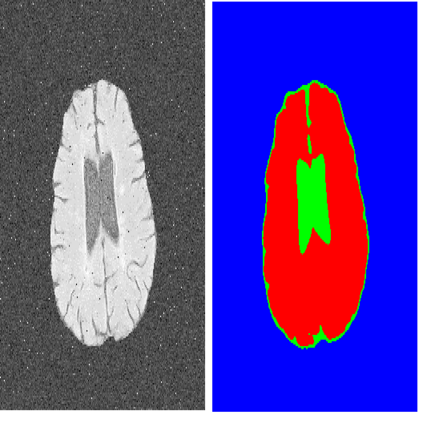
In this work we introduce CUTS (Contrastive and Unsupervised Training for Segmentation), a fully unsupervised deep learning framework for medical image segmentation to better utilize the vast majority of imaging data that is not labeled or annotated. We utilize self-supervision from pixels and their local neighborhoods in the images themselves. Our unsupervised approach optimizes a training objective that leverages concepts from contrastive learning and autoencoding. Our framework segments medical images with a novel two-stage approach without relying on any labeled data at any stage. The first stage involves the creation of a "pixel-centered patch" that embeds every pixel along with its surrounding patch, using a vector representation in a high-dimensional latent embedding space. The second stage utilizes diffusion condensation, a multi-scale topological data analysis approach, to dynamically coarse-grain these embedding vectors at all levels of granularity. The final outcome is a series of coarse-to-fine segmentations that highlight image structures at various scales. In this work, we show successful multi-scale segmentation on natural images, retinal fundus images, and brain MRI images. Our framework delineates structures and patterns at different scales which, in the cases of medical images, may carry distinct information relevant to clinical interpretation. Quantitatively, our framework demonstrates improvements ranging from 10% to 200% on dice coefficient and Hausdorff distance compared to existing unsupervised methods across three medical image datasets. As we tackle the problem of segmenting medical images at multiple meaningful granularities without relying on any label, we hope to demonstrate the possibility to circumvent tedious and repetitive manual annotations in future practice.
翻译:暂无翻译