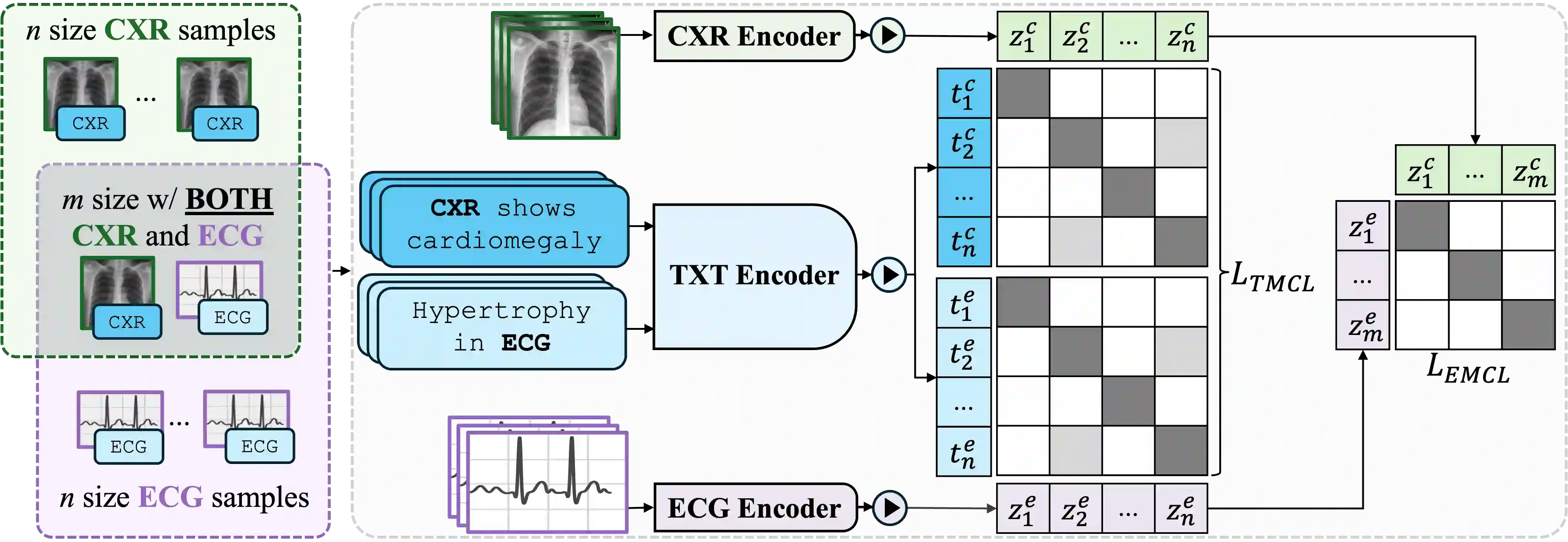
Medical vision-language pretraining models (VLPM) have achieved remarkable progress in fusing chest X-rays (CXR) with clinical texts, introducing image-text data binding approaches that enable zero-shot learning and downstream clinical tasks. However, the current landscape lacks the holistic integration of additional medical modalities, such as electrocardiograms (ECG). We present MEDBind (Medical Electronic patient recorD), which learns joint embeddings across CXR, ECG, and medical text. Using text data as the central anchor, MEDBind features tri-modality binding, delivering competitive performance in top-K retrieval, zero-shot, and few-shot benchmarks against established VLPM, and the ability for CXR-to-ECG zero-shot classification and retrieval. This seamless integration is achieved through combination of contrastive loss on modality-text pairs with our proposed contrastive loss function, Edge-Modality Contrastive Loss, fostering a cohesive embedding space for CXR, ECG, and text. Finally, we demonstrate that MEDBind can improve downstream tasks by directly integrating CXR and ECG embeddings into a large-language model for multimodal prompt tuning.
翻译:暂无翻译