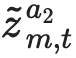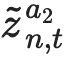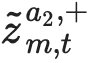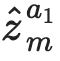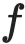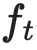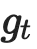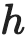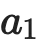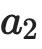Learning from large amounts of unsupervised data and a small amount of supervision is an important open problem in computer vision. We propose a new semi-supervised learning method, Semantic Positives via Pseudo-Labels (SemPPL), that combines labelled and unlabelled data to learn informative representations. Our method extends self-supervised contrastive learning -- where representations are shaped by distinguishing whether two samples represent the same underlying datum (positives) or not (negatives) -- with a novel approach to selecting positives. To enrich the set of positives, we leverage the few existing ground-truth labels to predict the missing ones through a $k$-nearest neighbours classifier by using the learned embeddings of the labelled data. We thus extend the set of positives with datapoints having the same pseudo-label and call these semantic positives. We jointly learn the representation and predict bootstrapped pseudo-labels. This creates a reinforcing cycle. Strong initial representations enable better pseudo-label predictions which then improve the selection of semantic positives and lead to even better representations. SemPPL outperforms competing semi-supervised methods setting new state-of-the-art performance of $68.5\%$ and $76\%$ top-$1$ accuracy when using a ResNet-$50$ and training on $1\%$ and $10\%$ of labels on ImageNet, respectively. Furthermore, when using selective kernels, SemPPL significantly outperforms previous state-of-the-art achieving $72.3\%$ and $78.3\%$ top-$1$ accuracy on ImageNet with $1\%$ and $10\%$ labels, respectively, which improves absolute $+7.8\%$ and $+6.2\%$ over previous work. SemPPL also exhibits state-of-the-art performance over larger ResNet models as well as strong robustness, out-of-distribution and transfer performance.
翻译:从大量未经监督的数据中学习,还有少量监管,这是计算机愿景中一个重要的开放问题。我们提出一个新的半监督的学习方法,即通过 Pseudo-label (SemPPL) 将贴标签和未贴标签的数据结合起来,以了解信息演示。我们的方法扩展了自我监督的对比学习 -- -- 通过区分两个样本是否代表相同的基本数据(正数)或不是(负数)来形成对比 -- -- 采用新颖的方法来选择正数。为了丰富正数组,我们利用少数现有的地价标签,通过用美元最接近的邻居分类(Semeudo-label) 来预测缺失的。我们的方法是扩展自监督的对比学习 -- -- 我们通过区分两个样本是否代表了相同的基数(正数) 而不是(负数) -- -- 负数 -- -- 来选择正数美元。为了丰富正数,我们提出了更好的伪标签预测,然后改进了以美元为美元的平价标数。我们利用现有的基数标签标签标签标签标签的标签,通过一个美元最接近的贴值的贴值的贴值的贴现, $ $ $ $ $ 美元 美元 美元 美元 美元 美元 美元 美元,, 也用新的方法来大幅更新地改进了Sem- -- -- -- -- -- -- -- -- -- -- -- --