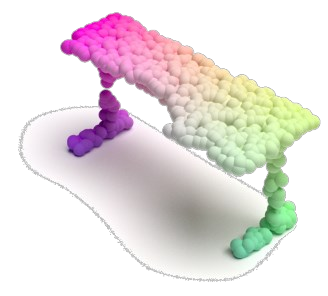
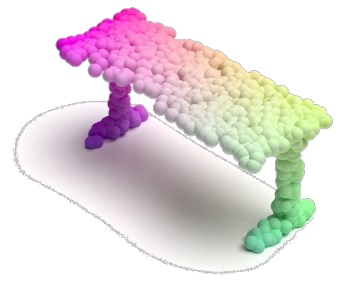
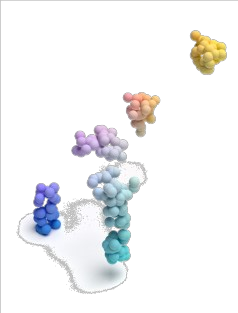
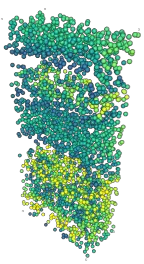
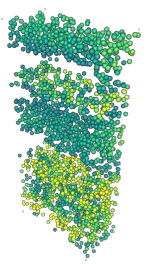
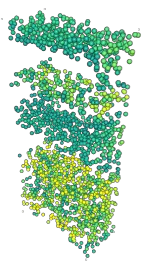
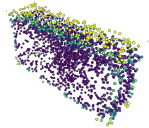
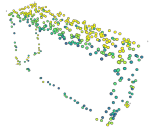
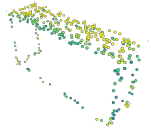
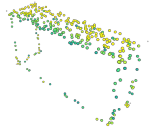
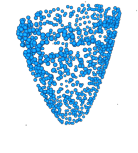
Masked autoencoding has achieved great success for self-supervised learning in the image and language domains. However, mask based pretraining has yet to show benefits for point cloud understanding, likely due to standard backbones like PointNet being unable to properly handle the training versus testing distribution mismatch introduced by masking during training. In this paper, we bridge this gap by proposing a discriminative mask pretraining Transformer framework, MaskPoint}, for point clouds. Our key idea is to represent the point cloud as discrete occupancy values (1 if part of the point cloud; 0 if not), and perform simple binary classification between masked object points and sampled noise points as the proxy task. In this way, our approach is robust to the point sampling variance in point clouds, and facilitates learning rich representations. We evaluate our pretrained models across several downstream tasks, including 3D shape classification, segmentation, and real-word object detection, and demonstrate state-of-the-art results while achieving a significant pretraining speedup (e.g., 4.1x on ScanNet) compared to the prior state-of-the-art Transformer baseline. Code is available at https://github.com/haotian-liu/MaskPoint.
翻译:蒙面自动编码在图像和语言领域的自我监督学习中取得了巨大成功。 但是,基于遮面的预设培训尚未显示点云理解的好处, 这可能是因为PointNet等标准主干柱无法正确处理培训与培训期间蒙面带来的测试分布不匹配。 在本文中, 我们通过提议一个带有歧视性的蒙面前训练变形器框架( MaskPoint} ) 来弥补这一差距。 我们的关键想法是代表点云作为离散占用值( 如果是点云的一部分的话是1; 如果不是0), 并且对遮面对象点和抽样噪声点进行简单的二进化分类作为代理任务。 这样, 我们的方法是稳健地测量点云点的点位差异, 便于学习丰富的演示。 我们评估了我们经过预先训练的多个下游任务模式, 包括 3D 形状分类、 分解、 和 实言对象检测, 并展示最新技术成果, 同时实现重要的培训前速度( 如, 扫描网络上的 4.1x ) 和先前的状态变换式基准线/ 代码可在 http:// Magiuskiuskevor.