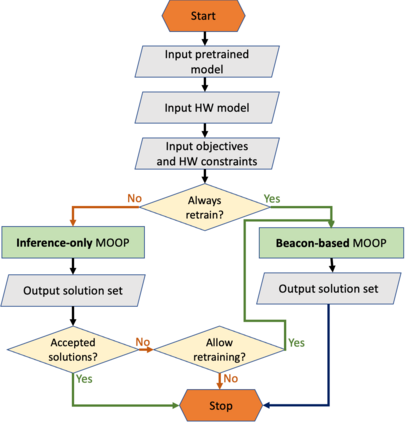
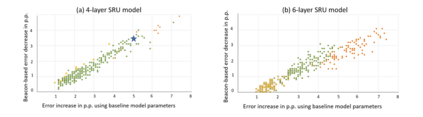
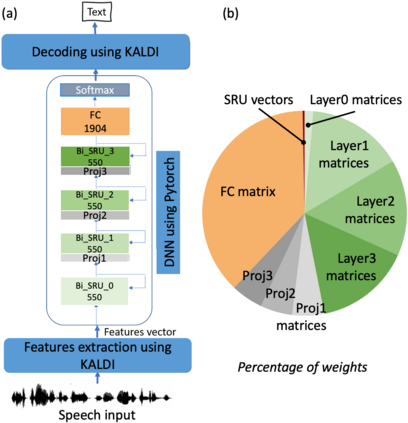
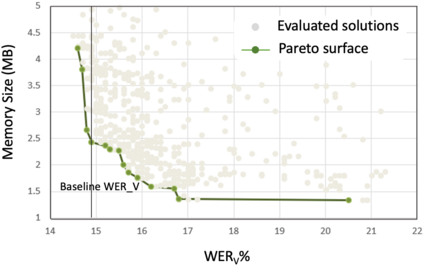
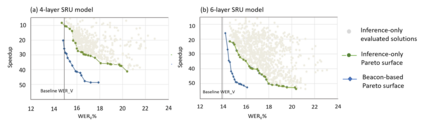
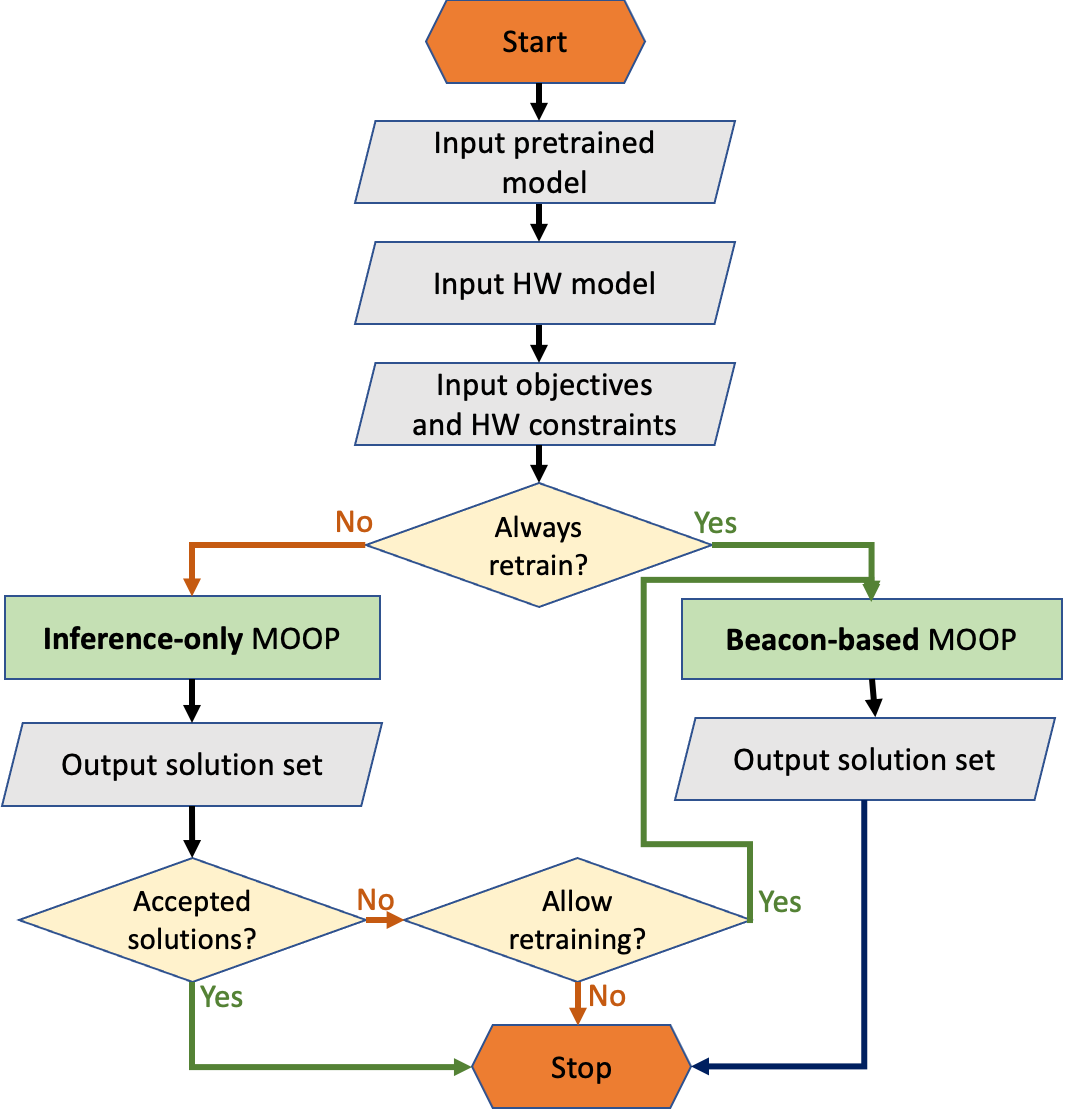
The compression of deep learning models is of fundamental importance in deploying such models to edge devices. The selection of compression parameters can be automated to meet changes in the hardware platform and application using optimization algorithms. This article introduces a Multi-Objective Hardware-Aware Quantization (MOHAQ) method, which considers hardware efficiency and inference error as objectives for mixed-precision quantization. The proposed method feasibly evaluates candidate solutions in a large search space by relying on two steps. First, post-training quantization is applied for fast solution evaluation (inference-only search). Second, we propose the "beacon-based search" to retrain selected solutions only and use them as beacons to know the effect of retraining on other solutions. We use a speech recognition model based on Simple Recurrent Unit (SRU) using the TIMIT dataset and apply our method to run on SiLago and Bitfusion platforms. We provide experimental evaluations showing that SRU can be compressed up to 8x by post-training quantization without any significant error increase. On SiLago, we found solutions that achieve 97\% and 86\% of the maximum possible speedup and energy saving, with a minor increase in error. On Bitfusion, beacon-based search reduced the error gain of inference-only search by up to 4.9 percentage points.
翻译:压缩深层次学习模型对于将此类模型应用到边缘设备至关重要。 压缩参数的选择可以自动化, 以适应硬件平台和应用程序使用优化算法的变化。 文章采用了多目标硬件软件软件量化( MOHAQ) 方法, 将硬件效率和推断错误视为混合精度分化的目标。 拟议的方法可以依靠两个步骤在大型搜索空间对候选解决方案进行实际评估。 首先, 培训后量化应用到快速解决方案评估( 仅进行 仅进行 简单搜索 ) 。 其次, 我们建议“ 以 Beacon 为基础搜索”, 仅对选定的解决方案进行再培训, 并将其作为灯塔, 以了解再培训对其它解决方案的影响。 我们使用基于简单常规单元( SRU) 的语音识别模型, 并使用我们的方法在 SiLago 和 Bituncult 平台上运行。 我们提供的实验性评估表明, 通过培训后量化量化可压缩到 8x, 而不增加任何重大错误 。 在 SiLago, 我们找到了一些解决方案, 以 以 将 降级搜索速度递增到 Basil 速度 和 86 递增 至 中 中 最大化 。