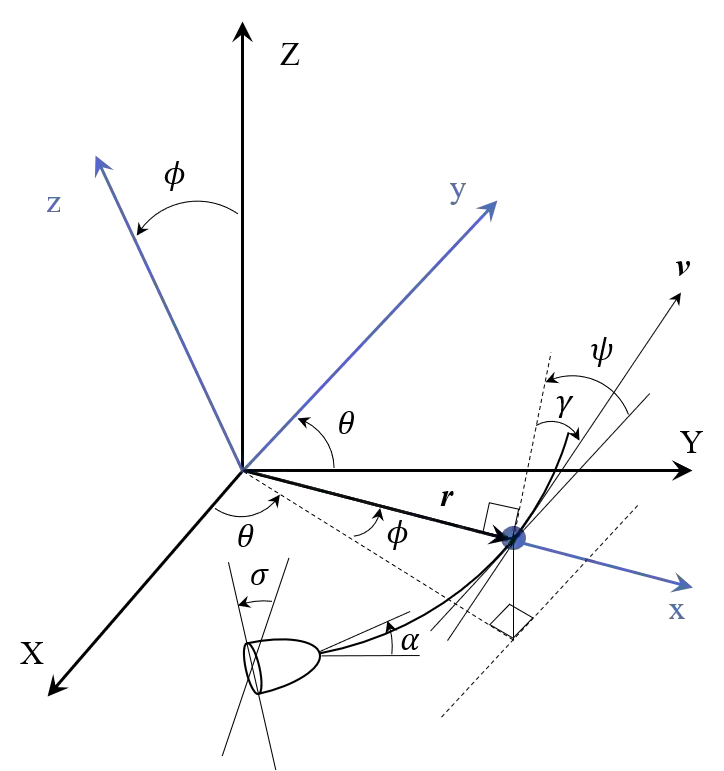
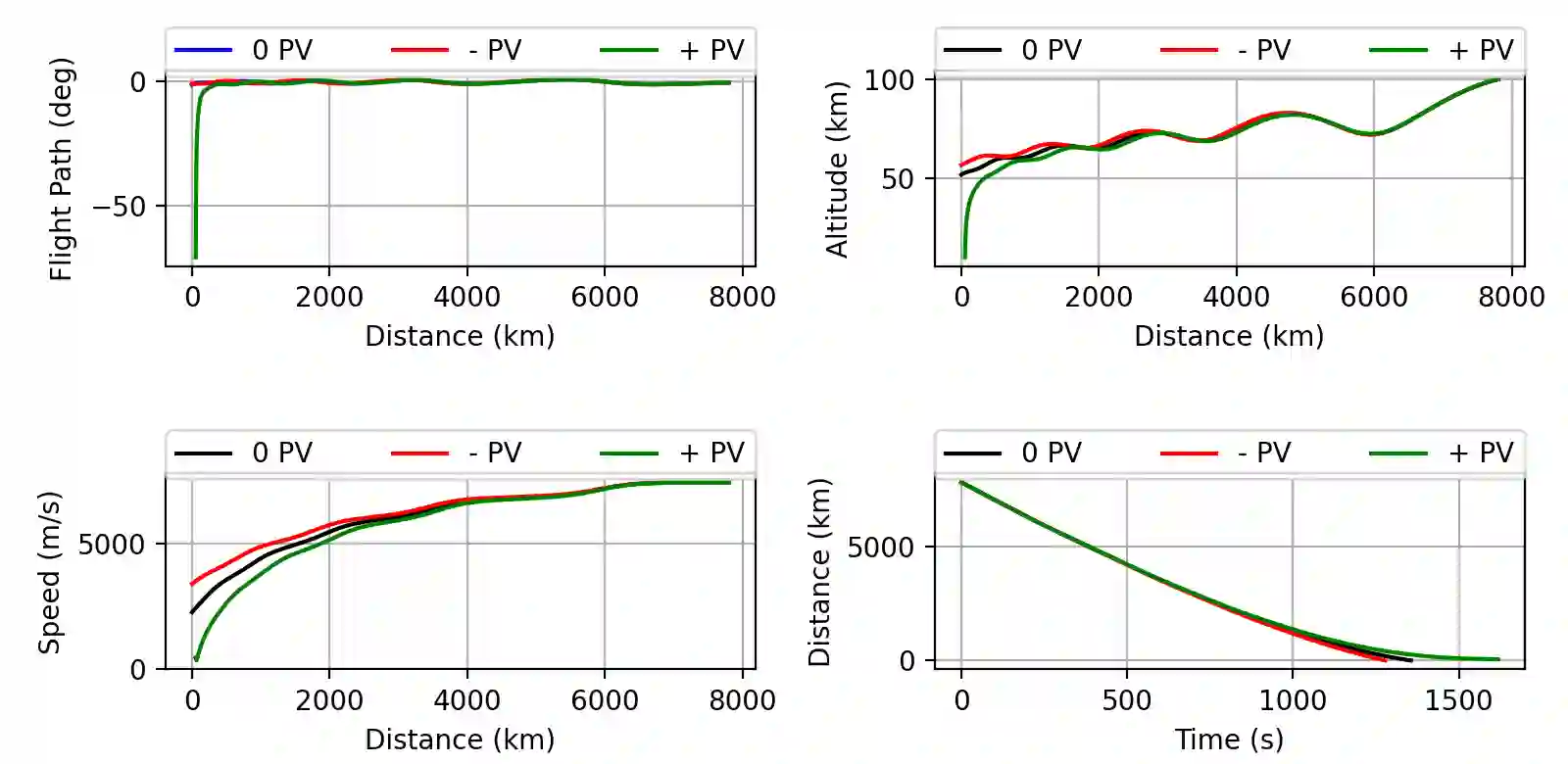
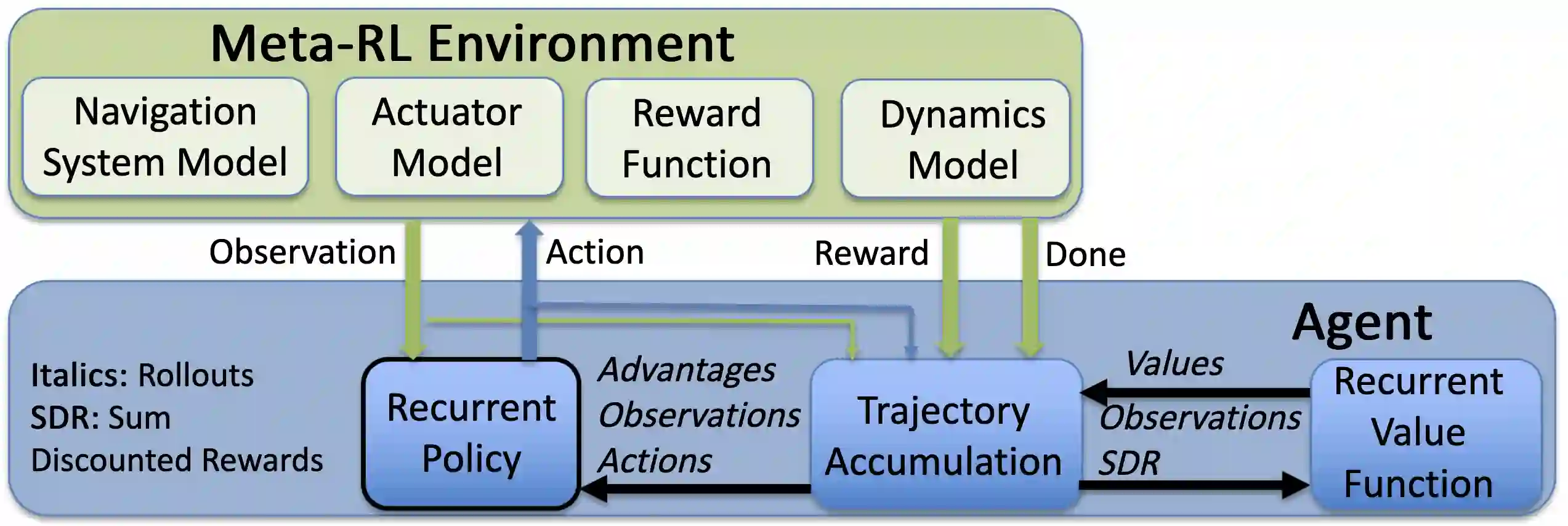
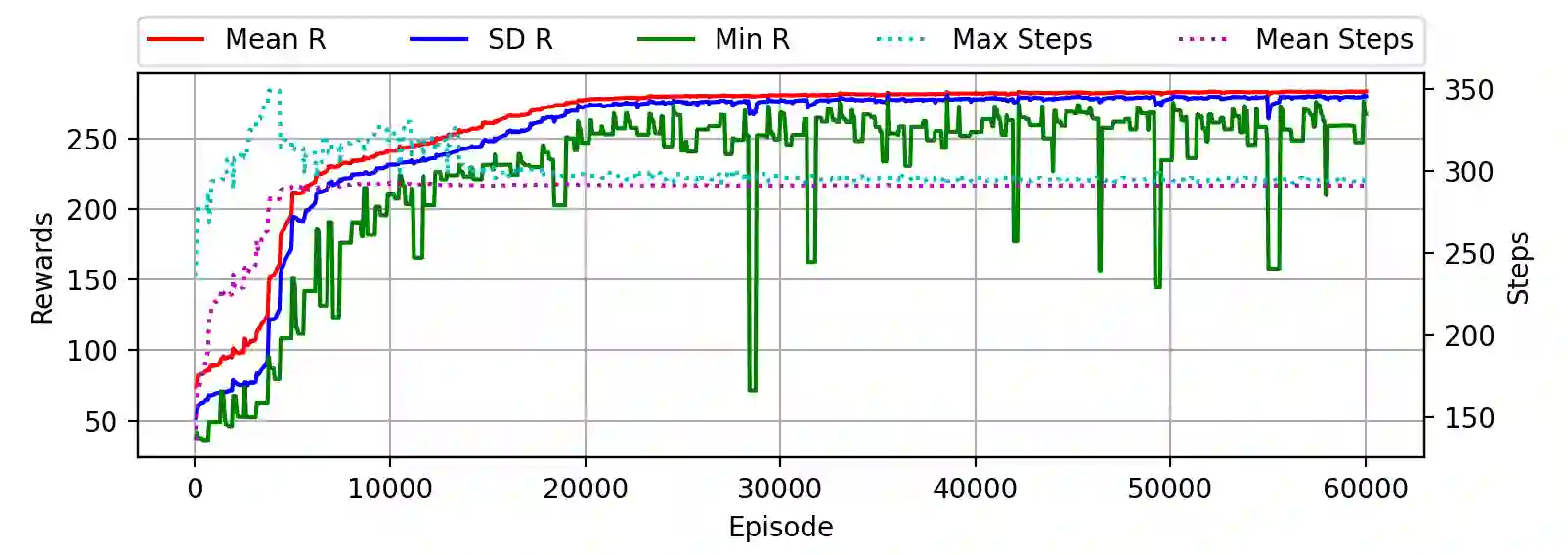
We use Reinforcement Meta Learning to optimize an adaptive guidance system suitable for the approach phase of a gliding hypersonic vehicle. Adaptability is achieved by optimizing over a range of off-nominal flight conditions including perturbation of aerodynamic coefficient parameters, actuator failure scenarios, and sensor noise. The system maps observations directly to commanded bank angle and angle of attack rates. These observations include a velocity field tracking error formulated using parallel navigation, but adapted to work over long trajectories where the Earth's curvature must be taken into account. Minimizing the tracking error keeps the curved space line of sight to the target location aligned with the vehicle's velocity vector. The optimized guidance system will then induce trajectories that bring the vehicle to the target location with a high degree of accuracy at the designated terminal speed, while satisfying heating rate, load, and dynamic pressure constraints. We demonstrate the adaptability of the guidance system by testing over flight conditions that were not experienced during optimization. The guidance system's performance is then compared to that of a linear quadratic regulator tracking an optimal trajectory.
翻译:我们使用Servite Meta Learning 优化适合滑翔超音速飞行器航程阶段的适应性指导系统。 优化一系列非常规飞行条件( 包括空气动力系数参数的扰动、 动动器故障假设情景和传感器噪音), 就可以实现适应性。 系统将观测直接映射到岸边角和攻击速率角。 这些观测包括使用平行导航制成的速率场跟踪错误, 但适应于长轨轨道, 其中地球的曲线必须加以考虑。 最大限度地减少跟踪错误, 使曲线空间视线与目标位置保持与飞行器的速度矢量一致。 优化的指导系统随后将引导轨迹, 以指定的终点高度精确地将飞行器带到目标位置, 同时满足供热率、 负荷和动态压力限制。 我们通过测试优化过程中没有经历的飞行条件来显示导航系统的适应性能。 然后将导航系统的性能与跟踪最佳轨迹的线形四极调节器的性能进行比较。