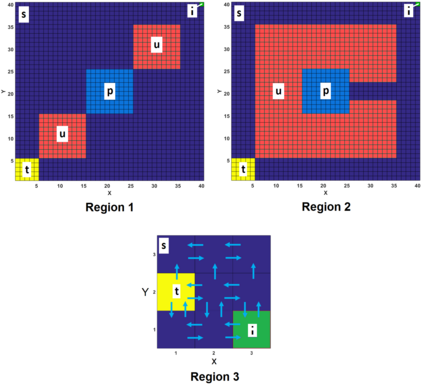
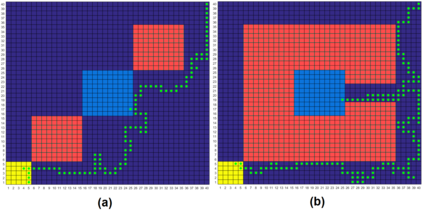
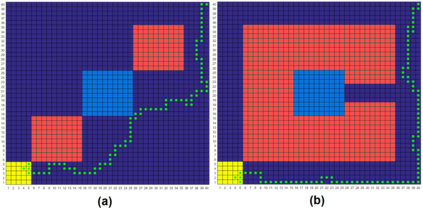
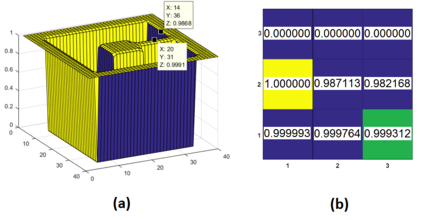
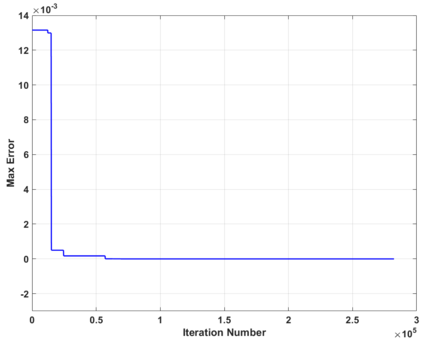
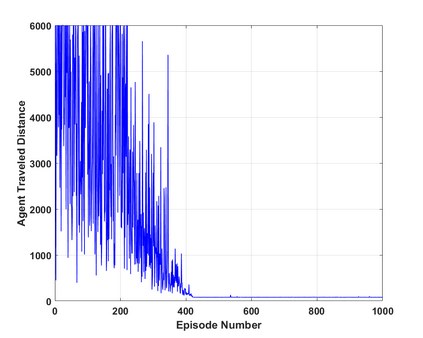
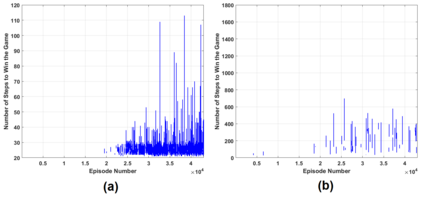
This paper proposes a model-free Reinforcement Learning (RL) algorithm to synthesise policies for an unknown Markov Decision Process (MDP), such that a linear time property is satisfied. We convert the given property into a Limit Deterministic Buchi Automaton (LDBA), then construct a synchronized MDP between the automaton and the original MDP. According to the resulting LDBA, a reward function is then defined over the state-action pairs of the product MDP. With this reward function, our algorithm synthesises a policy whose traces satisfies the linear time property: as such, the policy synthesis procedure is "constrained" by the given specification. Additionally, we show that the RL procedure sets up an online value iteration method to calculate the maximum probability of satisfying the given property, at any given state of the MDP - a convergence proof for the procedure is provided. Finally, the performance of the algorithm is evaluated via a set of numerical examples. We observe an improvement of one order of magnitude in the number of iterations required for the synthesis compared to existing approaches.
翻译:本文提出一个无模型强化学习(RL)算法,将政策合成为未知的Markov 决策程序(MDP),从而满足线性时间属性。我们将给定属性转换成一个限制决定因素 Buchi Automaton(LDBA),然后在自动地图和原始MDP之间建立一个同步的MDP。根据由此产生的LDBA,然后对产品MDP的州-行动对进行奖赏功能定义。有了这一奖励功能,我们的算法合成了一个政策,其痕迹满足线性时间属性:因此,政策综合程序受到特定规格的“制约 ” 。此外,我们显示,RL程序设置了一个在线价值迭代法,用以计算在任何给定状态满足给定属性的最大概率,即提供程序趋同证据。最后,对算法的性能通过一组数字实例进行评估。我们观察到,与现有方法相比,合成所需的迭代数数量有一定的大小。