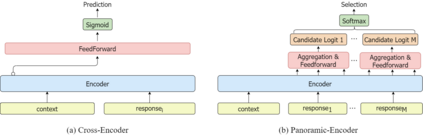
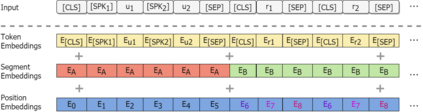
Response selector is an essential component of generation-based dialogue systems and it aims to pick out an optimal response in a candidate pool to continue the dialogue. The current state-of-the-art methods are mainly based on the encoding paradigm called Cross-Encoder, which separately encodes each context-response pair and ranks the responses according to their fitness scores. However, Cross-Encoder repeatedly encodes the same lengthy context for each response, resulting in high computational costs. Moreover, without considering the relationship among the candidates, it is difficult to figure out which candidate is the best response purely based on the fitness score per candidate. We aim to address these problems through a new paradigm called Panoramic-Encoder. The proposed method encodes all candidates and the context at once and realizes the mutual interaction using a tailored candidate attention mechanism (CAM). It also enables the integration of some effective training techniques, such as the in-batch negative training, which cannot be used in Cross-Encoders. Extensive experiments across four benchmark datasets show that our new method significantly outperforms the current state-of-the-art with lower computational complexity.
翻译:反应选择器是新一代对话系统的一个基本组成部分,目的是在候选人人才库中选择最佳反应,以继续对话。目前最先进的方法主要基于名为Cross-Encoder的编码范式,该范式分别编码每个背景对应对,并根据每个响应的得分进行排序。不过,交叉编码器反复编码每个响应的同样长的背景,从而导致高计算成本。此外,不考虑候选人之间的关系,很难完全根据每个候选人的健康状况评分来确定哪个候选人是最佳反应。我们的目标是通过称为全景-Encoder的新范式来解决这些问题。拟议的方法一次性编码所有候选人和背景,并使用量身定制的候选人注意机制(CAM)实现相互互动。它也能够整合一些有效的培训技术,例如无法在交叉计算器中使用的全场负面培训。四个基准数据集的大规模实验表明,我们的新方法大大超越了当前状态的计算复杂性。