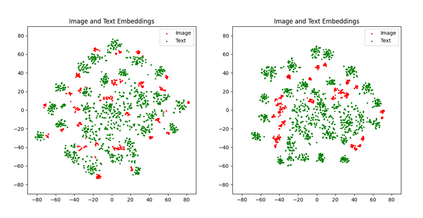
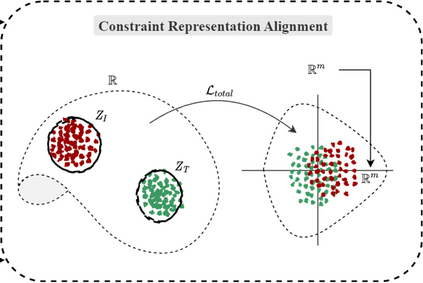
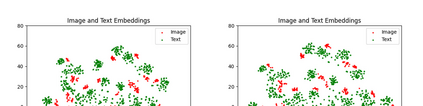
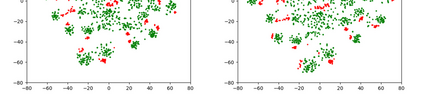
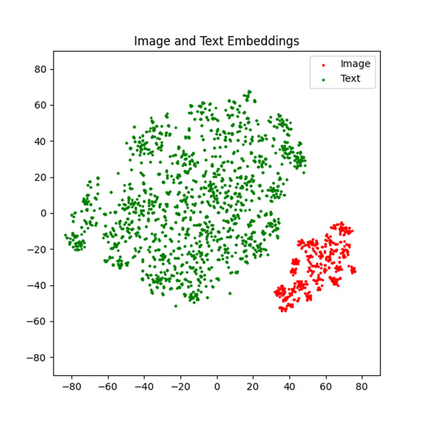
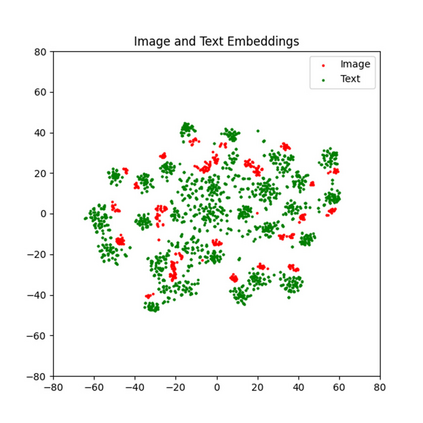
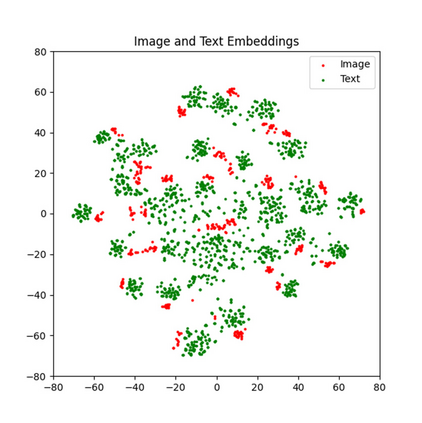
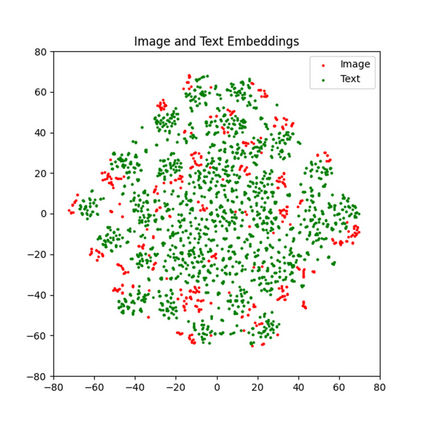
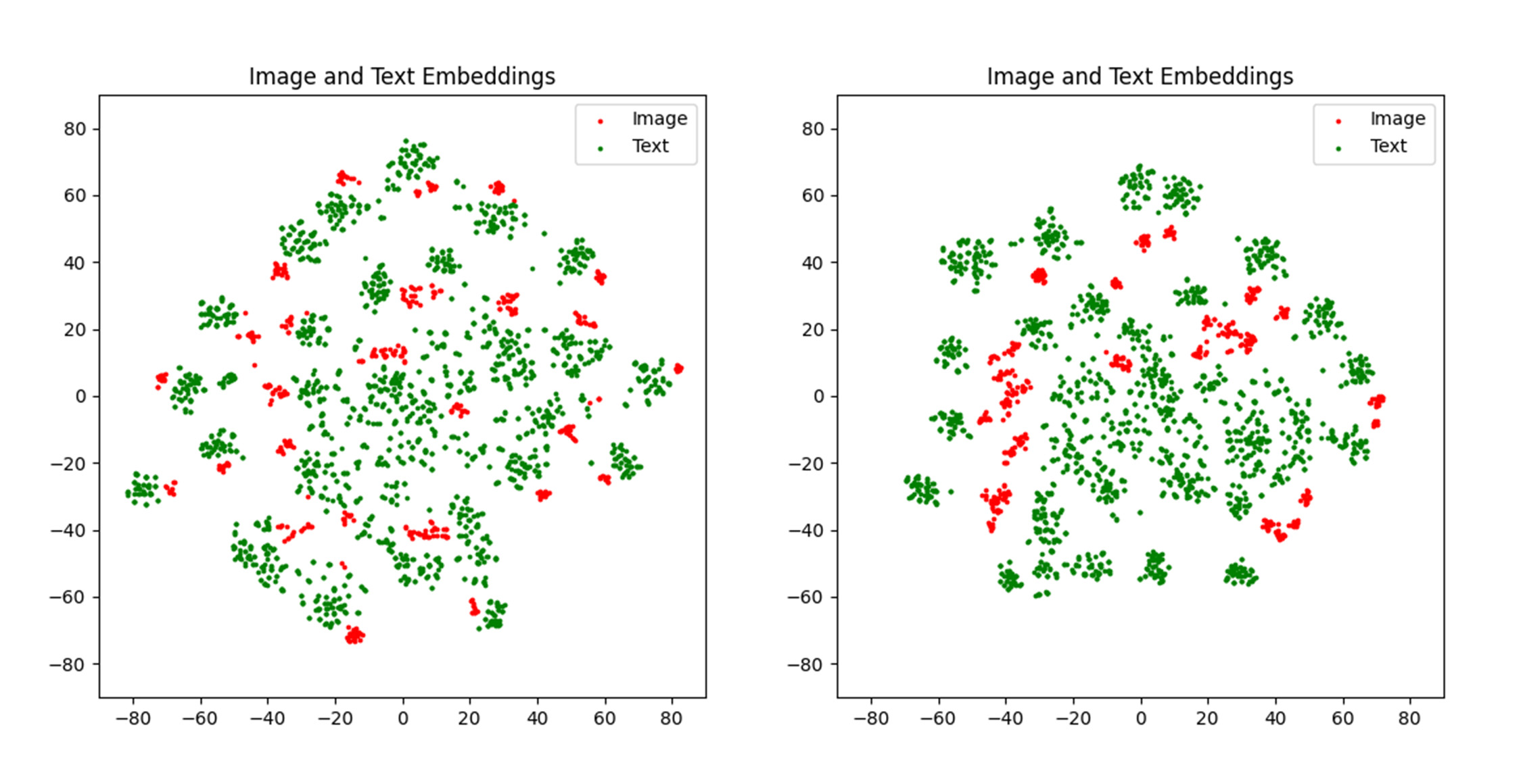
With the rise of Visual and Language Pretraining (VLP), an increasing number of downstream tasks are adopting the paradigm of pretraining followed by fine-tuning. Although this paradigm has demonstrated potential in various multimodal downstream tasks, its implementation in the remote sensing domain encounters some obstacles. Specifically, the tendency for same-modality embeddings to cluster together impedes efficient transfer learning. To tackle this issue, we review the aim of multimodal transfer learning for downstream tasks from a unified perspective, and rethink the optimization process based on three distinct objectives. We propose "Harmonized Transfer Learning and Modality Alignment (HarMA)", a method that simultaneously satisfies task constraints, modality alignment, and single-modality uniform alignment, while minimizing training overhead through parameter-efficient fine-tuning. Remarkably, without the need for external data for training, HarMA achieves state-of-the-art performance in two popular multimodal retrieval tasks in the field of remote sensing. Our experiments reveal that HarMA achieves competitive and even superior performance to fully fine-tuned models with only minimal adjustable parameters. Due to its simplicity, HarMA can be integrated into almost all existing multimodal pretraining models. We hope this method can facilitate the efficient application of large models to a wide range of downstream tasks while significantly reducing the resource consumption. Code is available at https://github.com/seekerhuang/HarMA.
翻译:暂无翻译