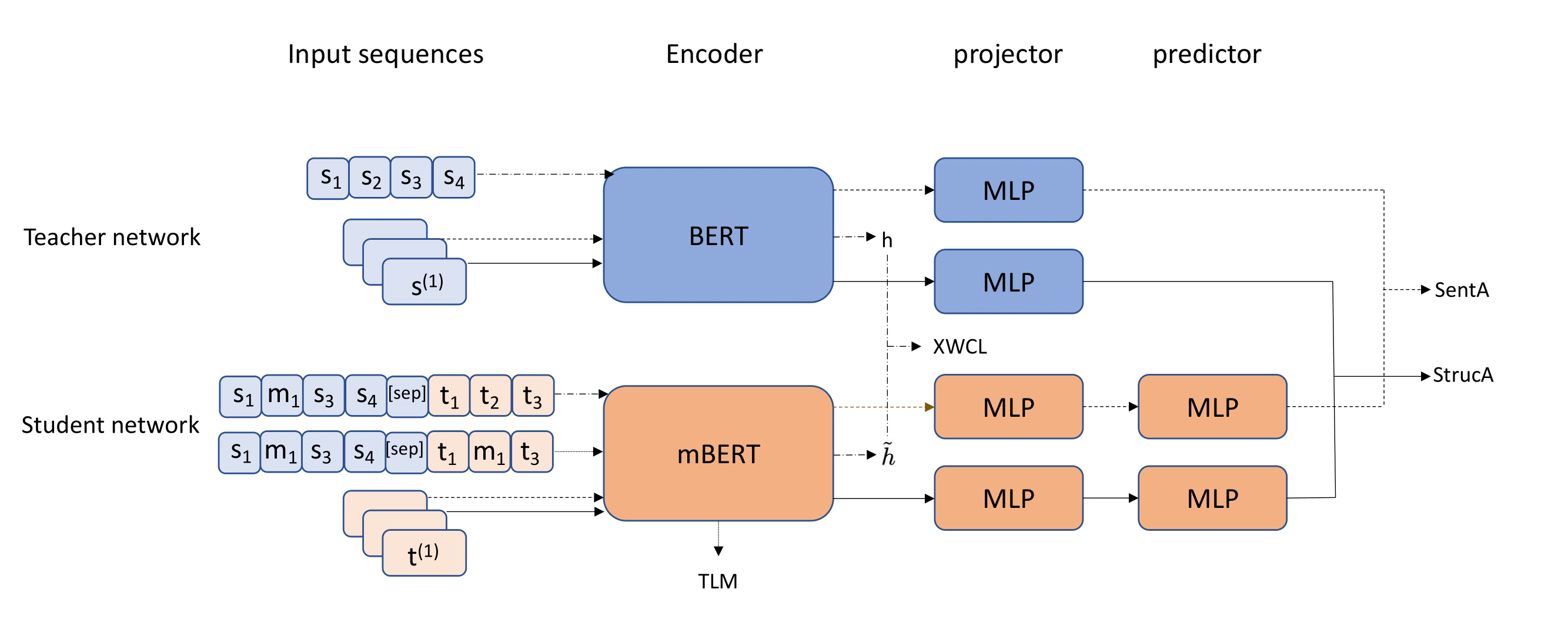
Pre-trained multilingual language models play an important role in cross-lingual natural language understanding tasks. However, existing methods did not focus on learning the semantic structure of representation, and thus could not optimize their performance. In this paper, we propose Multi-level Multilingual Knowledge Distillation (MMKD), a novel method for improving multilingual language models. Specifically, we employ a teacher-student framework to adopt rich semantic representation knowledge in English BERT. We propose token-, word-, sentence-, and structure-level alignment objectives to encourage multiple levels of consistency between source-target pairs and correlation similarity between teacher and student models. We conduct experiments on cross-lingual evaluation benchmarks including XNLI, PAWS-X, and XQuAD. Experimental results show that MMKD outperforms other baseline models of similar size on XNLI and XQuAD and obtains comparable performance on PAWS-X. Especially, MMKD obtains significant performance gains on low-resource languages.
翻译:预先培训的多语言语言模式在跨语言的自然语言理解任务中发挥着重要作用,但是,现有方法并不侧重于学习代表性的语义结构,因此无法优化其绩效。在本文件中,我们提议采用多语言多语言知识蒸馏(MMKD),这是改进多语言模式的一种新颖方法。具体地说,我们采用教师-学生框架,在英语BERT中采用丰富的语义代表知识。我们提出了象征性、单词、句子和结构层面的调整目标,以鼓励源目标对口之间多层次的一致性以及师生模式之间的相互关系。我们进行了跨语言评估基准实验,包括XNLI、PAWS-X和XQAD。实验结果表明,MKD超越了XNLI和XQUAD类似的基线模型,在PAWS-X上取得了类似的业绩。特别是MKD在低资源语言上取得了显著的业绩收益。