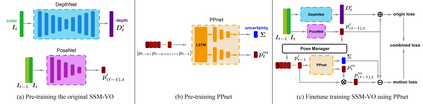
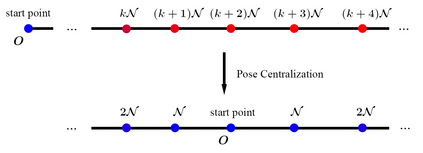
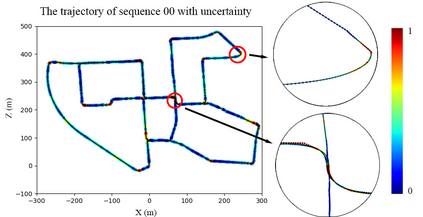
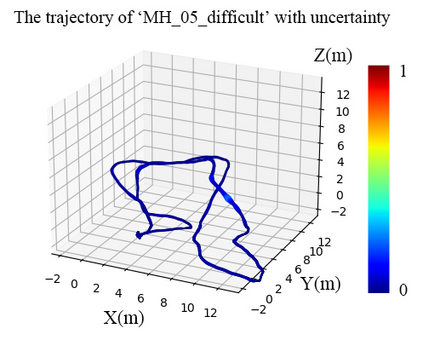
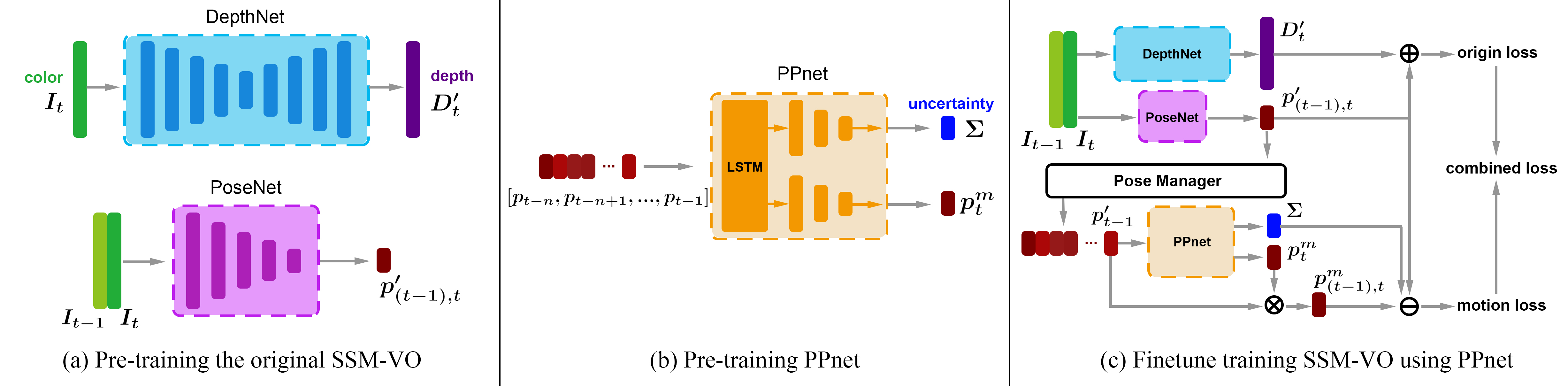
We present a novel self-supervised algorithmnamedMotionHintfor monocular visual odometry (VO) that takes motion constraints into account. A key aspect of ourapproach is to use an appropriate motion model that can help existing self-supervised monocular VO (SSM-VO) algorithms to overcome issues related to the local minima within their self-supervised loss functions. The motion model is expressed with a neural network named PPnet. It is trained to coarsely predict the next pose of the camera and the uncertainty of this prediction. Our self-supervised approach combines the original loss and the motion loss, which is the weighted difference between the prediction and the generated ego-motion. Taking two existing SSM-VO systems as our baseline, we evaluate our MotionHint algorithm on the standard KITTI and EuRoC benchmark. Experimental results show that our MotionHint algorithm can be easily applied to existing open-source state-of-the-art SSM-VO systems to greatly improve the performance on KITTI dataset by reducing the resulting ATE by up to 28.73%. For EuRoc dataset, our method can extract the motion model.But due to the poor performance of the baseline methods, MotionHint cannot significantly improve their results.
翻译:我们展示了一种新的自我监督的算法(motionHint),用于单眼视觉测量(VO),它考虑到运动限制因素。我们的方法的一个重要方面是使用适当的运动模型,帮助现有自我监督的单眼VO(SSM-VO)算法(SSSM-VO),以克服在自我监督的损失功能范围内与当地微型算法有关的问题。这个运动模型以名为 PPnet 的神经网络来表达。它受过训练,可以粗略地预测相机的下一个形状和这一预测的不确定性。我们自我监督的方法将原来的损失和运动损失结合起来,这就是预测和产生的自我提升之间的加权差异。用现有的两种SSSMM-VO(SS-V)算法作为我们的基线,我们用标准 KITTI 和 EuRoC 基准来评估我们的移动算法。实验结果显示,我们的移动Hint算法可以很容易地应用到现有的开放源状态的SSSSMMO-V系统,从而大大改进KITTI数据设置的性能,通过28.73%的移动来降低模型结果。