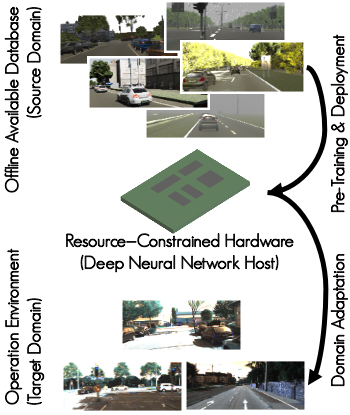
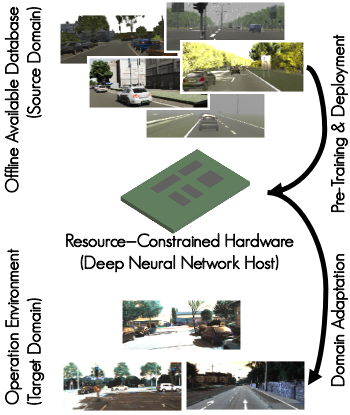
Real-world perception systems in many cases build on hardware with limited resources to adhere to cost and power limitations of their carrying system. Deploying deep neural networks on resource-constrained hardware became possible with model compression techniques, as well as efficient and hardware-aware architecture design. However, model adaptation is additionally required due to the diverse operation environments. In this work, we address the problem of training deep neural networks on resource-constrained hardware in the context of visual domain adaptation. We select the task of monocular depth estimation where our goal is to transform a pre-trained model to the target's domain data. While the source domain includes labels, we assume an unlabelled target domain, as it happens in real-world applications. Then, we present an adversarial learning approach that is adapted for training on the device with limited resources. Since visual domain adaptation, i.e. neural network training, has not been previously explored for resource-constrained hardware, we present the first feasibility study for image-based depth estimation. Our experiments show that visual domain adaptation is relevant only for efficient network architectures and training sets at the order of a few hundred samples. Models and code are publicly available.
翻译:在很多情况下,现实世界感知系统建立在资源有限的硬件之上,以遵守携带系统的成本和功率限制。在资源受限制的硬件上部署深神经网络,随着模型压缩技术以及高效和硬件智能建筑设计而成为可能。然而,由于操作环境不同,模型改造是额外需要的。在这项工作中,我们处理的问题是在视觉领域适应方面对资源受限制的硬件进行深神经网络培训的问题。我们选择单眼深度估算的任务,我们的目标是将预先培训的模式转换成目标的域数据。虽然源域包括标签,但我们假设一个未加标签的目标域,正如在现实世界应用中发生的那样。然后,我们提出一种对抗性学习方法,经过调整后用于在资源有限的装置上进行培训。由于视觉领域适应,即神经网络培训以前没有在资源受限制的硬件方面进行探索,我们提出了第一个基于图像深度估算的可行性研究。我们的实验显示,视觉域适应仅与高效的网络架构和培训组合有关,只有几百个样本的顺序。模型和代码是公开提供的。