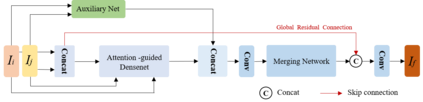
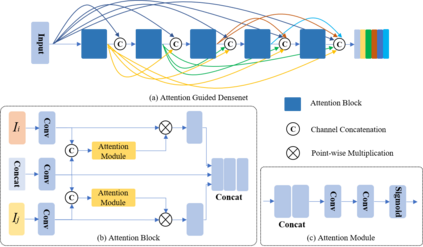
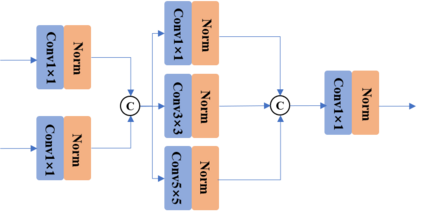
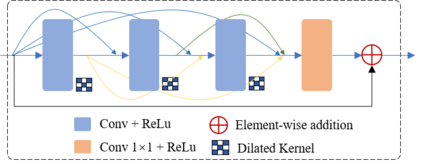
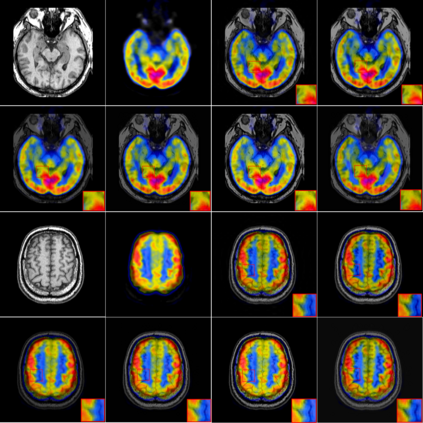
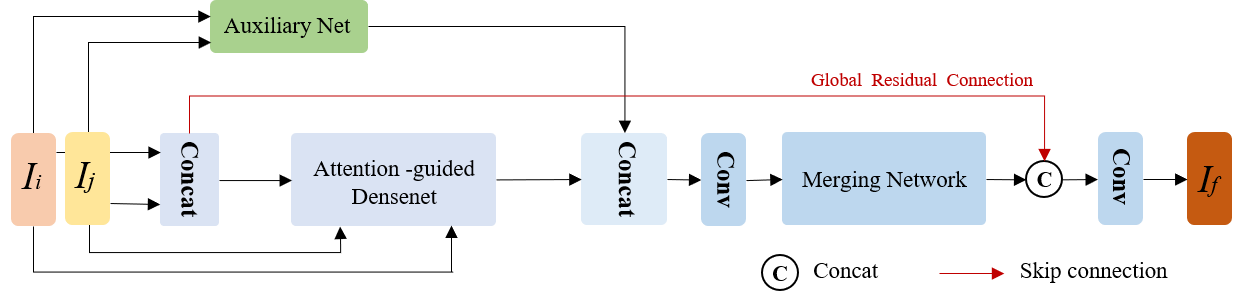
In recent years, various applications in computer vision have achieved substantial progress based on deep learning, which has been widely used for image fusion and shown to achieve adequate performance. However, suffering from limited ability in modelling the spatial correspondence of different source images, it still remains a great challenge for existing unsupervised image fusion models to extract appropriate feature and achieves adaptive and balanced fusion. In this paper, we propose a novel cross attention-guided image fusion network, which is a unified and unsupervised framework for multi-modal image fusion, multi-exposure image fusion, and multi-focus image fusion. Different from the existing self-attention module, our cross attention module focus on modelling the cross-correlation between different source images. Using the proposed cross attention module as core block, a densely connected cross attention-guided network is built to dynamically learn the spatial correspondence to derive better alignment of important details from different input images. Meanwhile, an auxiliary branch is also designed to model the long-range information, and a merging network is attached to finally reconstruct the fusion image. Extensive experiments have been carried out on publicly available datasets, and the results demonstrate that the proposed model outperforms the state-of-the-art quantitatively and qualitatively.
翻译:近年来,计算机视觉中的各种应用在深层次学习的基础上取得了长足进步,这种深层次学习被广泛用于图像融合,并显示能够取得适当的性能。然而,由于在模拟不同源图像的空间对应关系方面能力有限,在建模不同源图像的空间对应关系方面,计算机视觉中的各种应用仍然对现有的未经监督的图像融合模型构成巨大挑战,以提取适当的特征并实现适应性和平衡的融合。在本文件中,我们建议建立一个新的交叉关注引导图像融合网络,这是多模式图像融合、多接触图像融合和多重点图像融合的统一和不受监督的框架。与现有的自我关注模块不同,我们的交叉关注模块侧重于建模不同源图像之间的交叉关系。利用拟议的交叉关注模块作为核心块,构建了一个紧密相连的交叉关注引导网络,动态地学习空间通信,以更好地对不同输入图像的重要细节进行匹配。与此同时,还设计了一个辅助分支,以模拟远程信息,并将一个合并网络作为最终重建聚合图像的附加。在公开可用的数据配置和定性上进行了广泛的实验,并展示了拟议的模型的定性和定性结果。