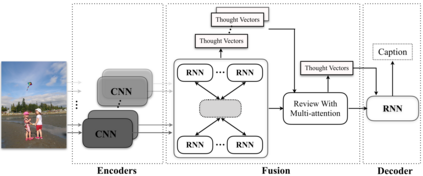
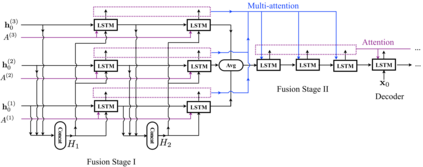
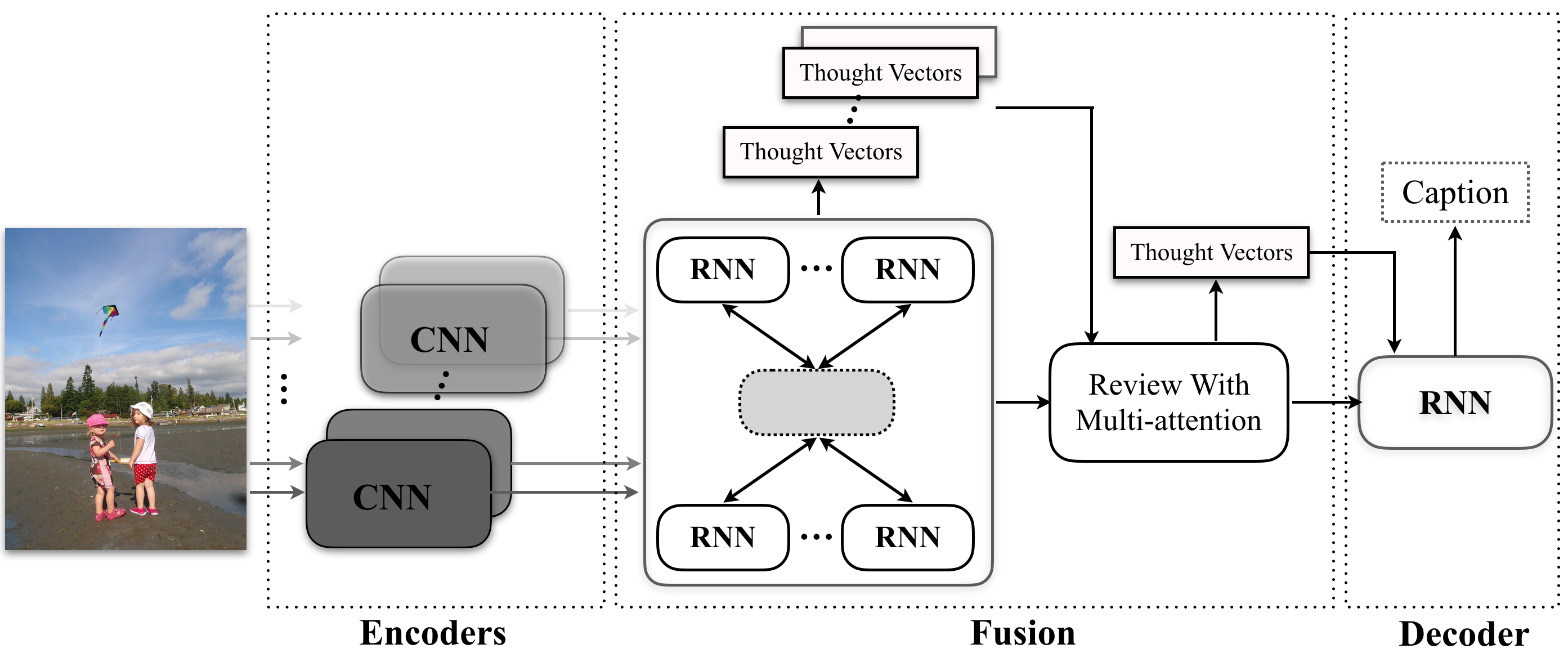
Recently, much advance has been made in image captioning, and an encoder-decoder framework has been adopted by all the state-of-the-art models. Under this framework, an input image is encoded by a convolutional neural network (CNN) and then translated into natural language with a recurrent neural network (RNN). The existing models counting on this framework merely employ one kind of CNNs, e.g., ResNet or Inception-X, which describe image contents from only one specific view point. Thus, the semantic meaning of an input image cannot be comprehensively understood, which restricts the performance of captioning. In this paper, in order to exploit the complementary information from multiple encoders, we propose a novel Recurrent Fusion Network (RFNet) for tackling image captioning. The fusion process in our model can exploit the interactions among the outputs of the image encoders and then generate new compact yet informative representations for the decoder. Experiments on the MSCOCO dataset demonstrate the effectiveness of our proposed RFNet, which sets a new state-of-the-art for image captioning.
翻译:最近,在图像字幕方面已经取得了很大进步,所有最先进的模型都采用了编码器解码器框架。在这个框架内,输入图像由一个神经神经网络(CNN)编码,然后与一个经常性神经网络(RNN)翻译成自然语言。基于这个框架的现有模型仅仅使用一种CNN,例如ResNet 或 Inception-X,它们只描述一个特定观点的图像内容。因此,输入图像的语义含义无法被全面理解,这限制了字幕的性能。在本文中,为了利用多个编码器的辅助信息,我们建议建立一个新的常规拼图网络(RFNet),以处理图像说明。我们模型中的聚合过程可以利用图像编码器输出器的相互作用,然后为解码器生成新的、但又具有信息性的缩写方式。对MSCOCO数据集的实验展示了我们提议的RFNet的有效性,它设置了一个新的图像说明的状态。