【论文推荐】最新五篇信息抽取相关论文—端到端深度模型、调研、聊天机器人、自注意力、科学文本
【导读】专知内容组整理了最近五篇信息抽取(Information Extraction)相关文章,为大家进行介绍,欢迎查看!
1.Joint Recognition of Handwritten Text and Named Entities with a Neural End-to-end Model(联合识别手写文本和命名实体的神经端到端模型)
作者:Manuel Carbonell,Mauricio Villegas,Alicia Fornés,Josep Lladós
机构:Universitat Autonoma de Barcelona
摘要:When extracting information from handwritten documents, text transcription and named entity recognition are usually faced as separate subsequent tasks. This has the disadvantage that errors in the first module affect heavily the performance of the second module. In this work we propose to do both tasks jointly, using a single neural network with a common architecture used for plain text recognition. Experimentally, the work has been tested on a collection of historical marriage records. Results of experiments are presented to show the effect on the performance for different configurations: different ways of encoding the information, doing or not transfer learning and processing at text line or multi-line region level. The results are comparable to state of the art reported in the ICDAR 2017 Information Extraction competition, even though the proposed technique does not use any dictionaries, language modeling or post processing.
期刊:arXiv, 2018年3月22日
网址:
http://www.zhuanzhi.ai/document/405e5ad2a65e3478bd8daefaecce66c4
2.A Study of Recent Contributions on Information Extraction(最近对信息抽取贡献的研究)
作者:Parisa Naderi Golshan,HosseinAli Rahmani Dashti,Shahrzad Azizi,Leila Safari
机构:University of Zanjan
摘要:This paper reports on modern approaches in Information Extraction (IE) and its two main sub-tasks of Named Entity Recognition (NER) and Relation Extraction (RE). Basic concepts and the most recent approaches in this area are reviewed, which mainly include Machine Learning (ML) based approaches and the more recent trend to Deep Learning (DL) based methods.

期刊:arXiv, 2018年3月15日
网址:
http://www.zhuanzhi.ai/document/e5443931df3df6ed0252157f9df8e3e9
3.DeepProbe: Information Directed Sequence Understanding and Chatbot Design via Recurrent Neural Networks(通过递归神经网络对信息进行顺序理解和聊天机器人设计)
作者:Zi Yin,Keng-hao Chang,Ruofei Zhang
机构:Stanford University
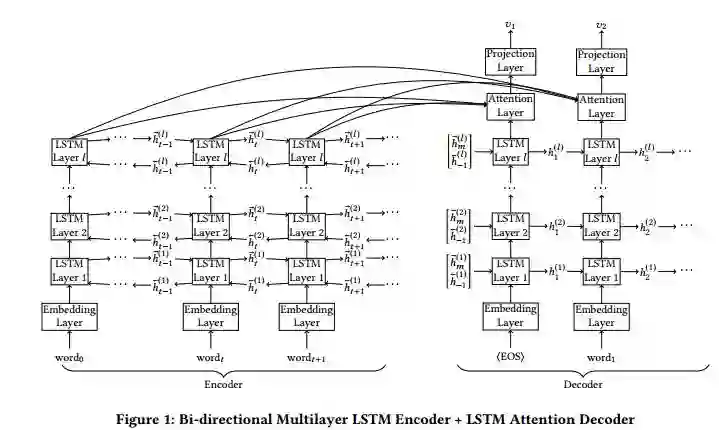
摘要:Information extraction and user intention identification are central topics in modern query understanding and recommendation systems. In this paper, we propose DeepProbe, a generic information-directed interaction framework which is built around an attention-based sequence to sequence (seq2seq) recurrent neural network. DeepProbe can rephrase, evaluate, and even actively ask questions, leveraging the generative ability and likelihood estimation made possible by seq2seq models. DeepProbe makes decisions based on a derived uncertainty (entropy) measure conditioned on user inputs, possibly with multiple rounds of interactions. Three applications, namely a rewritter, a relevance scorer and a chatbot for ad recommendation, were built around DeepProbe, with the first two serving as precursory building blocks for the third. We first use the seq2seq model in DeepProbe to rewrite a user query into one of standard query form, which is submitted to an ordinary recommendation system. Secondly, we evaluate DeepProbe's seq2seq model-based relevance scoring. Finally, we build a chatbot prototype capable of making active user interactions, which can ask questions that maximize information gain, allowing for a more efficient user intention idenfication process. We evaluate first two applications by 1) comparing with baselines by BLEU and AUC, and 2) human judge evaluation. Both demonstrate significant improvements compared with current state-of-the-art systems, proving their values as useful tools on their own, and at the same time laying a good foundation for the ongoing chatbot application.
期刊:arXiv, 2018年3月2日
网址:
http://www.zhuanzhi.ai/document/92aa72b24c3a8b2ce47ba6fe3a64c101
4.Simultaneously Self-Attending to All Mentions for Full-Abstract Biological Relation Extraction(基于同时自注意力对所有提及的全抽象生物关系进行提取)
作者:Patrick Verga,Emma Strubell,Andrew McCallum
机构:College of Information and Computer Sciences
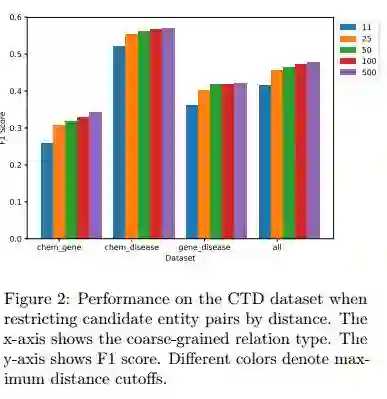
摘要:Most work in relation extraction forms a prediction by looking at a short span of text within a single sentence containing a single entity pair mention. This approach often does not consider interactions across mentions, requires redundant computation for each mention pair, and ignores relationships expressed across sentence boundaries. These problems are exacerbated by the document- (rather than sentence-) level annotation common in biological text. In response, we propose a model which simultaneously predicts relationships between all mention pairs in a document. We form pairwise predictions over entire paper abstracts using an efficient self-attention encoder. All-pairs mention scores allow us to perform multi-instance learning by aggregating over mentions to form entity pair representations. We further adapt to settings without mention-level annotation by jointly training to predict named entities and adding a corpus of weakly labeled data. In experiments on two Biocreative benchmark datasets, we achieve state of the art performance on the Biocreative V Chemical Disease Relation dataset for models without external KB resources. We also introduce a new dataset an order of magnitude larger than existing human-annotated biological information extraction datasets and more accurate than distantly supervised alternatives.
期刊:arXiv, 2018年3月1日
网址:
http://www.zhuanzhi.ai/document/72c37f74f12ed6c63b4b38291ccb88c3
5.Open Information Extraction on Scientific Text: An Evaluation(科学文本的公开信息提取:一次评估)
作者:Paul Groth,Michael Lauruhn,Antony Scerri,Ron Daniel Jr
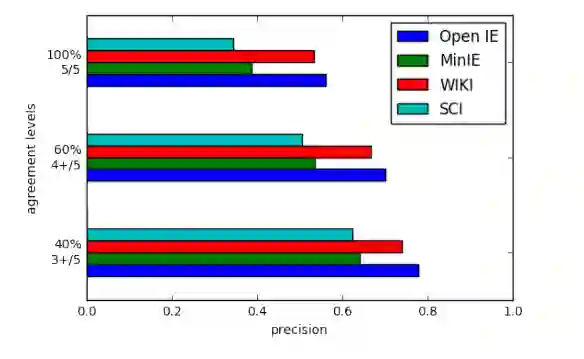
摘要:Open Information Extraction (OIE) is the task of the unsupervised creation of structured information from text. OIE is often used as a starting point for a number of downstream tasks including knowledge base construction, relation extraction, and question answering. While OIE methods are targeted at being domain independent, they have been evaluated primarily on newspaper, encyclopedic or general web text. In this article, we evaluate the performance of OIE on scientific texts originating from 10 different disciplines. To do so, we use two state-of-the-art OIE systems applying a crowd-sourcing approach. We find that OIE systems perform significantly worse on scientific text than encyclopedic text. We also provide an error analysis and suggest areas of work to reduce errors. Our corpus of sentences and judgments are made available.
期刊:arXiv, 2018年2月15日
网址:
http://www.zhuanzhi.ai/document/4d9ca1589e7722cb8a8f4d90138d3a9e
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
点击“阅读原文”,使用专知!



