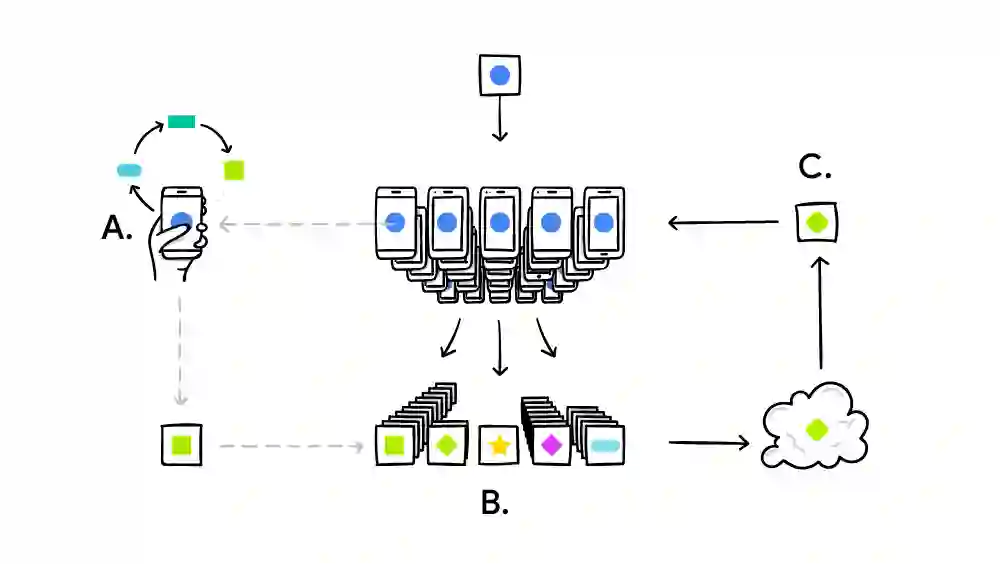
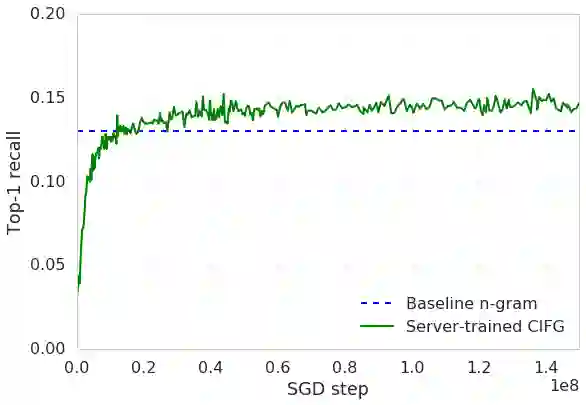
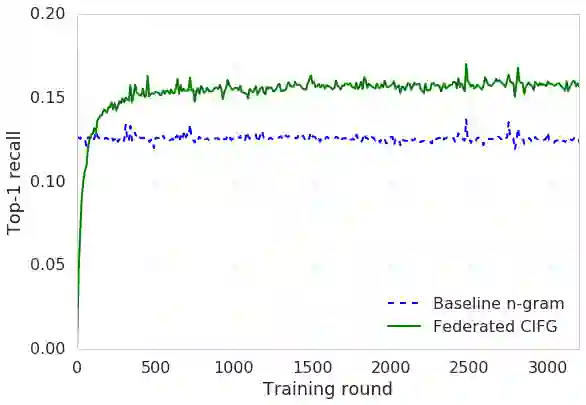
We train a recurrent neural network language model using a distributed, on-device learning framework called federated learning for the purpose of next-word prediction in a virtual keyboard for smartphones. Server-based training using stochastic gradient descent is compared with training on client devices using the Federated Averaging algorithm. The federated algorithm, which enables training on a higher-quality dataset for this use case, is shown to achieve better prediction recall. This work demonstrates the feasibility and benefit of training language models on client devices without exporting sensitive user data to servers. The federated learning environment gives users greater control over their data and simplifies the task of incorporating privacy by default with distributed training and aggregation across a population of client devices.
翻译:我们用一个分布式的、称为联合学习的在线学习框架来培训一个经常性神经网络语言模型,这个模型称为“联合学习”,目的是在智能手机虚拟键盘中进行下一个词的预测。使用随机梯度的基于服务器的培训与使用联邦算法的客户设备培训进行比较。联邦算法有助于为这一使用案例提供更高质量的数据集培训,显示这种计算法可以实现更好的预测回溯。这项工作表明在客户设备上培训语言模型的可行性和益处,而无需向服务器输出敏感的用户数据。联合学习环境使用户对其数据有更大的控制权,并简化了默认纳入隐私的任务,在用户设备人群中进行分布式培训和汇总。