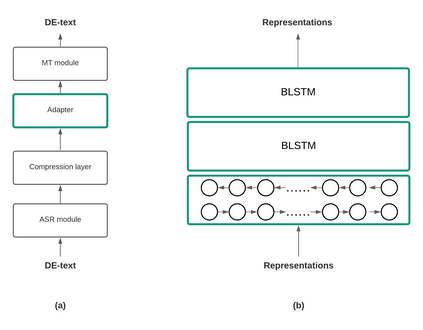
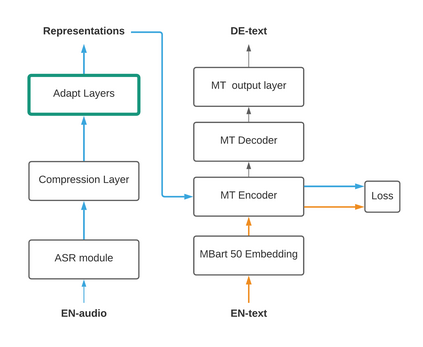
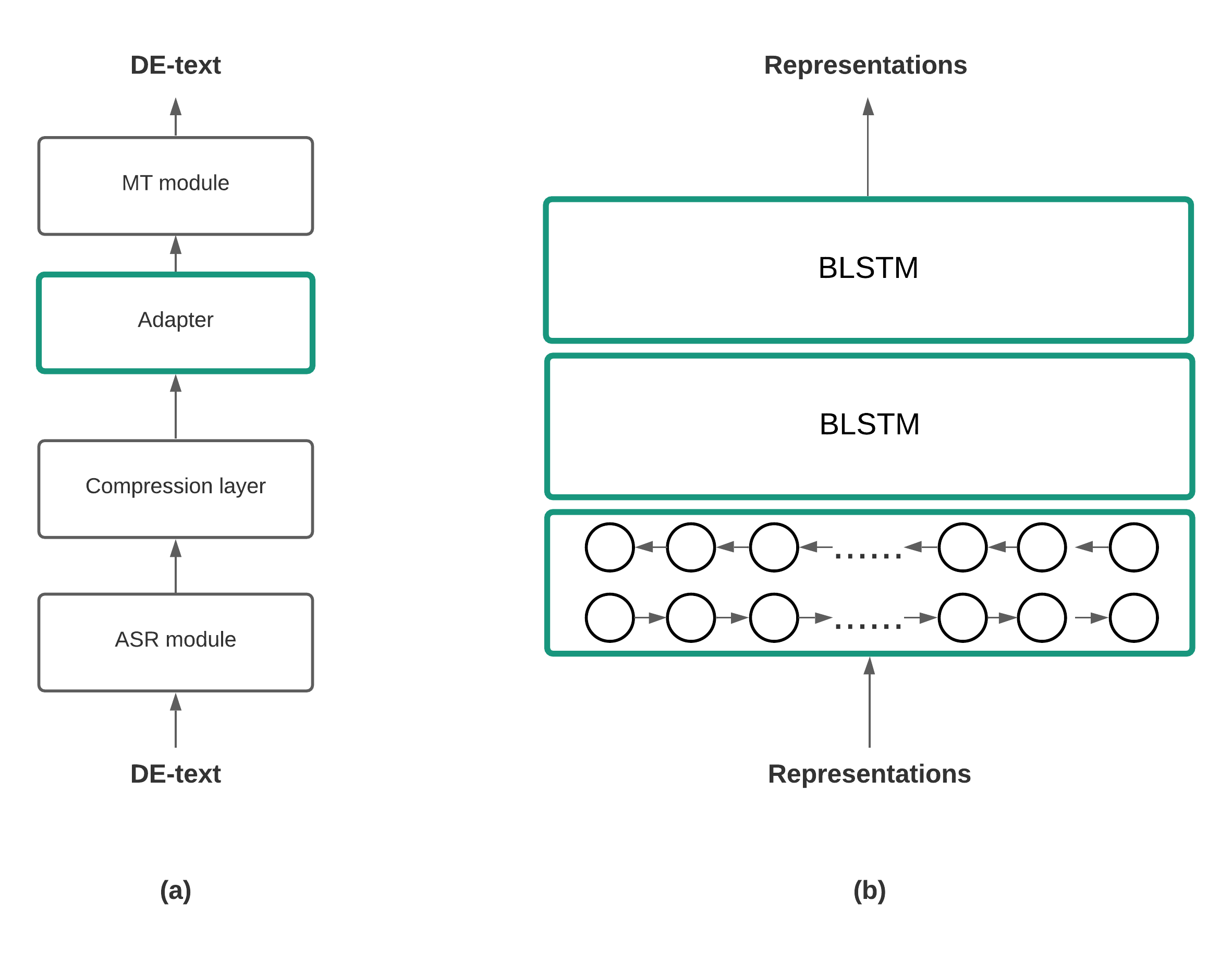
When building state-of-the-art speech translation models, the need for large computational resources is a significant obstacle due to the large training data size and complex models. The availability of pre-trained models is a promising opportunity to build strong speech translation systems efficiently. In a first step, we investigate efficient strategies to build cascaded and end-to-end speech translation systems based on pre-trained models. Using this strategy, we can train and apply the models on a single GPU. While the end-to-end models show superior translation performance to cascaded ones, the application of this technology has a limitation on the need for additional end-to-end training data. In a second step, we proposed an additional similarity loss to encourage the model to generate similar hidden representations for speech and transcript. Using this technique, we can increase the data efficiency and improve the translation quality by 6 BLEU points in scenarios with limited end-to-end training data.
翻译:在建立最先进的语音翻译模型时,由于培训数据规模大和模型复杂,需要大量计算资源是一个重大障碍。提供经过预先培训的模型是有效建立强有力的语音翻译系统的大好机会。第一步,我们调查以经过培训的模型为基础建立级联和终端至终端语音翻译系统的高效战略。使用这一战略,我们可以在单一的GPU上培训和应用这些模型。虽然端对端模型显示升级的翻译性能优于级联,但这一技术的应用限制了对额外端对端培训数据的需要。第二步,我们提议增加类似性损失,鼓励该模型为语音和笔录提供类似隐蔽的演示。使用这一技术,我们可以在终端至终端培训数据有限的情况下提高数据效率,提高翻译质量6个BLEU点。