
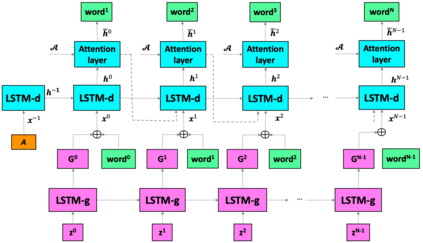
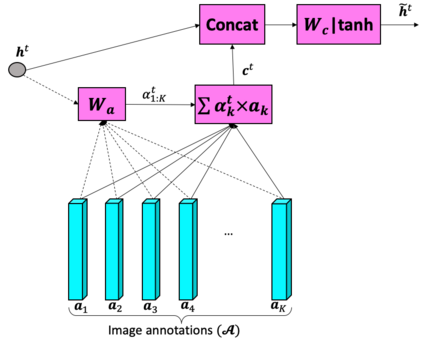
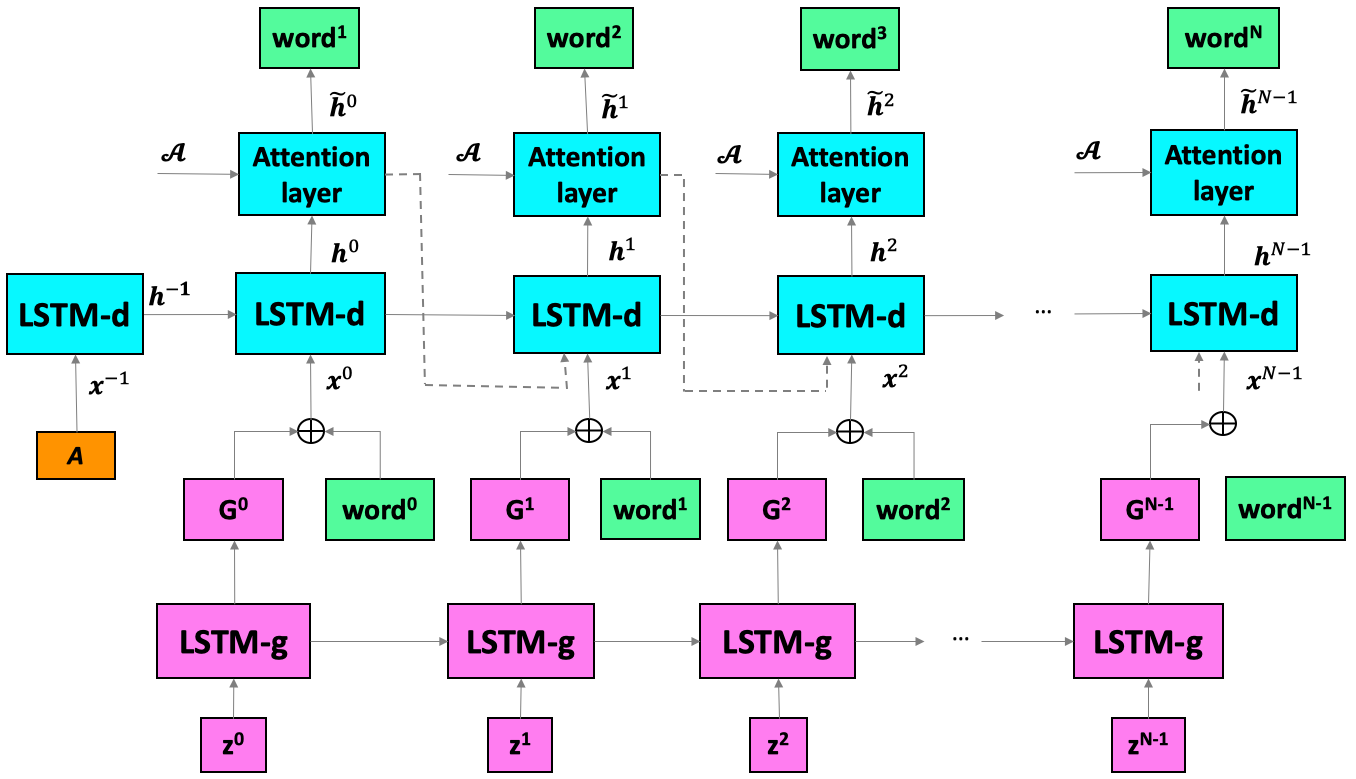
The recent advances of deep learning in both computer vision (CV) and natural language processing (NLP) provide us a new way of understanding semantics, by which we can deal with more challenging tasks such as automatic description generation from natural images. In this challenge, the encoder-decoder framework has achieved promising performance when a convolutional neural network (CNN) is used as image encoder and a recurrent neural network (RNN) as decoder. In this paper, we introduce a sequential guiding network that guides the decoder during word generation. The new model is an extension of the encoder-decoder framework with attention that has an additional guiding long short-term memory (LSTM) and can be trained in an end-to-end manner by using image/descriptions pairs. We validate our approach by conducting extensive experiments on a benchmark dataset, i.e., MS COCO Captions. The proposed model achieves significant improvement comparing to the other state-of-the-art deep learning models.
翻译:最近在计算机视觉和自然语言处理(NLP)方面的深层次学习进展为我们提供了一种新的理解语义学的方法,通过这种方式,我们可以处理更具有挑战性的任务,例如从自然图像自动描述生成。在这项挑战中,当结合神经神经网络(CNN)被用作图像编码器和经常神经网络(RNN)用作解码器时,编码器框架取得了有希望的绩效。在本文件中,我们引入了一个连续的指导网络,指导了文字生成过程中的解码器。新模式是编码器-解码框架的延伸,它具有额外的短期内存指导性,并且可以通过使用图像/描述配对进行端端培训。我们通过在基准数据集上进行广泛的实验,即MSCOCCaptions,验证了我们的方法。与其它最先进的深层学习模式相比,拟议模型取得了显著的改进。
相关内容

- Today (iOS and OS X): widgets for the Today view of Notification Center
- Share (iOS and OS X): post content to web services or share content with others
- Actions (iOS and OS X): app extensions to view or manipulate inside another app
- Photo Editing (iOS): edit a photo or video in Apple's Photos app with extensions from a third-party apps
- Finder Sync (OS X): remote file storage in the Finder with support for Finder content annotation
- Storage Provider (iOS): an interface between files inside an app and other apps on a user's device
- Custom Keyboard (iOS): system-wide alternative keyboards
Source: iOS 8 Extensions: Apple’s Plan for a Powerful App Ecosystem



