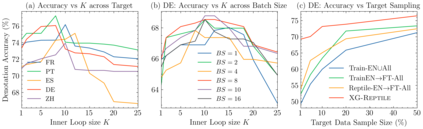
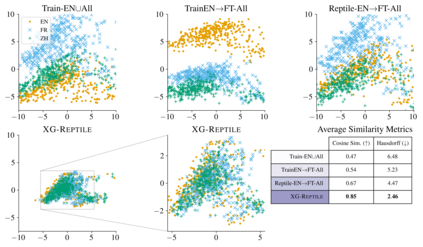
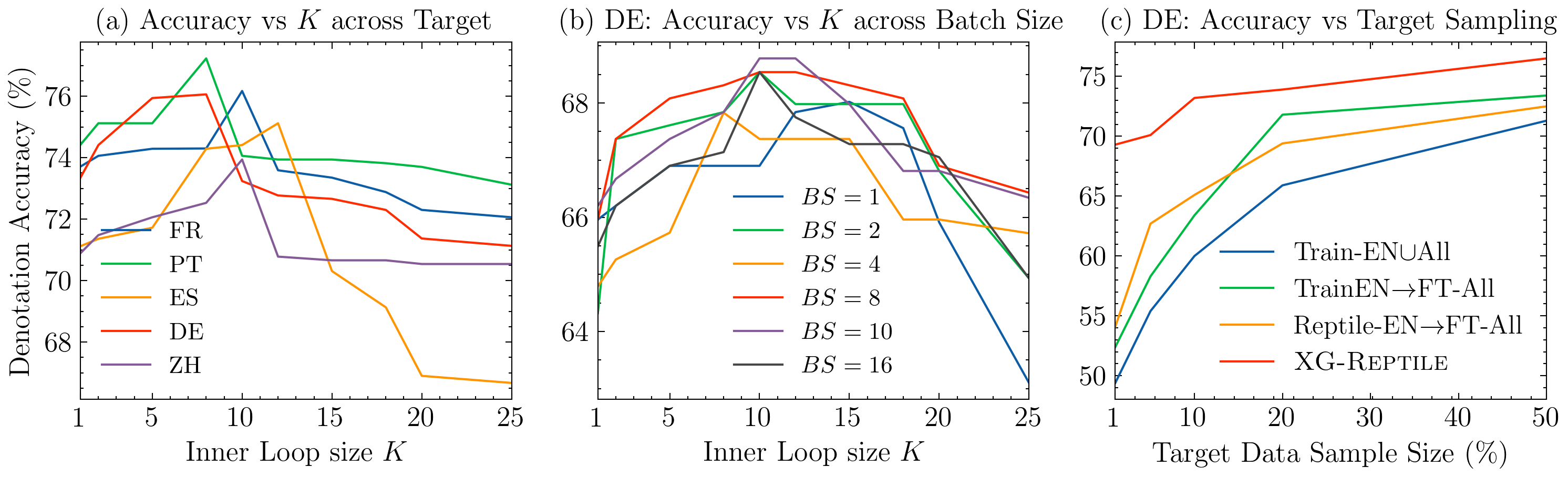
Localizing a semantic parser to support new languages requires effective cross-lingual generalization. Recent work has found success with machine-translation or zero-shot methods although these approaches can struggle to model how native speakers ask questions. We consider how to effectively leverage minimal annotated examples in new languages for few-shot cross-lingual semantic parsing. We introduce a first-order meta-learning algorithm to train a semantic parser with maximal sample efficiency during cross-lingual transfer. Our algorithm uses high-resource languages to train the parser and simultaneously optimizes for cross-lingual generalization for lower-resource languages. Results across six languages on ATIS demonstrate that our combination of generalization steps yields accurate semantic parsers sampling $\le$10% of source training data in each new language. Our approach also trains a competitive model on Spider using English with generalization to Chinese similarly sampling $\le$10% of training data.
翻译:支持新语言的语义解析器本地化需要有效的跨语种通用化。 最近的工作在机器翻译或零射法方面取得了成功,尽管这些方法可以艰难地模拟本地语使用者如何提问。 我们考虑如何有效地利用新语言中最起码的注解示例,用于微小的跨语言语义解析。 我们引入了第一级元学习算法,以在跨语言传输过程中对语义解析器进行培训,其样本效率最高。 我们的算法使用高资源语言培训剖析器,同时优化低资源语言的跨语种通用化。 亚特西语的六种语言结果表明,我们综合的语义分析步骤可以产生准确的语义分析器,对每种新语言的源培训数据进行10%的抽样。 我们的方法还开发了一种竞争性模型,用英语对中文同样地取样了10%的培训数据。