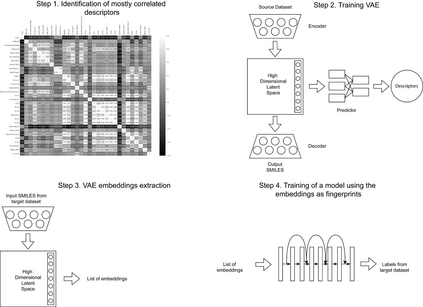
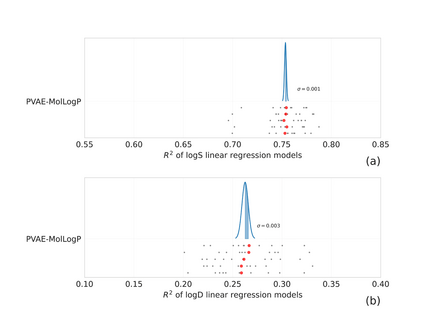
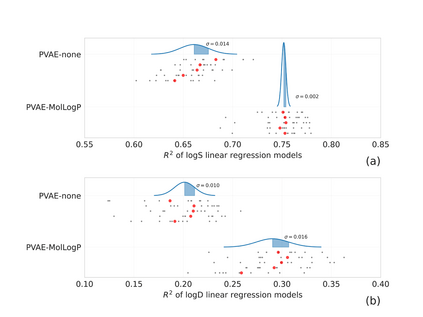
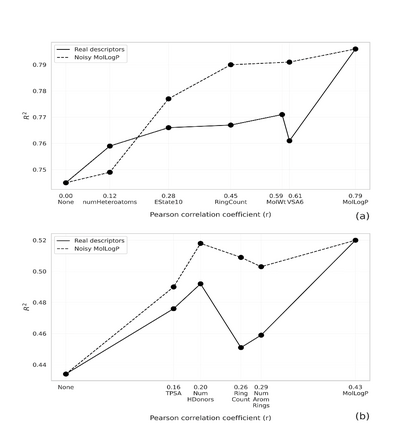
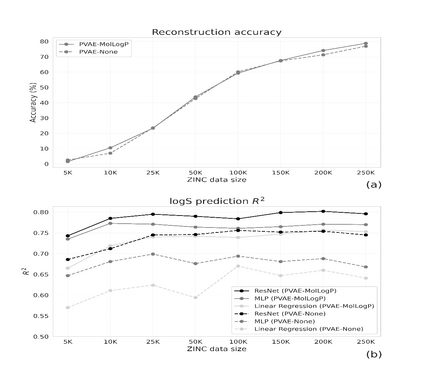
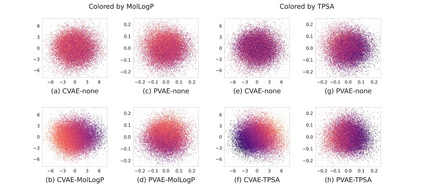
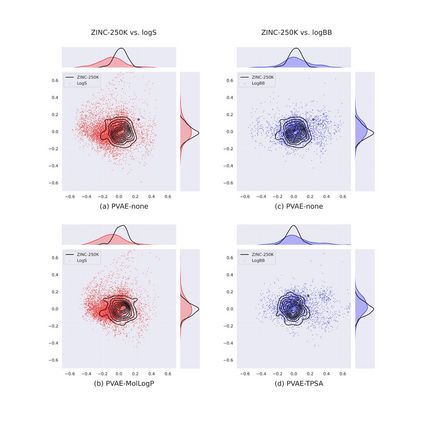
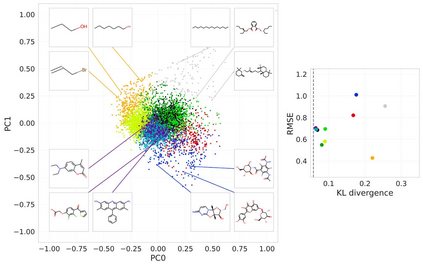
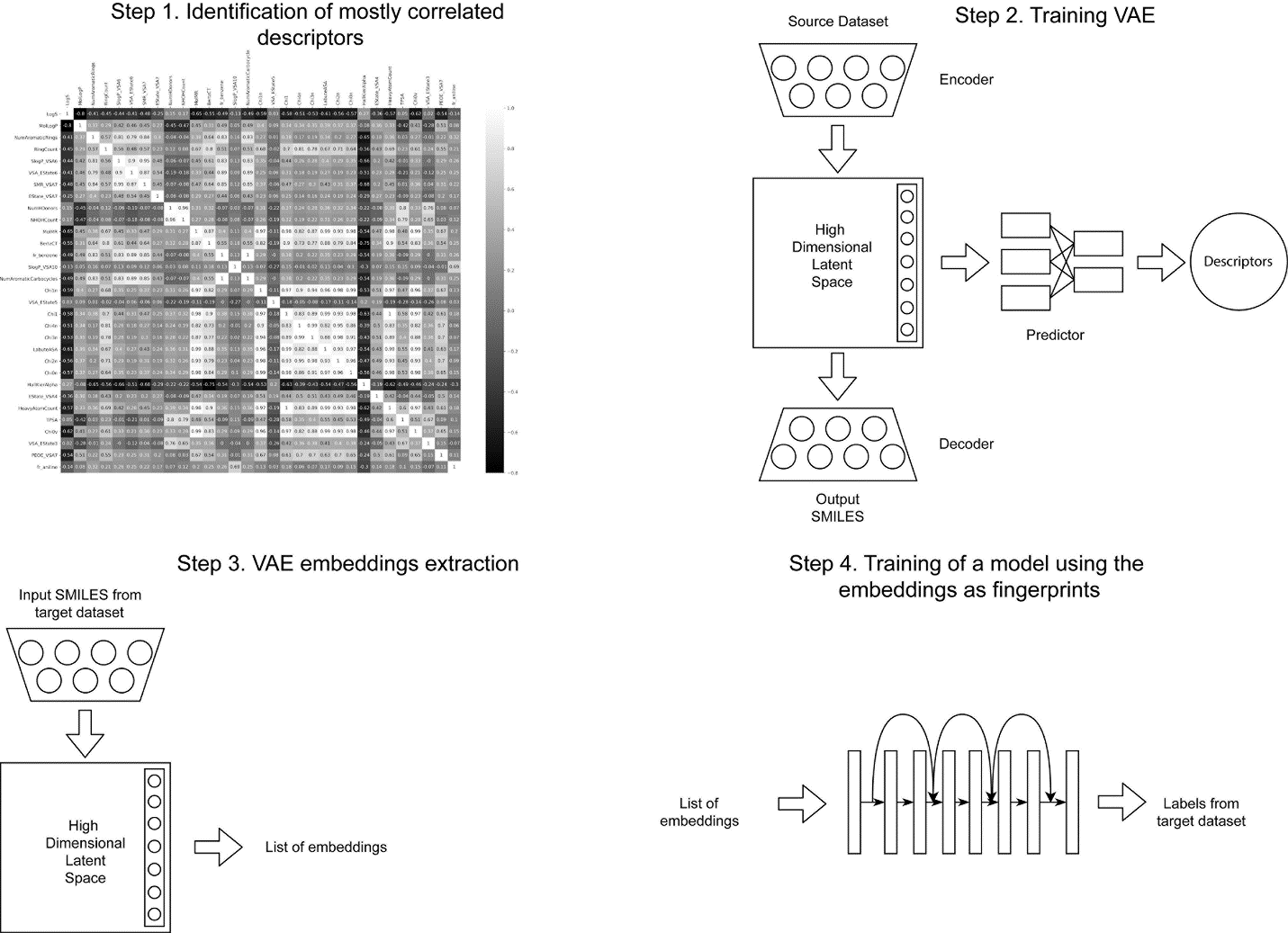
Collecting labeled data for many important tasks in chemoinformatics is time consuming and requires expensive experiments. In recent years, machine learning has been used to learn rich representations of molecules using large scale unlabeled molecular datasets and transfer the knowledge to solve the more challenging tasks with limited datasets. Variational autoencoders are one of the tools that have been proposed to perform the transfer for both chemical property prediction and molecular generation tasks. In this work we propose a simple method to improve chemical property prediction performance of machine learning models by incorporating additional information on correlated molecular descriptors in the representations learned by variational autoencoders. We verify the method on three property prediction asks. We explore the impact of the number of incorporated descriptors, correlation between the descriptors and the target properties, sizes of the datasets etc. Finally, we show the relation between the performance of property prediction models and the distance between property prediction dataset and the larger unlabeled dataset in the representation space.
翻译:收集化学信息学中许多重要任务的标签数据需要时间,需要花费昂贵的实验。近年来,机器学习被用来利用大型无标签分子数据集学习分子的丰富表现,并传授知识,以有限数据集解决更具挑战性的任务。变式自动编码器是建议用于化学财产预测和分子生成任务转让的工具之一。在这项工作中,我们提出了一个简单的方法,通过将相关分子描述器的更多信息纳入变式自动编码器所学的演示中来改进机器学习模型的化学财产预测性能。我们核实了三种属性预测要求的方法。我们探讨了集成描述器的数量、描述器与目标属性、数据集大小等的相关性。最后,我们展示了属性预测模型的性能与属性预测数据集与代表空间内较大无标签数据集之间的距离之间的关系。