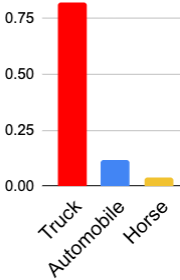
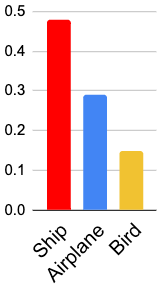
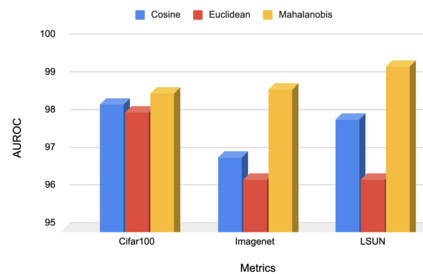
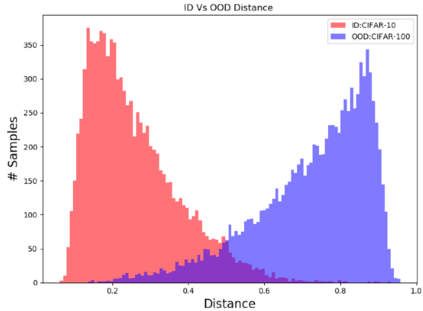
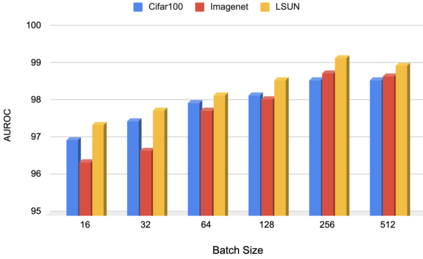
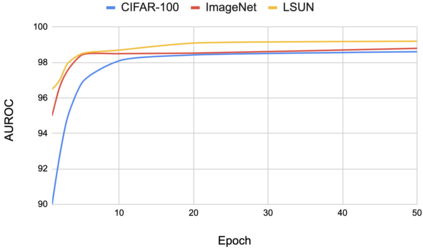
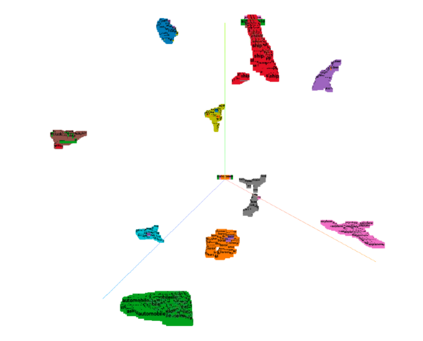
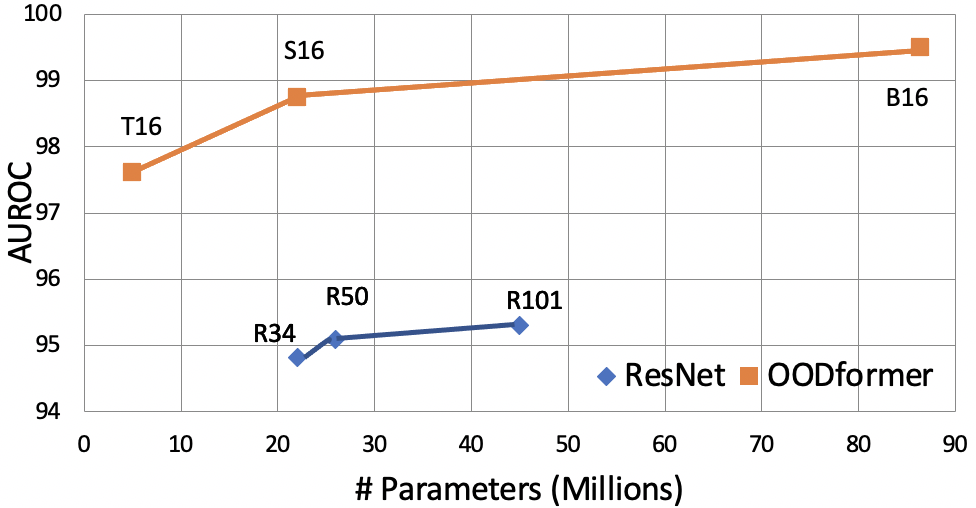
A serious problem in image classification is that a trained model might perform well for input data that originates from the same distribution as the data available for model training, but performs much worse for out-of-distribution (OOD) samples. In real-world safety-critical applications, in particular, it is important to be aware if a new data point is OOD. To date, OOD detection is typically addressed using either confidence scores, auto-encoder based reconstruction, or by contrastive learning. However, the global image context has not yet been explored to discriminate the non-local objectness between in-distribution and OOD samples. This paper proposes a first-of-its-kind OOD detection architecture named OODformer that leverages the contextualization capabilities of the transformer. Incorporating the trans\-former as the principal feature extractor allows us to exploit the object concepts and their discriminate attributes along with their co-occurrence via visual attention. Using the contextualised embedding, we demonstrate OOD detection using both class-conditioned latent space similarity and a network confidence score. Our approach shows improved generalizability across various datasets. We have achieved a new state-of-the-art result on CIFAR-10/-100 and ImageNet30.
翻译:在图像分类方面,一个严重问题是,经过培训的模型在输入数据方面可能效果良好,这种输入数据与模型培训的现有数据分布相同,但对于分配之外的样本来说则要差得多。在现实世界的安全关键应用中,尤其重要的是要了解是否有一个新的数据点是OOOD。迄今为止,OOOD的检测通常使用信心分数、基于自动编码器的重建或对比性学习来解决。然而,全球图像背景尚未被探索以区分分布和 OOOOD 样本之间的非局部对象。本文提出了名为OOODDD的首个实物OOODD检测结构,该结构利用变异器的背景能力。将变异器作为主要特征提取器,使我们能够利用物体的概念及其区别特性,同时通过视觉关注这些概念的共变异作用。我们利用了背景化嵌入式的嵌入,我们用等级固定的潜在空间和网络信任得分来演示OOOOD的检测。我们的方法显示各种数据集成型的通用性。我们已经在各种变异器上取得了新的图像-R10和CRAAR-CAR-CAR-CAR-CAR-CAR-CAR-CAR-CAR-CAR-CAR-CAR-C-C-CAR-CAR-CAR-CAR-C-C-C-CAR-C-CAR-CAR-CAR-CAR-CAR-CAR-CAR-CAR-CAR-CAR-CAR-CAR-CAR-CAR-C-CAR-CAR-C-CAR-CAR-C-C-C-C-CAR-C-C-C-CAR-CAR-CAR-CAR-CAR-C-C-C-C-CAR-CAR-C-CAR-CAR-C-C-C-C-C-C-C-C-C-C-C-C-C-C-C-C-C-C-C-CAR-C-CAR-C-C-C-C-C-C-C-C-CAR-C-C-C-CAR-CAR-CAR-CAR-C-C-C-CAR-C-C-C-