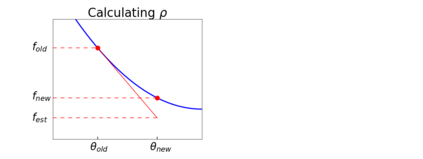
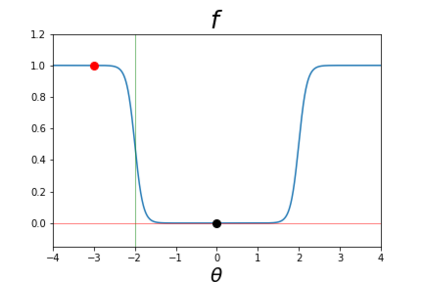
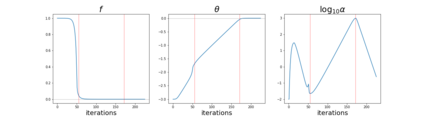
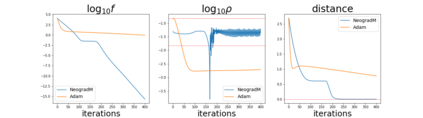
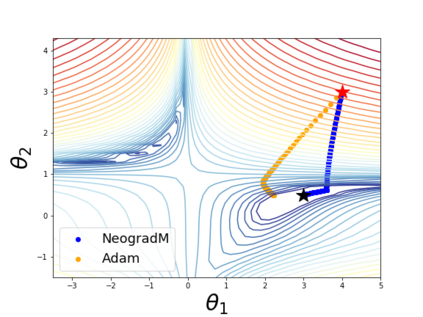
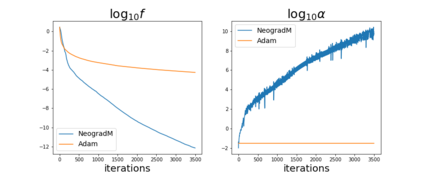
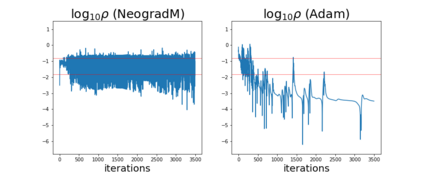
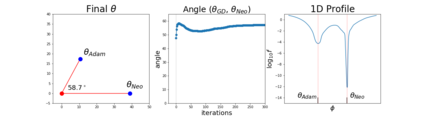
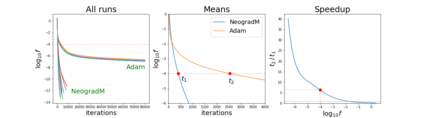
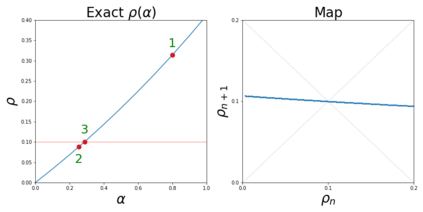
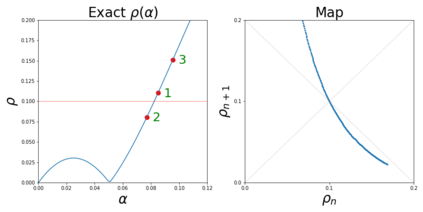
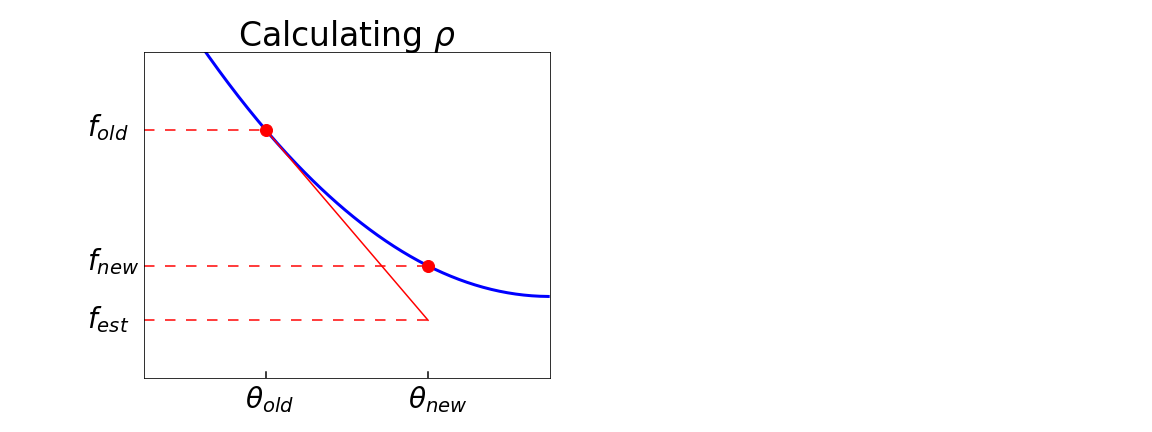
The purpose of this paper is to improve upon existing variants of gradient descent by solving two problems: (1) removing (or reducing) the plateau that occurs while minimizing the cost function,(2) continually adjusting the learning rate to an "ideal" value. The approach taken is to approximately solve for the learning rate as a function of a trust metric. When this technique is hybridized with momentum, it creates an especially effective gradient descent variant, called NeogradM. It is shown to outperform Adam on several test problems, and can easily reach cost function values that are smaller by a factor of $10^8$.
翻译:本文的目的是通过解决两个问题改进现有的梯度下降变种,即:(1) 消除(或减少)在尽量减少成本功能时出现的高原,(2) 不断将学习率调整为“理想”值,采取的方法是大致解决学习率作为信任度值的函数,在这种技术与势头相结合时,创造一种特别有效的梯度下降变种,称为NeogradM。 事实证明,它在若干测试问题上优于Adam,很容易达到成本函数值,小于10美元。