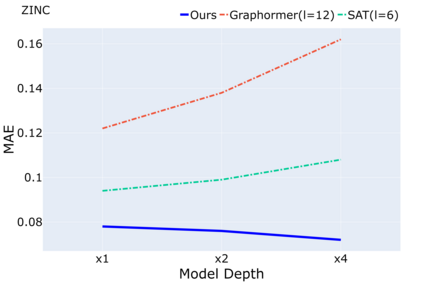
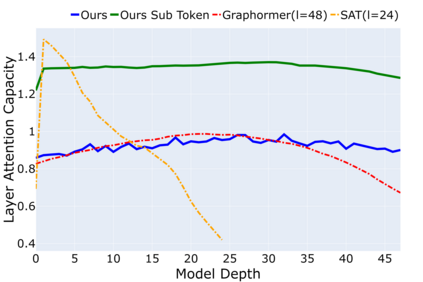
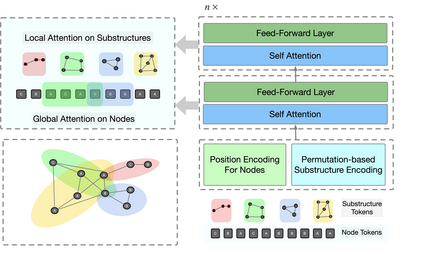
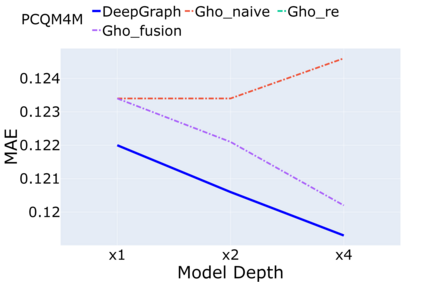
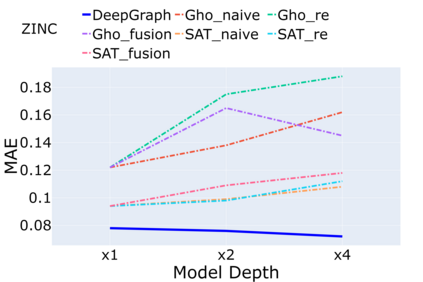
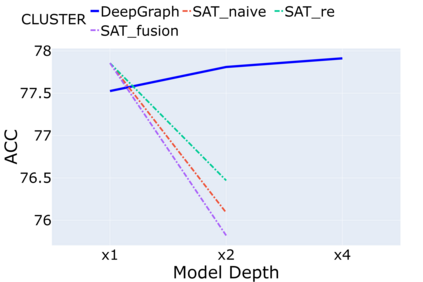
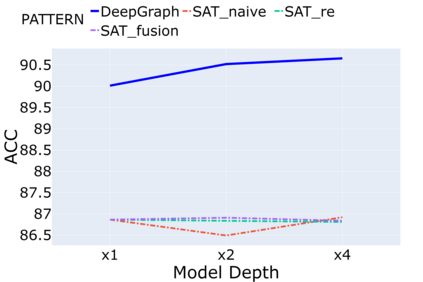
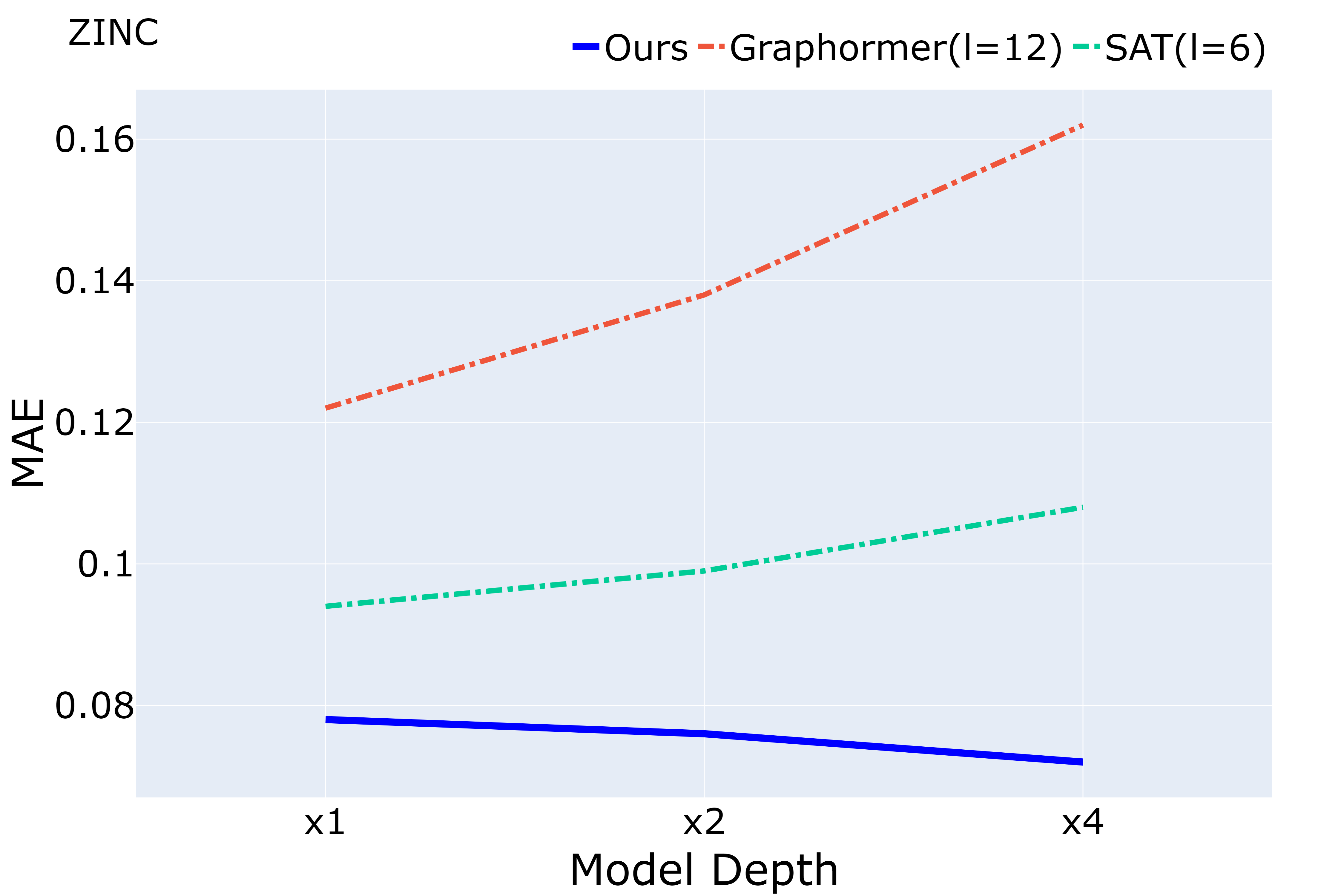
Despite that going deep has proven successful in many neural architectures, the existing graph transformers are relatively shallow. In this work, we explore whether more layers are beneficial to graph transformers, and find that current graph transformers suffer from the bottleneck of improving performance by increasing depth. Our further analysis reveals the reason is that deep graph transformers are limited by the vanishing capacity of global attention, restricting the graph transformer from focusing on the critical substructure and obtaining expressive features. To this end, we propose a novel graph transformer model named DeepGraph that explicitly employs substructure tokens in the encoded representation, and applies local attention on related nodes to obtain substructure based attention encoding. Our model enhances the ability of the global attention to focus on substructures and promotes the expressiveness of the representations, addressing the limitation of self-attention as the graph transformer deepens. Experiments show that our method unblocks the depth limitation of graph transformers and results in state-of-the-art performance across various graph benchmarks with deeper models.
翻译:尽管深度变压器在许多神经结构中证明是成功的,但现有的图形变压器相对而言是相对浅的。在这项工作中,我们探索更多的层层是否有益于图形变压器,并发现目前的图形变压器由于深度的提高而面临性能改善的瓶颈。我们进一步的分析表明,深图变压器由于全球注意力的消失而受到限制,从而限制了图形变压器对关键亚结构的注意力并获得显性特征。为此,我们提议了一个名为DeepGraph的新的图形变压器模型,在编码代表中明确使用亚结构符号,并在相关节点上应用当地注意力,以获得基于注意的子结构编码。我们的模型提高了全球注意力对子结构的关注能力,并促进了表态的清晰度,在图形变压变压器深化时解决了自我关注的局限性。实验表明,我们的方法排除了图形变压器的深度限制,并导致以更深的模型在各种图表基准中达到最新水平的性能。</s>