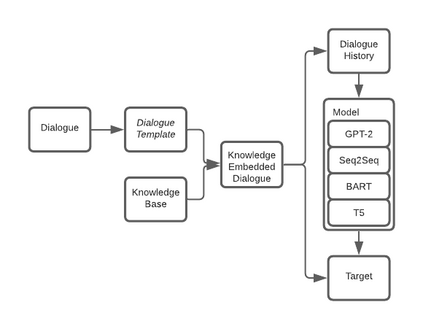
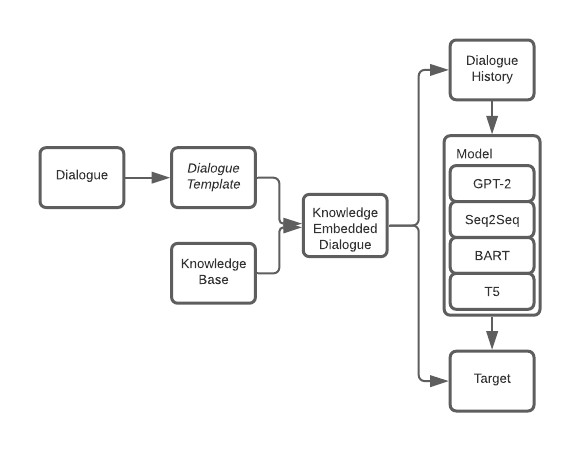
The recent development of language models has shown promising results by achieving state-of-the-art performance on various natural language tasks by fine-tuning pretrained models. In task-oriented dialogue (ToD) systems, language models can be used for end-to-end training without relying on dialogue state tracking to track the dialogue history but allowing the language models to generate responses according to the context given as input. This paper conducts a comparative study to show the effectiveness and strength of using recent pretrained models for fine-tuning, such as BART and T5, on endto-end ToD systems. The experimental results show substantial performance improvements after language model fine-tuning. The models produce more fluent responses after adding knowledge to the context that guides the model to avoid hallucination and generate accurate entities in the generated responses. Furthermore, we found that BART and T5 outperform GPT-based models in BLEU and F1 scores and achieve state-of-the-art performance in a ToD system.
翻译:最近开发的语言模式通过微调预先培训模式,在各种自然语言任务方面取得最新业绩,显示了有希望的成果。在面向任务的对话(ToD)系统中,语言模式可用于端对端培训,而不必依靠对话国家跟踪跟踪对话历史,而是允许语言模式根据作为投入提供的背景作出响应。本文进行了一项比较研究,以显示在终端到终端的TOD系统中使用诸如BART和T5等最新预先培训的微调模式的有效性和实力。实验结果显示在语言模型微调之后,绩效有很大的改进。这些模型在为模型提供知识以避免幻觉和在生成的响应中产生准确的实体之后,产生了更流畅的响应。此外,我们发现BART和T5在BLEU和F1分中超越了基于GPT的模型,在TOD系统中实现了最先进的业绩。