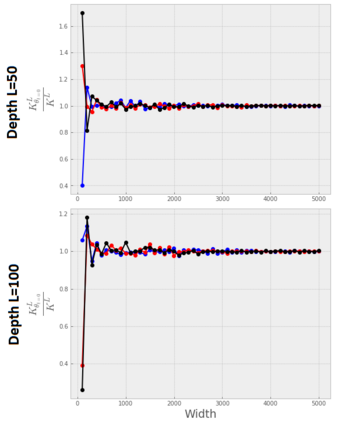
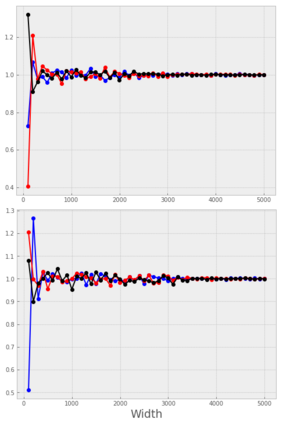
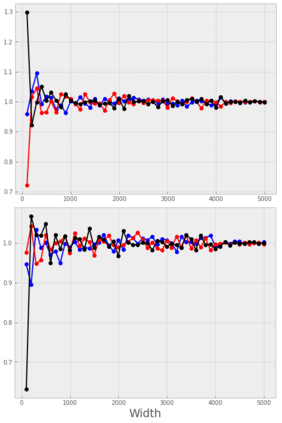
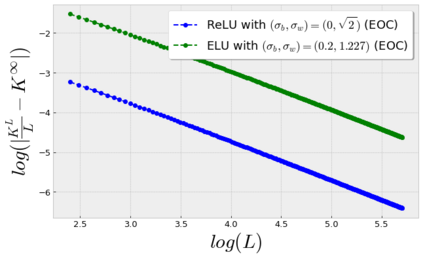
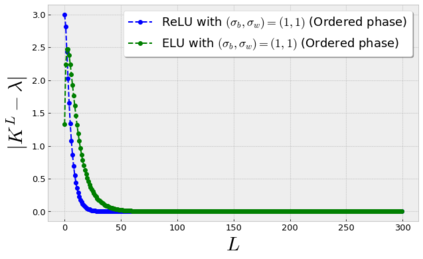
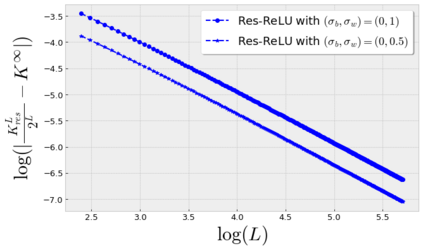
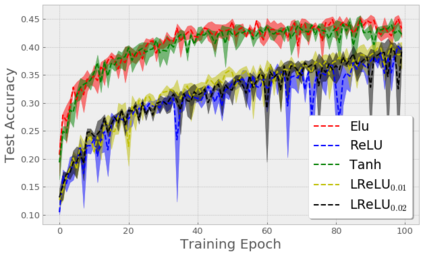
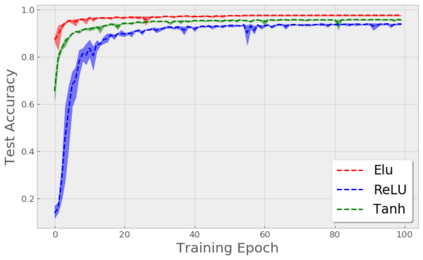
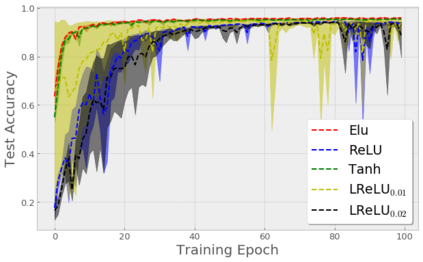
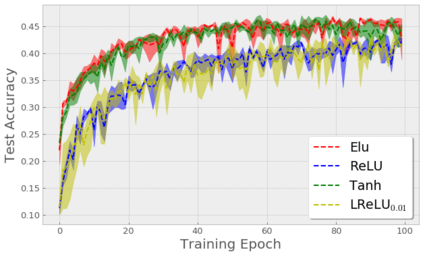
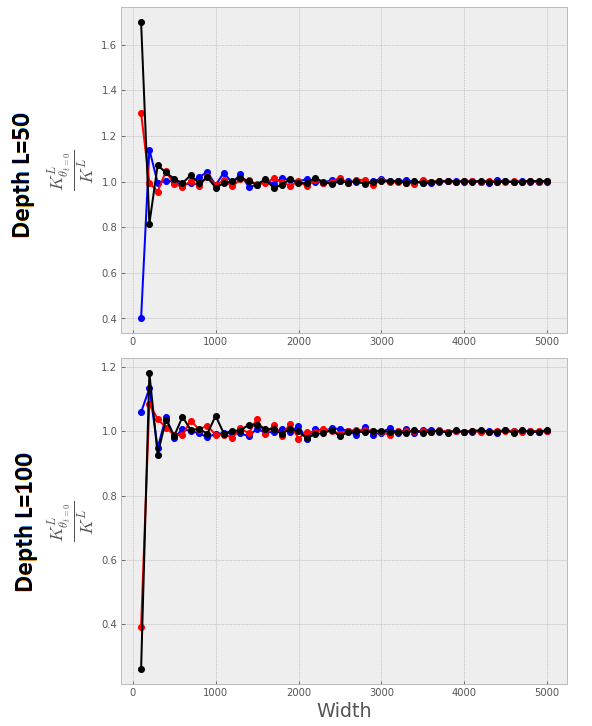
Stochastic Gradient Descent (SGD) is widely used to train deep neural networks. However, few theoretical results on the training dynamics of SGD are available. Recent work by Jacot et al. (2018) has showed that training a neural network of any kind with a full batch gradient descent in parameter space is equivalent to kernel gradient descent in function space with respect to the Neural Tangent Kernel (NTK). Lee et al. (2019) built on this result to show that the output of a neural network trained using full batch gradient descent can be approximated by a linear model for wide neural networks. We show here how these results can be extended to SGD. In this case, the resulting training dynamics is given by a stochastic differential equation dependent on the NTK which becomes a simple mean-reverting process for the squared loss. When the network depth is also large, we provide a comprehensive analysis on the impact of the initialization and the activation function on the NTK, and thus on the corresponding training dynamics under SGD. We provide experiments illustrating our theoretical results.
翻译:218. 然而,关于SGD培训动态的理论结果很少。 Jacot等人(2018年)最近的工作表明,在参数空间中,对具有完全分批梯度下降的神经网络进行培训,相当于在神经唐氏中枢(NTK)的功能空间中,内核梯度下降。 Lee等人(2019年)以这一结果为基础,表明利用全批梯度梯度下降进行训练的神经网络的输出可以通过宽度神经网络的线性模型进行近似。我们在这里展示这些结果如何能够扩展到SGD。在这种情况下,所产生的培训动态由依赖于NTK的微分差异方程式提供,该方程式成为平方位损失的一个简单的中位反转过程。当网络深度也很大时,我们全面分析初始化和激活功能对NTK的影响,从而对SGD下的相应培训动态的影响。我们提供实验,说明我们的理论结果。